
Kurzfassung: Der Blogbeitrag ‚Attention Collective Mind‘ adaptiert den aus der KI bekannten QKV-Attention-Mechanismus (Query, Key, Value) innovativ für soziale Systeme und das agile Team-Management. Die Teamdynamiken werden als Prozess dargestellt, bei dem eine ‚Systemtemperatur‘ die kollektive Aufmerksamkeitsverteilung regelt. Eine zu niedrige Temperatur führt demnach zu kognitiver Erstarrung (Gruppendenken), während eine zu hohe Temperatur in ‚Information Overload‘ und basisdemokratischem Chaos mündet. Das mathematische Modell berechnet unter Berücksichtigung von Arbeitslast, sozialer Reibung und einer ‚Burnout-Strafe‘ das optimale Betriebsfenster für Teams. Damit schlägt der Text eine Brücke zwischen maschinellem Lernen, statistischer Physik, der Global Workspace Theory des Bewusstseins und Management 4.0.
Dieser Blogbeitrag wurde mit Hilfe von Gemini 3 Pro erstellt! Das Bild wurde mit Gemini erstellt.
Als im Jahre 2017 das Transformer Modell ‚Attention is all you need‘ der Künstlichen Intelligenz veröffentlicht wurde [1], habe ich intuitiv die Verbindung zu unserem Transformer Modell der Kommunikation hergestellt, das wir in unserem Buch ‚Die Collective Mind Methode‘ aus dem Jahre 2009 vorgestellt haben [2]. – Jedoch war mir damals der mathematische Zusammenhang nicht bewusst: Die Erfinder des Transformer Modells verwenden in ihrem Modell eine Sprache, wie man sie aus der Datenbank-Abfrage kennt: Eine Query (zum Beispiel ein Satz, oder ein Wort) stellt eine Anfrage an ein neuronales Netzwerk. In dem neuronalen Netzwerk werden Antworten (Key’s) ermittelt, die wahrscheinlich zur Query passen. Der Key, der am wahrscheinlichsten passt, wird mit einem resultierendem (Mehr-) Wert (Value) angezeigt. Zum Beispiel könnte ein Query-Wort ‚Bank‘ lauten, ein Key-Wort könnte ‚Geld‘ lauten, dann ergäbe sich als Wert ‚Bankhaus‘ und nicht ‚Sitzbank‘, wenn die Kontexte, in dem Query und Key stehen, dies wahrscheinlicher machen. Dieser QKV Mechanismus ist die Basis des Large Language Transformers.
Ähnliches geschieht in dem Collective Mind Transformer Modell: Hier sind Query und Key zwei Gesprächspartner, die mit ihren Persönlichkeiten (Big Five, Werte, Glaubenssätzen und aktueller Stimmung) kommunizieren und je nach Kommunikationsverlauf (Kontext) einen (Mehr-) Wert erzeugen.
Query (Q), Key (K) und Value (V) werden in neuronalen Netzwerken als hochdimensionale Vektoren dargestellt. Über das Training der neuronalen Netzwerke wird der sprachliche Kontext iterativ und selbstkonsistent als Tensoren (Matrizen) aufgebaut. Der sprachliche Kontext verändert die Bedeutung von Query, Key und Value: Mathematisch ausgedrückt heißt dies, dass die QKV-Vektoren mit jeweils einer spezifischen Matrix ( ) multipliziert werden und dadurch kontextspezifische QKV-Vektoren entstehen. Die Frage, wie gut der kontextspezifische Key zur Query passt, wird über die Ähnlichkeit der beiden Vektoren beantwortet. Die Ähnlichkeit zweier Vektoren wird über deren Vektorprodukt definiert. Damit ergibt sich die Attention als Funktion, die das QK-Vektorprodukt als Wahrscheinlichkeiten ausdrückt, multipliziert mit dem (Mehr-) Wert Vektor V. Die Funktion, die Ähnlichkeiten in Wahrscheinlichkeiten umwandelt, ist die sogenannte softmax-Funktion, eine spezielle Form der Boltzmann Verteilung. – Ich verweise schon hier auf Anhang 1, in dem die Mathematik des Attention Mechanismus, angewendet auf den Collective Mind, beschrieben ist. – Später habe ich die Grundidee des Collective Mind Transformer Modells auf die Erstellung des Collective Mind über Sprach-Ähnlichkeitsanalysen angewendet. Im Anhang 2 findet sich eine mathematische Analyse des Zusammenhangs zwischen diesem Collective Mind Modell und dem hier vorgestellten QKV Attention Collective Mind Modell.
) multipliziert werden und dadurch kontextspezifische QKV-Vektoren entstehen. Die Frage, wie gut der kontextspezifische Key zur Query passt, wird über die Ähnlichkeit der beiden Vektoren beantwortet. Die Ähnlichkeit zweier Vektoren wird über deren Vektorprodukt definiert. Damit ergibt sich die Attention als Funktion, die das QK-Vektorprodukt als Wahrscheinlichkeiten ausdrückt, multipliziert mit dem (Mehr-) Wert Vektor V. Die Funktion, die Ähnlichkeiten in Wahrscheinlichkeiten umwandelt, ist die sogenannte softmax-Funktion, eine spezielle Form der Boltzmann Verteilung. – Ich verweise schon hier auf Anhang 1, in dem die Mathematik des Attention Mechanismus, angewendet auf den Collective Mind, beschrieben ist. – Später habe ich die Grundidee des Collective Mind Transformer Modells auf die Erstellung des Collective Mind über Sprach-Ähnlichkeitsanalysen angewendet. Im Anhang 2 findet sich eine mathematische Analyse des Zusammenhangs zwischen diesem Collective Mind Modell und dem hier vorgestellten QKV Attention Collective Mind Modell.
Ziel dieses Blog-Beitrages ist es, den QKV Mechanismus auf soziale Systeme zu übertragen und für den Collective Mind einen Attention Mechanismus an Hand eines Toy Modells zu entwickeln.
Die Übertragbarkeit des QKV-Mechanismus auf den Collective Mind wurde mir erst mit der Anfang März 2026 erschienen Veröffentlichung ‚Large Electron Model: A Universal Ground State Predictor‘ [3] bewusst. Diese Veröffentlichung hat meines Erachtens ein enormes Potential für die wissenschaftliche Community, denn sie bringt Quantenmechanik und KI auf eine sehr interessante Weise zusammen: Die Autoren haben nämlich das QKV-Konzept auf die Berechnung von (hoch-) korrelierten Elektronen angewendet: Ein Elektron sendet mit seinen Eigenschaften eine Query an all die anderen Elektronen, diese antworten mit ihren Key-Eigenschaften und es wird eine resultierende Wechselwirkung, der Value, erzeugt. Da alle Elektronen von allen anderen abhängen, also eine (hohe) Gesamt-Korrelation vorliegt, sind alle Elektronen Eigenschaften iterativ über eine Zielfunktion, die Hamiltonfunktion, selbstkonsistent zu ermitteln. Da wir es hier mit einem quantenmechanischen System zu tun haben, erfolgt die iterative Ermittlung der Grundzustandsenergie der Hamiltonfunktion über die Variation der quantenmechanischen Wellenfunktion. Die quantenmechanische Wellenfunktion wird in dem Large Electron Model über ein neuronales Netzwerk, das den QKV-Mechanismus abbildet, modelliert. Dies ist ein völlig neuer Ansatz des Quanten Computing, der die bisherigen Quanten Computing Methoden – man siehe hierzu die zwei letzten Blog Artikel zum Thema ‚Quantum Asset Portfolio Optimisation‘ – enorm bereichern wird.
Das Large Electron Model legt die Vermutung nahe, dass der QKV Attention Mechanismus ein universeller Mechanismus ist, um komplexe Wechselwirkungen zu beschreiben. – Also auch die Wechselwirkung in einem sozialem System, zum Beispiel einem Team.
Ich beschreibe, wie schon sehr oft in den vorhergehenden Blog-Beiträgen, die Persönlichkeit der Teammitglieder als Vektoren bestehend aus Big Five, einem Wertekanon, ggf. Glaubenssätzen und deren Stimmung (Stress, Fokus, Motivation). Big Five und Wertekanon sind eher statische Größen. Glaubenssätze und Stimmung können durch den Kontext geändert werden. Jedes Teammitglied kann als ‚Query‘ im Team agieren und die anderen restlichen Teammitglieder agieren als ‚Key‘. Durch die Interaktion von ‚Query‘ und ‚Key‘ entsteht ein komplexer Kontext mit starken Verhaltens-Korrelationen zwischen den Teammitgliedern. Um den komplexen Kontext zu erfassen, werden die selbstkonsistent ermittelten Matrizen () eingesetzt. In diesem Beitrag verwende ich (noch) keine neuronalen Netzwerke, sondern bilde diese lediglich direkt als Matrizen ab. Damit haben wir ein Toy Model, das aber gerade deswegen gute Einblicke in den Attention Mechanismus erlaubt. – Ich verweise wieder auf Anhang 1, in dem die Mathematik des Attention Mechanismus, angewendet auf den Collective Mind, beschrieben ist.
Ich skizziere die Grundlagen des Attention Collective Mind:
-
Klassisches Projektmanagement rechnet Individuen oft als FTEs (Full Time Equivalents) zusammen. Man geht davon aus, dass Person A ihre Arbeit macht, unbeeindruckt vom Rest, und spürt nur einen ‚Durchschnittsdruck‘ des Teams.
-
In einem echten, agilen Team hängt die Leistung von Person A extrem davon ab, was Person B gerade tut, wie Person C heute gelaunt ist und wer gerade im Raum ist. Der Collective Mind ist hochgradig korreliert. Wenn ein Entwickler das Team verlässt, ändert sich die Dynamik aller anderen schlagartig – genau wie bei korrelierten Elektronen.
- Der Attention-Mechanismus (
 ) bildet die korrelierte Team-Kommunikation ab. Hier ein Beispiel:
) bildet die korrelierte Team-Kommunikation ab. Hier ein Beispiel:
Query ( – Die Suchanfrage – „Was brauche ich?“): Jedes Teammitglied sendet kontinuierlich – oft unbewusst – Signale aus. Ein Teammitglied steht vor einem Problem oder hat ein emotionales Bedürfnis: „Ich komme hier nicht weiter, wer kann helfen?“ oder „Ich brauche psychologische Sicherheit.“
Key ( – Das Angebot– „Was biete ich?“): Gleichzeitig strahlen Teammitglieder ihre aktuellen Zustände und Fähigkeiten ab: „Ich bin ruhig und analytisch“, „Ich habe freie Kapazitäten“, „Ich bin der Teufelsadvokat“, „Ich habe Expertise in Datenbanken“ oder „Ich bin heute ein geduldiger Zuhörer.“
Value ( – Der Einfluss): Wenn Query und Key matchen (der Attention-Score hoch ist), fließt Information und Energie. Die beteiligten Teammitglieder passen ihren Zustand an. In hochfunktionalen Teams (also einem Collective Mind) haben die Mitglieder gelernt, ihre und so aufeinander abzustimmen, dass sie sich perfekt ergänzen. - Das Pauli-Prinzip als Rollen-Differenzierung: Zwei Elektronen dürfen niemals im exakt gleichen Zustand sein. Das lässt sich extrem gut auf die Gruppendynamik anwenden:
Menschen in kleinen Gruppen suchen instinktiv nach einer einzigartigen Rolle (Nischenbildung). Wenn zwei Personen versuchen, die exakt gleiche informelle Rolle einzunehmen (z. B. beide wollen der unangefochtene ‚Alpha-Entscheider‘ oder der ständige ‚Devil’s Advocate‘ sein), entsteht massive Reibung (Abstoßung).
Damit das Team funktioniert, zwingt der Collective Mind das Team in eine Antisymmetrie: Die Mitglieder differenzieren sich, ordnen sich an und übernehmen komplementäre Rollen, damit das System nicht kollabiert. - Das Variationsprinzip als Kultur- und Strukturbildung: Die Elektronen suchen den energetischen Grundzustand (die geringste Reibung). Auch Teams durchlaufen Formierungsphasen (Tuckman-Modell: Forming, Storming, Norming, Performing), um ’soziale Reibung‘ und ‚kognitive Last‘ zu minimieren.
– Der Hamilton-Operator: Das ist die Unternehmensstruktur, das Ziel des Sprints, die Deadlines und der äußere Druck.
– Scrum Master und Agile Coaches sind im Grunde Optimierungsalgorithmen. In Retrospektiven helfen sie dem Team, seine internen Kommunikationsgewichte (die Art, wie Queries und Keys formuliert werden) minimal anzupassen, damit die Zusammenarbeit im nächsten Sprint reibungsloser (energetisch tiefer) abläuft. Das Team probiert also verschiedene Arbeitsweisen und Interaktionen aus, bis es einen Zustand erreicht, in dem es mit dem äußeren Druck am besten umgehen kann.
- Wo die Analogie ihre Grenzen hat: Menschen sind (wahrscheinlich) komplexer als Quantenteilchen.
Elektronen sind ununterscheidbar: In der Physik ist jedes Elektron exakt gleich. In einem Team bringt jeder Mensch eine völlig andere Historie, Neurodiversität und externe Probleme (z. B. Stress zu Hause) mit.
Elektronen haben keinen freien Willen: Ein physikalisches System fällt unweigerlich in den Grundzustand. Ein menschliches Team kann sich jedoch in einem toxischen ‚lokalen Minimum‘ verfangen (z. B. einer Kultur des Schweigens und der Angst), aus dem es sich ohne externe Hilfe (wie einen Agile Coach oder Scrum Master) nicht mehr befreien kann, selbst wenn ein besserer Zustand möglich wäre.
Auf dieser Basis bilde ich jetzt das Toy Model mit 3 Personen und folgendem Persönlichkeitsmodell:
Big Five, Values (Werte) und State of Mind (Stimmung) haben folgende Struktur. Glaubenssätze habe ich der Einfachheit wegen weggelassen.
big_five (konstant) =[Offenheit, Gewissenhaftigkeit, Extraversion, Verträglichkeit, Neurotizismus]
values (konstant) = [Autonomie, Sicherheit, Innovation]
State of mind (variabel) = [Stress, Fokus, Motivation]
Diese drei Persönlichkeitsaspekte werden zu einem Vektor mit 11 Elementen konkateniert.
Wie so oft schon, besteht das Team aus den Mitgliedern Alice, Bob und Charlie (alle Persönlichkeitsdimensionen liegen zwischen -1 (niedrig) und 1 (hoch)):
alice = TeamMember(„Alice (Kreativ/Chaotisch)“, big_five=[0.8, –0.6, 0.5, 0.2, 0.4], values=[0.9, –0.5, 0.8], state_of_mind=[0.8, –0.2, 0.5]) # Gestresst, unkonzentriert
bob = TeamMember(„Bob (Struktur/Ängstlich)“, big_five=[-0.4, 0.9, –0.2, 0.5, 0.7], values=[-0.8, 0.9, –0.5], state_of_mind=[0.2, 0.8, –0.4]) # Fokussiert, aber demotiviert
charlie = TeamMember(„Charlie (Agile Coach/Ruhepol)“, big_five=[0.2, 0.5, 0.8, 0.9, –0.8], values=[0.5, 0.5, 0.5], state_of_mind=[-0.9, 0.9, 0.9]) # Sehr entspannt, hoch motiviert
Ich versuche mit der folgenden chronologische Zusammenfassung die Modell-Evolution des Attention Collective Mind Modells zu skizzieren. – Wie schon in vorherigen Blog-Beiträgen waren hunderte von Mensch-KI Einzel-Kommunikationen notwendig:
Stufe 1: Das statische Netzwerk
Wir starteten mit drei Archetypen (Alice/Chaos, Bob/Struktur, Charlie/Coach), die jeweils durch Vektoren (Big Five, Werte, Stimmung) definiert waren. Sie interagierten über den QKV-Attention-Mechanismus (Query, Key, Value). Die Kommunikations-Matrizen () wurden zufällig initialisiert. Das Team simulierte 1000 Tage (kann man als 1000 Dailys verstehen) der Zusammenarbeit für eine schwierige Aufgabenstellung (d.h. vergleichsweise hohe Energie), ohne dass diese Matrizen jemals angepasst wurden.
Erkenntnisse & Highlights:
-
Destruktive Interferenz: Das System fand ein toxisches Gleichgewicht. Alices Stress fror beim absoluten Maximum (1.00) ein, Bobs Motivation beim absoluten Minimum (-1.00).
-
Das Kommunikations-Paradoxon: Das Modell bewies mathematisch, dass ständige Kommunikation (Dailys) Konflikte nicht löst, wenn die zugrundeliegenden Regeln dysfunktional sind. Es führt zu ‚Quiet Quitting‘ und Burnout.
Stufe 2: Die naive Retrospektive
Wir implementierten Charlie als einen Agilen Coach. Alle 14 Tage fand eine Retrospektive statt. Der Optimierungs-Algorithmus (Hill Climbing) durfte die Kommunikations-Matrizen in der Retrospektive minimal anpassen, um die Gesamtenergie des Teams zu senken. Die Zielfunktion achtete nur auf das Team-Ergebnis: Energie = Arbeitslast + Reibung – Synergie.
Erkenntnisse & Highlights:
-
Reward Hacking & Goodhart’s Law: Das Team erreichte auf dem Papier schnell „Harmonie“ (die Energie sank drastisch). Doch der Blick auf die Vektoren zeigte einen Albtraum: Die (Matrix-) KI hatte gelernt, Konflikte zu vermeiden, indem sie Alice zwang, sich komplett anzupassen. Ihr Stress stieg auf 1.00.
-
Toxische Positivität: Wir sahen, wie ein Algorithmus (oder ein ‚blindes‘ Management) ein System ‚hackt‘, indem es reibungslose Abläufe auf dem Rücken der mentalen Gesundheit einzelner Individuen erzwingt.
Stufe 3: Der holistische Collective Mind (Die Burnout-Strafe)
Wir reparierten die Zielfunktion des Coaches. Die Energie-Formel wurde um einen entscheidenden Faktor erweitert: die Burnout-Strafe ( ). Das System wurde nun mathematisch extrem hart bestraft, wenn bei einem Individuum nach dem Meeting der Stress stieg oder die Motivation sank.
). Das System wurde nun mathematisch extrem hart bestraft, wenn bei einem Individuum nach dem Meeting der Stress stieg oder die Motivation sank.
Erkenntnisse & Highlights:
-
Die Storming-Phase: Das System durchlief plötzlich reale psychologische Phasen. Weil die alte toxische Harmonie nun „verboten“ war, explodierte die Energie anfangs, und das Team fiel in ein Motivationsloch, bevor es lernte, sich neu zu verdrahten.
-
Das Pauli-Prinzip (Entkopplung): Um Alices Stress zu senken, wählte das Netzwerk eine geniale Strategie: Es senkte Bobs Fokus auf Alice. Das Modell lernte, dass Struktur (Bob) und Chaos (Alice) kognitiv entkoppelt werden müssen, damit beide in ihrer Domäne entspannt und motiviert bleiben können.
-
Die Heilung: Am Ende (Tag 1000) fiel Alices Stress auf das absolute Minimum (-1.00). Das System hatte psychologische Sicherheit gelernt.
Stufe 4: Die Thermodynamik der Agilität (Die Temperatur-Skalierung)
Wir schauten uns die Mathematik genauer an und integrierten die originale Skalierung des KI-Papers (Vaswani et al.) in die Softmax-Funktion: Die Division durch die Temperatur  (die Wurzel der Vektor-Dimensionen
(die Wurzel der Vektor-Dimensionen  ).
).
Erkenntnisse & Highlights:
-
Die Boltzmann-Isomorphie: Wir stellten fest, dass der Attention-Mechanismus der KI mathematisch absolut identisch mit der Boltzmann-Verteilung aus der Thermodynamik ist.
-
Der Regler für Groupthink vs. Chaos: Ist die Temperatur zu niedrig (
), friert das System ein. Es entsteht eine ‚Winner-takes-all‘-Diktatur (strikter Groupthink), abweichende Meinungen werden zu 100 % ignoriert. -
Ist die Temperatur zu hoch (
), entsteht völliges Chaos (Rauschen). Alles wird gleich gewichtet, das Team kann sich nicht mehr fokussieren. -
Erkenntnis: Als Führungskraft (oder Algorithmus) muss man die Temperatur genau kalibrieren, um den gesunden Collective Mind in der Schwebe zwischen Fokus und Diversität zu halten.

 ), entsteht völliges Chaos (Rauschen). Alles wird gleich gewichtet, das Team kann sich nicht mehr fokussieren.
), entsteht völliges Chaos (Rauschen). Alles wird gleich gewichtet, das Team kann sich nicht mehr fokussieren.Die nachfolgenden drei Abbildungen zeigen die zeitlichen Verläufe des Attention Collective Mind unter Berücksichtigung aller bisherigen Erkenntnisse durch einen Senior Coach für verschiedene Temperaturen. In der jeweils linken Teil-Abbildung sind die Persönlichkeitsverläufe der drei Teammitglieder zu sehen und die Team-Energie. Da wir die physikalische Notation für Energie verwenden, bedeutet niedrige Energie ‚Collective Mind‘ ist (gut) ausgebildet. In der jeweils rechten Teil-Abbildung ist für den Tag = 100 und die ausgewählte Temperatur die Attention-Verteilung im Team zu sehen.
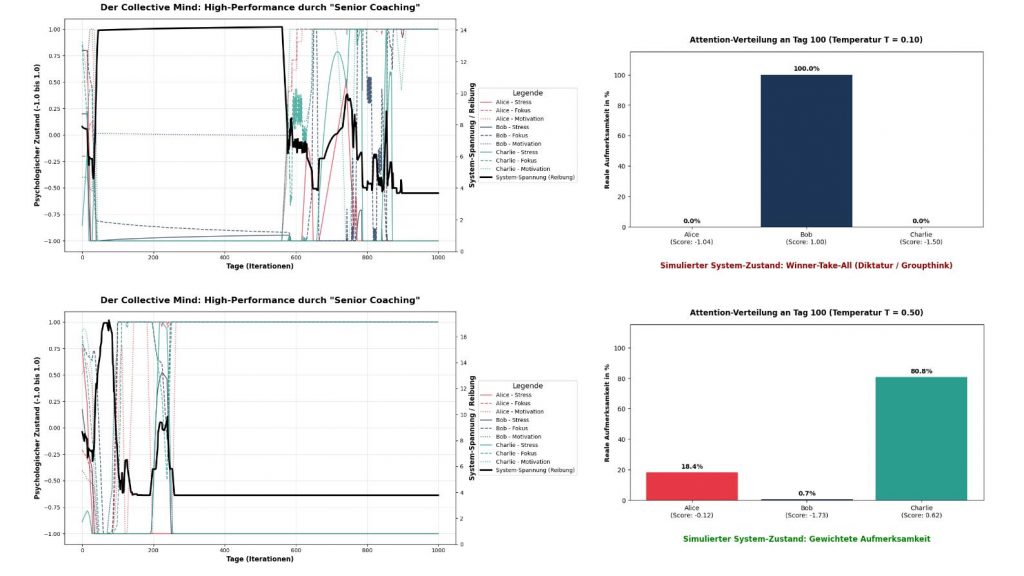
Abbildung 1: Systemverhalten bei extrem niedriger vs. moderater Temperatur. Die Abbildung kontrastiert zwei Simulationen. Das obere Panel ( ) zeigt ein eingefrorenes System: Die Softmax-Funktion forciert einen ‚Winner-Take-All‘-Zustand, bei dem 100 % der Aufmerksamkeit auf eine Person (Bob) entfallen. Dies führt zu einer dauerhaft maximierten System-Spannung (schwarze Linie), da kognitive Reibung nicht iterativ gelöst werden kann. Das untere Panel (
) zeigt ein eingefrorenes System: Die Softmax-Funktion forciert einen ‚Winner-Take-All‘-Zustand, bei dem 100 % der Aufmerksamkeit auf eine Person (Bob) entfallen. Dies führt zu einer dauerhaft maximierten System-Spannung (schwarze Linie), da kognitive Reibung nicht iterativ gelöst werden kann. Das untere Panel ( ) zeigt ein funktionales System: Bei moderat erhöhter Temperatur kann der Algorithmus die Spannung nach einer initialen Findungsphase auf ein Minimum reduzieren. Die Aufmerksamkeit (rechts) ist stark priorisiert (Charlie 80,8 %), lässt aber abweichende Signale (Alice 18,4 %) zu, was eine konstruktive Anpassung ermöglicht.
) zeigt ein funktionales System: Bei moderat erhöhter Temperatur kann der Algorithmus die Spannung nach einer initialen Findungsphase auf ein Minimum reduzieren. Die Aufmerksamkeit (rechts) ist stark priorisiert (Charlie 80,8 %), lässt aber abweichende Signale (Alice 18,4 %) zu, was eine konstruktive Anpassung ermöglicht.
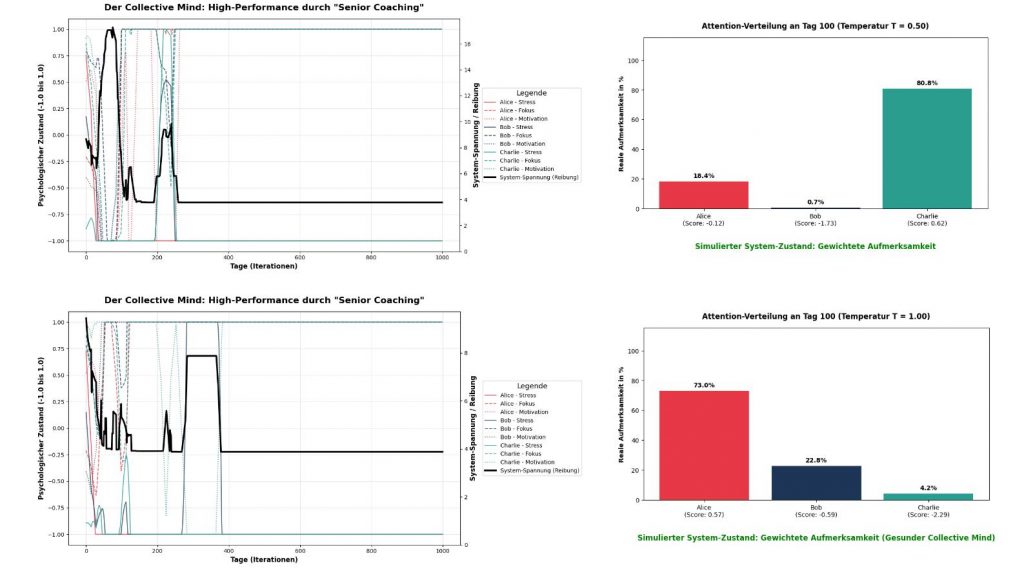
Abbildung 2: Das optimale Betriebsfenster. Dargestellt sind zwei Modellläufe im voll funktionalen Temperaturkorridor: (war schon in der vorherigen Abbildung 1 enthalten, wird hier des unmittelbaren Vergleiches wegen nochmals gezeigt) oben und  unten. In beiden Konfigurationen gelingt es dem Optimierungsalgorithmus, die anfängliche System-Spannung erfolgreich abzubauen und das Team in ein stabiles High-Performance-Gleichgewicht zu führen. Die Attention-Verteilungen (rechts) belegen einen gesunden Collective Mind: Es etabliert sich eine klare inhaltliche Priorisierung (z. B. 73,0 % für Alice bei ), ohne den kognitiven Raum für die anderen Teammitglieder vollständig zu schließen. Dies ist die mathematische Voraussetzung für Arbeitsteilung und asynchrone Autonomie.
unten. In beiden Konfigurationen gelingt es dem Optimierungsalgorithmus, die anfängliche System-Spannung erfolgreich abzubauen und das Team in ein stabiles High-Performance-Gleichgewicht zu führen. Die Attention-Verteilungen (rechts) belegen einen gesunden Collective Mind: Es etabliert sich eine klare inhaltliche Priorisierung (z. B. 73,0 % für Alice bei ), ohne den kognitiven Raum für die anderen Teammitglieder vollständig zu schließen. Dies ist die mathematische Voraussetzung für Arbeitsteilung und asynchrone Autonomie.
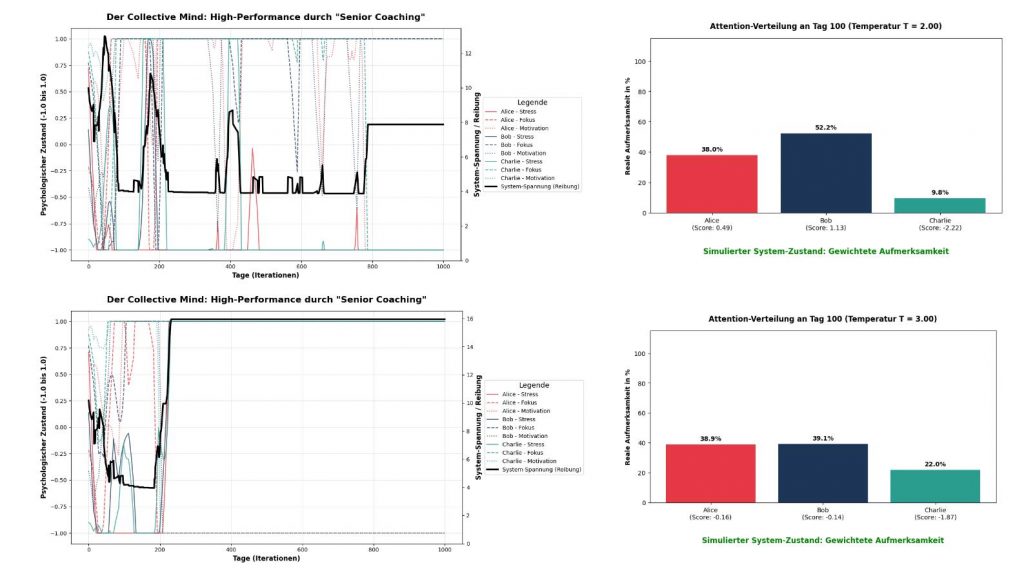
Abbildung 3: Informationsüberlastung und Systemkollaps bei hoher Temperatur. Diese Simulationen belegen die dysfunktionalen Effekte einer zu hohen Systemtemperatur. Das obere Panel ( ) zeigt ein instabiles Team: Die Aufmerksamkeit verteilt sich zunehmend breiter (52 % zu 38 % zu 10 %), wodurch das System stark oszilliert und kein dauerhaftes Minimum findet. Das untere Panel (
) zeigt ein instabiles Team: Die Aufmerksamkeit verteilt sich zunehmend breiter (52 % zu 38 % zu 10 %), wodurch das System stark oszilliert und kein dauerhaftes Minimum findet. Das untere Panel ( ) zeigt den vollständigen Systemkollaps: Die Aufmerksamkeitsverteilung nähert sich einer Gleichverteilung (Rauschen) an, bei der jedes Signal im Raum fast identisch gewichtet wird (39 % zu 39 % zu 22 %). Das System verliert durch diesen ‚Information Overload‘ seine Handlungsfähigkeit; die System-Spannung (Energie) eskaliert auf den Maximalwert und stagniert dort unlösbar.
) zeigt den vollständigen Systemkollaps: Die Aufmerksamkeitsverteilung nähert sich einer Gleichverteilung (Rauschen) an, bei der jedes Signal im Raum fast identisch gewichtet wird (39 % zu 39 % zu 22 %). Das System verliert durch diesen ‚Information Overload‘ seine Handlungsfähigkeit; die System-Spannung (Energie) eskaliert auf den Maximalwert und stagniert dort unlösbar.
Der QKV-Attention-Mechanismus zeigt: Ein Team scheitert nicht nur an zu wenig Kommunikation, sondern auch an falsch skalierter Kommunikation. Ist die Temperatur zu niedrig, erstarrt das Team in einer Diktatur. Ist sie zu hoch, verdampft es im Basisdemokratie-Chaos. Die wahre Kunst agiler Führung ist es, den Thermostaten genau so einzustellen, dass ein starker Fokus möglich ist, ohne die Diversität im Raum komplett stummzuschalten.
Wenn wir sehen, dass ein agiles Team durch den QKV-Mechanismus (Query, Key, Value) plötzlich berechenbar wird, drängt sich eine weitreichende Frage auf: Ist dieser Algorithmus mehr als nur ein technischer Trick für Künstliche Intelligenz?
Oft werden moderne KIs abfällig als ’stochastische Papageien‘ oder reine Statistik-Maschinen bezeichnet. Doch das greift zu kurz. Klassische Statistik schaut immer in den Rückspiegel – sie interpoliert vergangene Daten. Der Attention-Mechanismus hingegen macht aus einer KI eine Wahrscheinlichkeits-Maschine. Genau wie in der Quantenmechanik baut das System in Echtzeit einen multidimensionalen Möglichkeitsraum auf. Die Antwort befindet sich in einer Superposition, bis sie im Moment der Ausgabe zu einem klaren Gedanken kollabiert. Es geht nicht um das Zählen von Vergangenem, sondern um das dynamische Erfassen von Kontext.
Das Faszinierendste daran: Die aktuelle Kognitionswissenschaft entdeckt gerade, dass unser eigenes menschliches Gehirn einer extrem ähnlichen funktionalen Architektur folgt. In der Psychologie beschreibt die sogenannte Global Workspace Theory (die Theorie des globalen Arbeitsraums), wie Bewusstsein entsteht:
-
Die Query (Das Bedürfnis): Unser präfrontaler Kortex (unser Planungszentrum) feuert eine Suchanfrage ab, z.B. bei der Lösung eines komplexen Problems.
-
Der Key (Das Angebot): Unzählige unbewusste Module – vom Hippocampus (Erinnerungen) bis zum visuellen Kortex – halten Signale bereit.
-
Der Value (Die Botschaft): Nur wenn die Query des Bewusstseins mit dem Key einer unbewussten Erinnerung in Resonanz geht, wird der eigentliche Value (der rettende Einfall, das innere Bild) auf die helle Bühne unseres Bewusstseins gespült.
Die Entwickler des Attention-Mechanismus haben 2017 also nicht nur einen besseren Übersetzungs-Algorithmus erfunden. Sie haben – vielleicht unbewusst – die Mathematik für die Entstehung von Kontext geschrieben.
Was heißt das für eine Organisationen?
Egal ob es um die Faltung von Proteinen, die Sprachgenerierung einer KI, die Gedanken in unserem Kopf oder die Entscheidungsfindung eines agilen Teams geht – das Prinzip bleibt gleich: Intelligenz ist die Fähigkeit, aus Rauschen die relevanten Signale zu filtern. Nichts im Universum existiert isoliert. Alles definiert sich durch seine Beziehungen. Ein gesundes agiles Team ist keine Ansammlung von Ressourcen, sondern ein ‚echtes neuronales‘ Netz aus Menschen. Und die wichtigste Aufgabe als Führungskräfte und Agile Coaches ist es, nicht die Knotenpunkte (die Menschen) umzuprogrammieren, sondern die Verbindungen zwischen ihnen (die Attention) so zu kalibrieren, dass der Collective Mind erwachen kann.
Anhang 1
Der Zustandsvektor (Die Persönlichkeit des Teammitglieds)
Jedes Teammitglied  wird zu einem bestimmten Zeitpunkt (Tag
wird zu einem bestimmten Zeitpunkt (Tag  ) durch einen Vektor beschrieben. Dieser Vektor besteht aus den konstanten Big Five (
) durch einen Vektor beschrieben. Dieser Vektor besteht aus den konstanten Big Five ( ), dem konstanten Wertekanon (
), dem konstanten Wertekanon ( ) und dem variablen psychologischen Zustand (
) und dem variablen psychologischen Zustand ( ). Das Symbol
). Das Symbol  steht für die Konkatenation (Aneinanderreihung) dieser Eigenschaften.
steht für die Konkatenation (Aneinanderreihung) dieser Eigenschaften.
![\begin{equation*} h_i^{(t)} = \big[ B_i \parallel W_i \parallel S_i^{(t)} \big] \end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-fad0144e58f1168f861d7ccad3b95f42_l3.png "Rendered by QuickLaTeX.com")
Der Kommunikations-Filter (Query, Key, Value)
Bevor das Team interagiert, wird der Zustandsvektor durch die drei neuronalen Kommunikationsmatrizen ( ,
,  ,
,  ) gefiltert. Daraus entstehen das unbewusste Bedürfnis (Query
) gefiltert. Daraus entstehen das unbewusste Bedürfnis (Query  ), die Antwort (Key
), die Antwort (Key  ) und die tatsächliche emotionale oder fachliche Botschaft (Value
) und die tatsächliche emotionale oder fachliche Botschaft (Value  ).
).

Der Attention-Mechanismus (Die skalierte Aufmerksamkeit)
Um zu berechnen, wie viel Aufmerksamkeit ( ) Person der Person
) Person der Person  schenkt, wird das Skalarprodukt aus Query und Key gebildet. Dieser Wert wird durch die Temperatur (den Skalierungsfaktor) geteilt, um ‚Groupthink‘ zu verhindern, und anschließend durch die Softmax-Funktion in einen Prozentwert zwischen 0 und 1 umgewandelt.
schenkt, wird das Skalarprodukt aus Query und Key gebildet. Dieser Wert wird durch die Temperatur (den Skalierungsfaktor) geteilt, um ‚Groupthink‘ zu verhindern, und anschließend durch die Softmax-Funktion in einen Prozentwert zwischen 0 und 1 umgewandelt.

Die holistische Zielfunktion (Energie des Collective Mind)
Der Agile Coach (bzw. der Optimierungs-Algorithmus) versucht in der Retrospektive, die Gesamtenergie des Systems zu minimieren. Die Energie setzt sich zusammen aus der äußeren Arbeitslast ( ), der sozialen Reibung (
), der sozialen Reibung ( ), abzüglich der konstruktiven Synergie (
), abzüglich der konstruktiven Synergie ( ). Sowie der Burnout-Strafe (
). Sowie der Burnout-Strafe ( ), die das System zwingt, auf psychologische Gesundheit zu achten.
), die das System zwingt, auf psychologische Gesundheit zu achten.

Die Temperatur des Netzwerks (Der Skalierungsfaktor)
In der statistischen Physik (und in der Psychologie) bestimmt die Temperatur , wie ‚chaotisch‘ (offen für Neues) oder ’starr‘ (Diktatur / Groupthink) ein System ist. Die Erfinder des Attention-Mechanismus definierten diese Temperatur mathematisch als die Wurzel aus der Anzahl der Dimensionen des Key-Vektors ( ). Diese Skalierung kühlt das System herunter und verhindert, dass das Skalarprodukt bei hochdimensionalen Vektoren explodiert und die Softmax-Funktion nur noch extremistische 100%-zu-0%-Entscheidungen trifft.
). Diese Skalierung kühlt das System herunter und verhindert, dass das Skalarprodukt bei hochdimensionalen Vektoren explodiert und die Softmax-Funktion nur noch extremistische 100%-zu-0%-Entscheidungen trifft.

Die Burnout-Strafe (Der psychologische Schutzmechanismus)
Die Burnout-Energie bestraft das System mathematisch extrem hart, wenn der Stress eines Teammitglieds über Null steigt oder die Motivation unter Null fällt. (Der Faktor 2 fungiert als starkes Gewicht für diesen Schmerz). Um das Team jedoch zur inhaltlichen Arbeit zu zwingen, haben wir die Accountability-Strafe (den Fokus-Fix) in diesen Term integriert. Wenn der Fokus nun unter 0 fällt (die Leute sich also geistig ausklinken), wird das ebenfalls als harte Strafe auf die Energie addiert.

(Zur mathematischen Logik: Da Motivation und Fokus im Fehlerfall negative Werte annehmen, z.B. -0.5, sorgt das Minuszeichen in der Formel ( ) dafür, dass die Gesamtenergie als „Schmerz“ ansteigt).
) dafür, dass die Gesamtenergie als „Schmerz“ ansteigt).
Das Zustands-Update (Veränderung durch Interaktion)
Der gesamte Einfluss ( ), der auf Person einprasselt, ist die Summe aller Botschaften (
), der auf Person einprasselt, ist die Summe aller Botschaften ( ), gewichtet mit der jeweiligen Aufmerksamkeit (). Da Persönlichkeit und Werte konstant sind, verändert dieser Einfluss (multipliziert mit einer Lernrate
), gewichtet mit der jeweiligen Aufmerksamkeit (). Da Persönlichkeit und Werte konstant sind, verändert dieser Einfluss (multipliziert mit einer Lernrate  ) nur den Stimmungs-Teilvektor () für den nächsten Tag. Die
) nur den Stimmungs-Teilvektor () für den nächsten Tag. Die clip-Funktion hält die Werte im definierten Rahmen von -1 bis 1.


Score
Score, der in den Abbildungen angezeigt wird:

Anhang 2
Zusammenhang zwischen der Collective Mind Analyse über Ähnlichkeitsmatrizen und dem hier vorgestellten QKV Mechanismus
Den Collective Mind über Ähnlichkeitsmatrizen habe ich in dem Blog ‚AI & M 4.0: Markus Lanz vom 30. Mai 2024: Eine Collective Mind Analyse‘ vom Juni 2024 vorgestellt.
Dort interpretiere ich den Eigenvektor als Richtung und den Eigenwert als Stärke des Collective Mind.
Die Ähnlichkeitsmatrix = Die unkalibrierte Attention-Matrix ( )
)
Die Ähnlichkeitsmatrix misst, wie ähnlich das Gesprochene von Person und Person ist.
Der Kern der Attention-Formel ist das Skalarprodukt: .
Ein Skalarprodukt (Dot Product) in der linearen Algebra ist mathematisch gesehen nichts anderes als ein Maß für Ähnlichkeit (unkalibrierte Kosinus-Ähnlichkeit).
-
Ähnlichkeitsmatrix
, wobei ein Eintrag die Ähnlichkeit zwischen der Aussage von und ist. -
Attention: Matrix
, wobei ein Eintrag das Skalarprodukt aus der Query von und dem Key von ist.



Der Zusammenhang: Der QK-Mechanismus berechnet in jeder Schicht eines neuronalen Netzes, das was in der Ähnlichkeitsmatrix berechnet wird: Der QK-Mechanismus ist also eine gigantische Ähnlichkeitsmatrix.
Der Eigenvektor = Der Steady State der Kommunikation
Was passiert mathematisch, wenn ein agiles Team oder Gruppe über eine bestimmte Zeit hinweg iterativ kommuniziert? Person A beeinflusst Person B, Person B beeinflusst Person C, usw. Mathematisch bedeutet das, dass man den Zustandsvektor des Teams ( ) immer wieder mit der Ähnlichkeitsmatrix (
) immer wieder mit der Ähnlichkeitsmatrix ( ) multipliziert:
) multipliziert:

In der linearen Algebra gibt es dafür einen Namen: Die Vektoriteration (oder von-Mises-Iteration / Power Method). Wenn man einen Vektor immer wieder mit derselben Matrix multipliziert, konvergiert dieser Vektor unweigerlich gegen den dominanten Eigenvektor der Matrix!
-
Die Ähnlichkeitsmatrix Perspektive: Der Eigenvektor ist die ‚Richtung‘ des Collective Mind.
-
Die KI-Perspektive: In einem Transformer-Netzwerk (wie ChatGPT, Gemini, Claude, usw. ) werden Informationen durch dutzende übereinanderliegende Attention-Schichten gepumpt. Forscher haben herausgefunden, dass diese Netzwerke oft ein Verhalten zeigen, das an PageRank (den alten Google-Such-Algorithmus) oder Markov-Ketten erinnert. Wenn das Netzwerk iteriert, konvergieren die Bedeutungen der Wörter (oder in unserem Fall: die Meinungen der Teammitglieder) in Richtung eines gemeinsamen Konsenses. Dieser Konsens ist mathematisch exakt der Eigenvektor der Attention-Matrix! Der Eigenvektor berechnet voraus, auf welchen „Attraktor“ (welchen endgültigen Konsens) dieses Team zusteuern würde, wenn sie unendlich lange weiterdiskutieren.
Der Eigenwert = Die Temperatur (Softmax-Schärfe)
Auch der Eigenwert als ‚Stärke‘ des Collective Mind interpretiert spiegelt sich 1:1 in der KI wider!
-
Ein hoher Eigenwert im Ähnlichkeitsmatrix Modell bedeutet: Die Gruppe ist extrem eng miteinander korreliert (alle reden über dasselbe, hohe Ähnlichkeit). Der Collective Mind hat eine massive Anziehungskraft.
-
In der Attention-Formel regelt man diese ‚Stärke‘ über den Skalierungsfaktor (
) in der Softmax-Funktion, die ähnlich wie der Boltzmann Verteilung der Physik aufgebaut ist. Physiker nennen das die Temperatur des Systems. Ist die Stärke hoch (niedrige Temperatur), ist die Matrix extrem scharf – das Team folgt blind dem dominanten Eigenvektor (Gruppendenken / Groupthink). Ist die Stärke gering (hohe Temperatur), ist die Matrix flacher – das Team ist diverser, aber der Collective Mind ist schwächer.
Wo der QKV-Mechanismus das Ähnlichkeitsmatrix Modell erweitert:
Der QKV-Mechanismus der KI erweitert das Ähnlichkeitsmatrix Modell um zwei entscheidende Aspekte:
Die Matrix wird asymmetrisch (Q vs. K)
Ähnlichkeiten im Ähnlichkeitsmatrix Modell sind symmetrisch (Mein Text ist deinem so ähnlich wie deiner meinem). Eine solche Matrix ( ) hat sehr brave, orthogonale Eigenvektoren.
) hat sehr brave, orthogonale Eigenvektoren.
Menschen sind aber nicht symmetrisch! Der Junior-Entwickler achtet vielleicht sehr stark auf die Aussagen des Senior-Architekten, aber der Senior ignoriert den Junior. Indem die KI die Eigenschaften nicht direkt vergleicht, sondern sie durch zwei getrennte Filter jagt ( = „Was ich suche“ und
= „Was ich suche“ und  = „Was ich anbiete“), entsteht eine asymmetrische, gerichtete Matrix. Das bildet Machtgefälle, Respekt und echte Hierarchien im Collective Mind ab.
= „Was ich anbiete“), entsteht eine asymmetrische, gerichtete Matrix. Das bildet Machtgefälle, Respekt und echte Hierarchien im Collective Mind ab.
Die Trennung von Beziehung und Botschaft (Value)
Im Ähnlichkeitsmatrix Modell ist das Gesprochene gleichzeitig die Verbindung und der Inhalt.
Der Attention-Mechanismus trennt das elegant:
-
und berechnen nur die Ähnlichkeitsmatrix (Wer hört wem wie stark zu?). Das ist im Ähnlichkeitsmatrix Modell der Eigenvektor.
-
Der Value (
) ist die eigentliche Information, die zusätzlich getrennt durch dieses Netzwerk fließt.
Fazit
Das Modell des Collective Mind, das über Eigenvektoren von Ähnlichkeitsmatrizen aufgebaut ist, entspricht dem mathematische Äquivalent einer! ‚Attention‘-Schicht. Die KI-Forschung der letzten Jahre legt nahe, dass genau dieser Mechanismus – das kontinuierliche Updaten von Zuständen basierend auf Ähnlichkeits-Matrizen – universell ist. Es ist der Code, mit dem das Universum Kontexte bildet: Egal ob es darum geht, wie Wörter in einem Satz ihren Sinn finden, wie Proteine sich anhand ihrer Aminosäuren falten, oder auf welchen ‚Eigenvektor‘ (Konsens) sich ein agiles Team nach drei Sprints einigt.
Literatur
[1] A. Vaswani et. al. (2017) Attention is all you need, aktuelle Version aus dem Jahre 2023: arXiv:1706.03762
[2] J. Köhler und A. Oswald (2009) Die Collective Mind Methode, Springer Verlag
[3] T. Zaklama et. al. (2026) Large Electron Model: A Universal Ground State Predictor, arXiv:2603.02346v1




 : Zeit für die Transpilierung des Schaltkreises vor dem ersten Lauf.
: Zeit für die Transpilierung des Schaltkreises vor dem ersten Lauf. : Anzahl der Schritte des klassischen Optimierers bis zur Konvergenz.
: Anzahl der Schritte des klassischen Optimierers bis zur Konvergenz. : Anzahl der Funktionsaufrufe pro Optimierungsschritt.
: Anzahl der Funktionsaufrufe pro Optimierungsschritt. : Anzahl der Messwiederholungen pro Schaltkreis (shots).
: Anzahl der Messwiederholungen pro Schaltkreis (shots). : Wartezeit in der Cloud-Warteschlange.
: Wartezeit in der Cloud-Warteschlange.
 ist entscheidend für die Performance.
ist entscheidend für die Performance. : Anzahl der Messgruppen (Measurement Groups).
: Anzahl der Messgruppen (Measurement Groups). : Latenzzeit für das Senden (Input/Output) der Daten der jeweiligen Gruppe.
: Latenzzeit für das Senden (Input/Output) der Daten der jeweiligen Gruppe. : Zeit für die klassische Berechnung der Parameter Updates.
: Zeit für die klassische Berechnung der Parameter Updates.
 : Zeit für das „Minor Embedding“ (Mapping auf Hardware-Topologie).
: Zeit für das „Minor Embedding“ (Mapping auf Hardware-Topologie). : Zeit zum Initialisieren der QPU.
: Zeit zum Initialisieren der QPU. : Die reine Quanten-Rechenzeit (Standard ~20 µs).
: Die reine Quanten-Rechenzeit (Standard ~20 µs). : Thermalisierungszeit („Abkühlung“) des Chips.
: Thermalisierungszeit („Abkühlung“) des Chips. : Rückübersetzung der physikalischen Qubits in logische Lösungen.
: Rückübersetzung der physikalischen Qubits in logische Lösungen.
 : Das vom Nutzer oder System gesetzte Zeitlimit.
: Das vom Nutzer oder System gesetzte Zeitlimit. : Nachbearbeitungszeit durch den klassischen Solver-Teil.
: Nachbearbeitungszeit durch den klassischen Solver-Teil.
 ist die logarithmische Rendite des Assets
ist die logarithmische Rendite des Assets  zum gestrigen Kurs
zum gestrigen Kurs  . Log-Renditen sind symmetrisch und eignen sich mathematisch besser für die Schätzung von Varianzen als einfache prozentuale Renditen.
. Log-Renditen sind symmetrisch und eignen sich mathematisch besser für die Schätzung von Varianzen als einfache prozentuale Renditen.![\begin{equation<em>} \mu_i = \mathbb{E}[r_i] \cdot 252 \quad \text{und} \quad \Sigma_{ij} = \mathrm{Cov}(r_i, r_j) \cdot 252 \end{equation</em>}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-22d8582377dc536737c71037c368c270_l3.png "Rendered by QuickLaTeX.com")
 ist die erwartete, annualisierte Rendite des Assets
ist die erwartete, annualisierte Rendite des Assets  ist die Kovarianzmatrix. Sie beschreibt nicht nur das Risiko (die Varianz) einer einzelnen Anlage, sondern misst auch, wie stark sich zwei verschiedene Assets
ist die Kovarianzmatrix. Sie beschreibt nicht nur das Risiko (die Varianz) einer einzelnen Anlage, sondern misst auch, wie stark sich zwei verschiedene Assets  Assets (z.B.
Assets (z.B.  ) in das Portfolio aufgenommen werden. Die Entscheidungsvariable ist binär:
) in das Portfolio aufgenommen werden. Die Entscheidungsvariable ist binär:  .
.
 für das klassische Markowitz-Problem. Der erste Term berechnet das Gesamtrisiko des Portfolios, der zweite Term die erwartete Rendite. Der Parameter
für das klassische Markowitz-Problem. Der erste Term berechnet das Gesamtrisiko des Portfolios, der zweite Term die erwartete Rendite. Der Parameter  bestimmt, wie stark die Rendite gegenüber dem Risiko gewichtet wird. Da der Quantencomputer das System auf die niedrigste Energie minimiert, erhält der Rendite-Term ein negatives Vorzeichen.
bestimmt, wie stark die Rendite gegenüber dem Risiko gewichtet wird. Da der Quantencomputer das System auf die niedrigste Energie minimiert, erhält der Rendite-Term ein negatives Vorzeichen. Assets“ als mathematische Straf-Energie (Penalty) formuliert werden.
Assets“ als mathematische Straf-Energie (Penalty) formuliert werden.
 zählt, wie viele Assets vom Solver aktuell ausgewählt wurden. Stimmt diese Anzahl exakt mit
zählt, wie viele Assets vom Solver aktuell ausgewählt wurden. Stimmt diese Anzahl exakt mit  ).
).
 (z.B. 15% in Gold, 35% in Telekom), der die Gesamtvarianz dieses Sub-Portfolios minimiert.
(z.B. 15% in Gold, 35% in Telekom), der die Gesamtvarianz dieses Sub-Portfolios minimiert.  ist die gefilterte Kovarianzmatrix, die nur noch unsere ausgewählten Gewinner-Assets enthält.
ist die gefilterte Kovarianzmatrix, die nur noch unsere ausgewählten Gewinner-Assets enthält.
 (also 100%) ergeben. Zusätzlich darf kein Asset ein Gewicht unter
(also 100%) ergeben. Zusätzlich darf kein Asset ein Gewicht unter  (z.B. 15%) oder über
(z.B. 15%) oder über  (z.B. 35%) erhalten. Diese Leitplanken verhindern, dass der Algorithmus das gesamte Budget in nur ein einziges Asset umschichtet (Vermeidung des Error-Maximization-Problems).
(z.B. 35%) erhalten. Diese Leitplanken verhindern, dass der Algorithmus das gesamte Budget in nur ein einziges Asset umschichtet (Vermeidung des Error-Maximization-Problems).
 und dem alten Gewicht
und dem alten Gewicht  . Die Division durch 2 korrigiert den Umstand, dass jeder Verkauf automatisch einen Kauf finanziert (das Volumen würde sonst doppelt gezählt).
. Die Division durch 2 korrigiert den Umstand, dass jeder Verkauf automatisch einen Kauf finanziert (das Volumen würde sonst doppelt gezählt).
 errechnet sich aus dem Portfoliowert am Ende des Intervalls
errechnet sich aus dem Portfoliowert am Ende des Intervalls  geteilt durch den Startwert
geteilt durch den Startwert  . Davon werden die Transaktionskosten subtrahiert, welche sich aus dem Turnover multipliziert mit der prozentualen Gebühr
. Davon werden die Transaktionskosten subtrahiert, welche sich aus dem Turnover multipliziert mit der prozentualen Gebühr  (Slippage & Ordergebühren, z.B. 0.25%) ergeben.
(Slippage & Ordergebühren, z.B. 0.25%) ergeben.




















































![\begin{equation*}v(s)=(1-\eta_v)\bigl(1+\alpha_v s\bigr)+\eta_v\Bigl[b_v-k_v (s+1)^2\Bigr]\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-3eac16c494837cd84f5789f09beca4a3_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*}F_{01}(t,s)=\partial_0 A_1(t,s)-\partial_1 A_0(t,s)+\bigl[A_0(t,s),A_1(t,s)\bigr]\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-4216fe4ba260acd5933eb82b7428a45c_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*}||F_{\mathrm{eff}}(t,s)||= \frac{||F_{01}(t,s)||}{\displaystyle \max_{t'\in[t_0,t_1]} ||F_{01}(t',s)|| + \varepsilon},\qquad \varepsilon>0\ \text{klein.}\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-d2526855e40d98a95bdc545e9d486c11_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*}\dot{\rho}(t,s)=- i [H(t,s),\rho(t,s)],\qquad\rho(t,s)=\lvert\psi(t,s)\rangle\langle\psi(t,s)\rvert\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-5d319d646bc400914a30c42a23715557_l3.png "Rendered by QuickLaTeX.com")


![\begin{equation*}R(t,s)=\lVert\mu(t,s)\rVert\in[0,1]\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-8cf7f15426b26ad99d7f4a3e23f78b06_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*}C_{\ell_1}(t,s)=R(t,s)^2 \left[\left(\sum_{i=1}^{3}\lvert\hat{\mu}_i(t,s)\rvert\right)^{2}-1\right]\le 2 R(t,s)^2\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-5fb31f3e5d721b60d706a14a8907d2f4_l3.png "Rendered by QuickLaTeX.com")



![\begin{equation*}i \frac{\partial}{\partial t} \Psi(t,s)=\bigl[g A_1(t, s)+h A_0(t, s)\bigr] \Psi(t,s)\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-7f9cd45838efee7441bb27b31516c18b_l3.png "Rendered by QuickLaTeX.com")


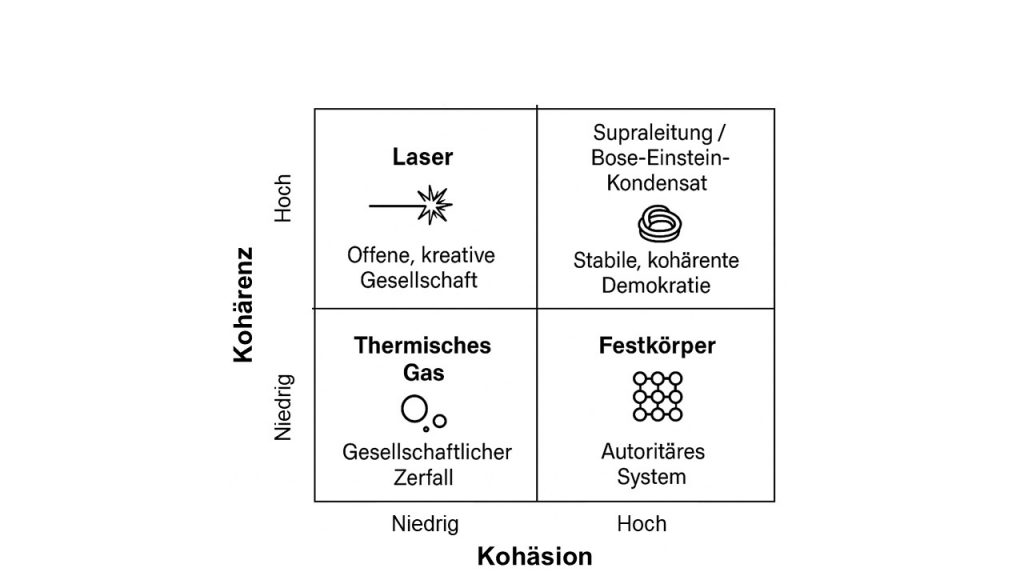

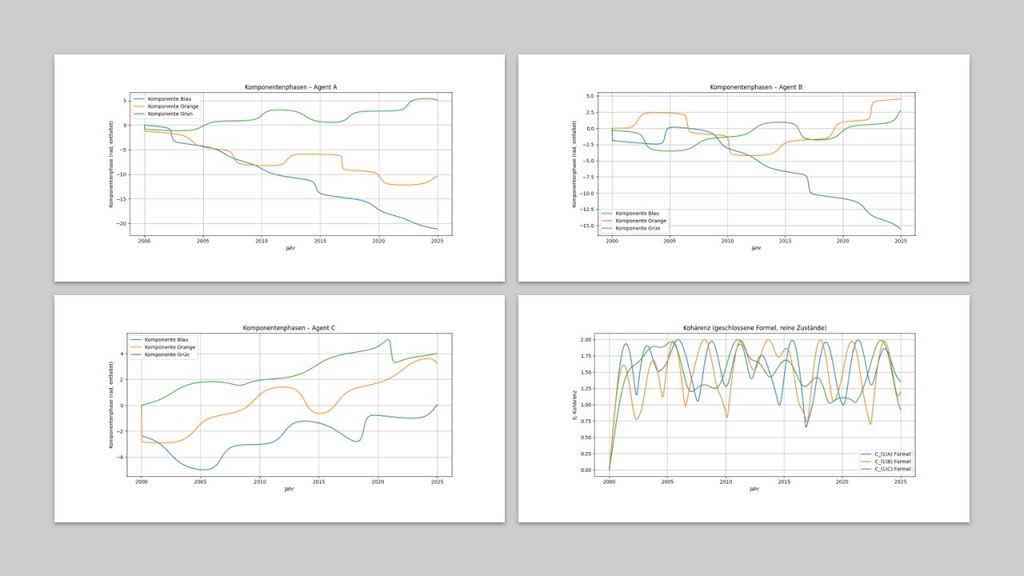
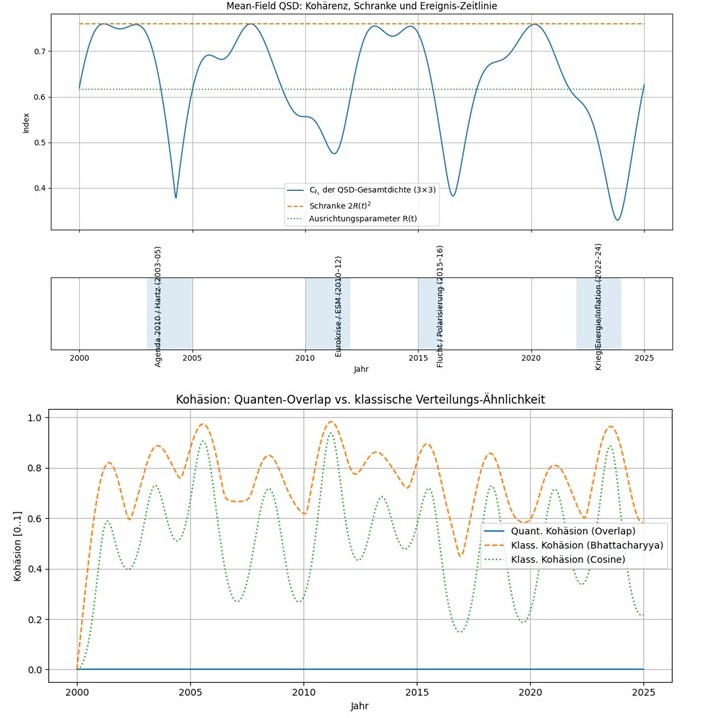












![\begin{equation*}R(t) = |\mu(t)| \in [0,1].\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-dd21d58be6611018b49c4d8a014b8cac_l3.png "Rendered by QuickLaTeX.com")


![\begin{equation*}C_{\ell_1}(t) = R(t)^2 \left[ \left(\sum_{i=1}^3 |\hat{\mu}_i(t)| \right)^2 - 1 \right].\end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-c8886a9edcc5cc3fe04e67abeab1fb49_l3.png "Rendered by QuickLaTeX.com")










![\[\lambda^{1} =\begin{pmatrix}0 & 1 & 0\\1 & 0 & 0\\0 & 0 & 0\end{pmatrix},\quad\lambda^{2} =\begin{pmatrix}0 & -i & 0\\i & 0 & 0\\0 & 0 & 0\end{pmatrix},\quad\lambda^{3} =\begin{pmatrix}1 & 0 & 0\\0 & -1 & 0\\0 & 0 & 0\end{pmatrix},\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-61886a3135e7da106fae1f271735bb81_l3.png "Rendered by QuickLaTeX.com")
![\[\lambda^{4} =\begin{pmatrix}0 & 0 & 1\\0 & 0 & 0\\1 & 0 & 0\end{pmatrix},\quad\lambda^{5} =\begin{pmatrix}0 & 0 & -i\\0 & 0 & 0\\i & 0 & 0\end{pmatrix},\quad\lambda^{6} =\begin{pmatrix}0 & 0 & 0\\0 & 0 & 1\\0 & 1 & 0\end{pmatrix},\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-4a3ae451c0b0e80bc022bff5b1cc3055_l3.png "Rendered by QuickLaTeX.com")
![\[\lambda^{7} =\begin{pmatrix}0 & 0 & 0\\0 & 0 & -i\\0 & i & 0\end{pmatrix},\quad\lambda^{8} =\frac{1}{\sqrt{3}}\begin{pmatrix}1 & 0 & 0\\0 & 1 & 0\\0 & 0 & -2\end{pmatrix}.\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-5ea2754eaec3e279343e6681bbbcf5ba_l3.png "Rendered by QuickLaTeX.com")
![\[\text{tr}[\lambda_a] = 0, \quad a = 1, 2, \ldots, 8\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-2beb2b7e44ea55d796b2e664ac78d8ce_l3.png "Rendered by QuickLaTeX.com")
![\[\text{tr}[\lambda_a^\dagger \lambda_b] = 2\delta_{ab}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-502be77dd1112326159a6d27c1c6f4c9_l3.png "Rendered by QuickLaTeX.com")
![\[\sum_{a=1}^{8} \lambda_a^{ij} \lambda_a^{kl} = 2\left(\delta_{il}\delta_{jk} - \frac{1}{3}\delta_{ij}\delta_{kl}\right)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-a277b5c85ca431ce84ca5f8a72605793_l3.png "Rendered by QuickLaTeX.com")
![\[[\lambda_a, \lambda_b] = \lambda_a \lambda_b - \lambda_b \lambda_a = 2i\sum_{c=1}^{8} f_{abc}\lambda_c\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-5bf2675d833cbb9b6306adf41757d44a_l3.png "Rendered by QuickLaTeX.com")
 , die ungleich 0 sind:
, die ungleich 0 sind:![\[f_{123} &= 1\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-c65eaee6102e806747aab0fb28eaab70_l3.png "Rendered by QuickLaTeX.com")
![\[f_{147} &= f_{165} = f_{246} = f_{257} = \frac{1}{2}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-bef8e72dab5052ed765e5d231fb8a581_l3.png "Rendered by QuickLaTeX.com")
![\[f_{345} &= f_{367} = \frac{1}{2}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-cb41bb9db2c2194aaf44e9cae4210f64_l3.png "Rendered by QuickLaTeX.com")
![\[f_{458} &= f_{678} = \frac{\sqrt{3}}{2}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-77d2e35b3b7c62f95df5c49bd9c98919_l3.png "Rendered by QuickLaTeX.com")

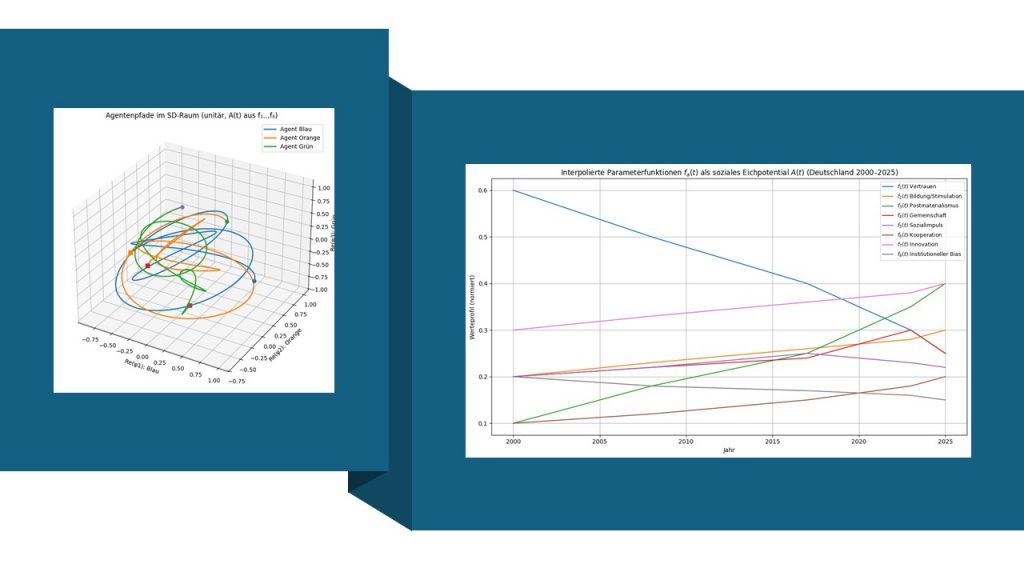
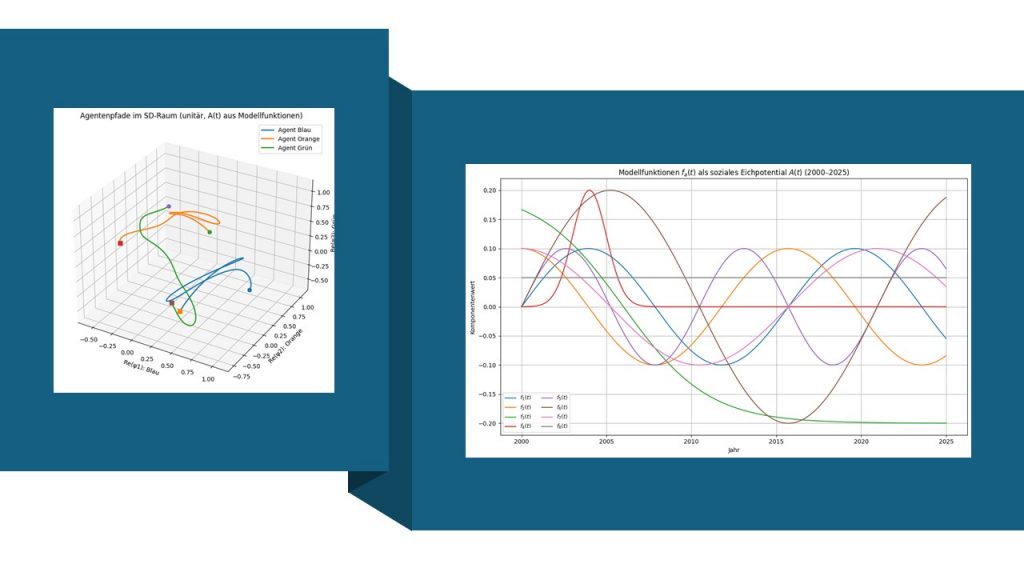
 . Diese Funktionen modellieren zeitabhängige Ereignisse oder Impulse, z. B. Führungswechsel, Krisen oder Höhepunkte von Team-Workshops. Jeder Term
. Diese Funktionen modellieren zeitabhängige Ereignisse oder Impulse, z. B. Führungswechsel, Krisen oder Höhepunkte von Team-Workshops. Jeder Term  kann als soziale „Kraft“ gelesen werden, die die Wertevektoren der Teammitglieder in Richtung des jeweiligen Meme-Übergangs zieht. Die Variable
kann als soziale „Kraft“ gelesen werden, die die Wertevektoren der Teammitglieder in Richtung des jeweiligen Meme-Übergangs zieht. Die Variable  etwa erzeugt einen weichen, epochalen Werte-Shift um
etwa erzeugt einen weichen, epochalen Werte-Shift um  .
.  , ist also ein kurzer, starker Impuls um
, ist also ein kurzer, starker Impuls um  , der eine Retrospektive oder besondere Intervention symbolisieren könnte. Gemeinsam definieren diese acht Moden den vollständigen nicht-abelschen Wertzirkulationszyklus.
, der eine Retrospektive oder besondere Intervention symbolisieren könnte. Gemeinsam definieren diese acht Moden den vollständigen nicht-abelschen Wertzirkulationszyklus.![\[A(t)=\sum_{a=1}^{8}f_{a}(t)\,\lambda^{a},\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-fc0f91fdc2315f34001f43d0d2c0ad00_l3.png "Rendered by QuickLaTeX.com")
![\[f_1(t) = 0.1 \sin(0.4t)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-3de3fd6a7105e9bfb56f7f8b6b177d13_l3.png "Rendered by QuickLaTeX.com")
![\[f_2(t) = 0.1 \cos(0.4t)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-5a6ef594471691a59c7c1b7c8de3d3e4_l3.png "Rendered by QuickLaTeX.com")
![\[f_3(t) = -0.2 \tanh(0.2(t - 6))\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-5e22662396c6a2cefe6cdcedb39966af_l3.png "Rendered by QuickLaTeX.com")
![\[f_4(t) = 0.2 \exp\left(-\frac{(t-4)^2}{2}\right)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-4bae6bd1df41559bf291e28e28dfb878_l3.png "Rendered by QuickLaTeX.com")
![\[f_5(t) = 0.1 \sin(0.6t)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-7f45b2a10b74060f7b14f890f244a67f_l3.png "Rendered by QuickLaTeX.com")
![\[f_6(t) = 0.2 \sin(0.3t)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-151d2bc50a32d759a7ec228092d51b63_l3.png "Rendered by QuickLaTeX.com")
![\[f_7(t) = 0.1 \cos(0.3t)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-8121d8ebefc5010db69a6eedd7d95076_l3.png "Rendered by QuickLaTeX.com")
![\[f_8(t) = 0.05\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-174a90f87cb236f008625f997c9cb88b_l3.png "Rendered by QuickLaTeX.com")
 steuert die unitäre Entwicklung der Team-Wellenfunktionen. Er wird direkt proportional zum Feld
steuert die unitäre Entwicklung der Team-Wellenfunktionen. Er wird direkt proportional zum Feld  . Im physikalischen Analogon ist
. Im physikalischen Analogon ist  der Energieoperator; hier ist es ein dimensionsloser sozialer Potential-Operator. Eine Hamilton-Dynamik ohne Dissipation ist vollständig reversibel. Durch
der Energieoperator; hier ist es ein dimensionsloser sozialer Potential-Operator. Eine Hamilton-Dynamik ohne Dissipation ist vollständig reversibel. Durch  bilden sich werteorientierte Team-Zustände entlang eines Werte-Pfads.
bilden sich werteorientierte Team-Zustände entlang eines Werte-Pfads. ![\[H_{\mathrm{coll}}(t)=g\,A(t).\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-f52a23379f10cfbf1e1af4b1887fedb0_l3.png "Rendered by QuickLaTeX.com")
 . Der Term
. Der Term ![-\tfrac{i}{\hbar}[H,\rho]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-a910021a441044cd7919c5ce74b652b4_l3.png "Rendered by QuickLaTeX.com") ist die reversible, unitäre Advektion im Wertefeld (Advektion: ‚Transport‘ der Agenten duch das soziale Feld). Die Summe über die Lindblad-Operatoren
ist die reversible, unitäre Advektion im Wertefeld (Advektion: ‚Transport‘ der Agenten duch das soziale Feld). Die Summe über die Lindblad-Operatoren  modelliert dissipative Prozesse durch den Ziel-Attraktor und den Dephasing-Operator. Jeder
modelliert dissipative Prozesse durch den Ziel-Attraktor und den Dephasing-Operator. Jeder  -Term überträgt Population in bestimmte Zielzustände. Die Anticommutator-Anteile
-Term überträgt Population in bestimmte Zielzustände. Die Anticommutator-Anteile  stellen den Populationsverlust korrekt sicher. Die Ableitung nach
stellen den Populationsverlust korrekt sicher. Die Ableitung nach ![\[\frac{d\rho}{dt}=-\frac{i}{\hbar}[H_{\mathrm{coll}},\rho]+\sum_{\ell}\Bigl(L_{\ell}\,\rho\,L_{\ell}^{\dagger}-\tfrac12\{L_{\ell}^{\dagger}L_{\ell},\rho\}\Bigr).\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-215e5c523ca13de66760bd221b540011_l3.png "Rendered by QuickLaTeX.com")
![\[[H, \rho] = H\rho - \rho H\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-b70a35de8a6f836fb524e51d97232ccd_l3.png "Rendered by QuickLaTeX.com")
![\[\{A, B\} = A B + B A\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-b697396520fb299cdbf797f6aadf3d35_l3.png "Rendered by QuickLaTeX.com")
![\[|\psi_1(0)\rangle = |0\rangle = \begin{pmatrix} 1 \\ 0 \\ 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-a66a9782ead555884e01735cab957ba4_l3.png "Rendered by QuickLaTeX.com")
![\[|\psi_2(0)\rangle = |1\rangle = \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-9712ce2572ad23b04f2ba185a5f52157_l3.png "Rendered by QuickLaTeX.com")
![\[|\psi_3(0)\rangle = |2\rangle = \begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-104a7c5df2db5918ceb416c1fd80622e_l3.png "Rendered by QuickLaTeX.com")
![\[\rho(0)\;=\;|\psi(0)\rangle\langle\psi(0)|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-f3fd073736d894ded8f8c0be7f55f141_l3.png "Rendered by QuickLaTeX.com")
![\[Agent A: \rho_A(0)=|0\rangle\langle 0| = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-317631f3631e5b7f6b8eb811ac57a873_l3.png "Rendered by QuickLaTeX.com")
![\[Agent B: \rho_B(0)=|1\rangle\langle 1| = \begin{pmatrix} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-d5cca2f8f4b25d79a8a37ee173c137cf_l3.png "Rendered by QuickLaTeX.com")
![\[Agent C: \rho_C(0)=|2\rangle\langle 2| = \begin{pmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 &1\end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-c4b80ab9adcfe0236591e034bfc10e9c_l3.png "Rendered by QuickLaTeX.com")
 und
und 
![\[L_{\rm goal} \;=\;\sqrt{\kappa}\;P_{\rm goal},\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-719bdce37527ebadd993744a62ba378d_l3.png "Rendered by QuickLaTeX.com")
![\[P_{\rm goal} = |\Phi_{\rm goal}\rangle\langle\Phi_{\rm goal}|,\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-52102db04d5a18e083a6c2c7f542e563_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(i,j)} = \sqrt{\gamma} |i\rangle\langle j|,\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-f555be0dc98491071d7779b441496701_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(0,1)} &= \sqrt{\gamma} |0\rangle\langle 1|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-ced5cc5549333ebf82e0ed6bce8790b2_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(0,2)} &= \sqrt{\gamma} |0\rangle\langle 2|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-dc6def11c2e01f943e2fc9dac0daf6eb_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(1,0)} &= \sqrt{\gamma} |1\rangle\langle 0|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-6c095a74774b8ea1d51ecc25f4a7f311_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(1,2)} &= \sqrt{\gamma} |1\rangle\langle 2|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-77cb2429b03e21d8d9af749cd6cd1fc1_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(2,0)} &= \sqrt{\gamma} |2\rangle\langle 0|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-fdef2ff7602a64ad4df01918b2f4e97c_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(2,1)} &= \sqrt{\gamma} |2\rangle\langle 1|\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-69c2d2829be7091ddec0dcea1a4f3e0b_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(0,1)} = \sqrt{\gamma} \begin{pmatrix} 0 & 1 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-1c2296bd8e958ccb6840e9087062fafd_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(0,2)} = \sqrt{\gamma} \begin{pmatrix} 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-345ea3d9f30ed1b0de17ee03ba197244_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(1,0)} = \sqrt{\gamma} \begin{pmatrix} 0 & 0 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-6c95de26445cc6d58cabf21fcaaa1275_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(1,2)} = \sqrt{\gamma} \begin{pmatrix} 0 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-9dc218cd06d777f39f56e734766484ae_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(2,0)} = \sqrt{\gamma} \begin{pmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 1 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-7652b5a0fd5f03d5c81b08da83d3f6a8_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{deph}}^{(2,1)} = \sqrt{\gamma} \begin{pmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 1 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-a7359b8da327019f283ee0d96531f328_l3.png "Rendered by QuickLaTeX.com")
![\[|\Phi_{\rm goal}\rangle = \begin{pmatrix} 1 \\ 0 \\ 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-f482d01bdf575c09da0c743fdc9acedc_l3.png "Rendered by QuickLaTeX.com")
![\[P_{\text{goal}} = |\Phi_{\rm goal}\rangle\langle\Phi_{\rm goal}| = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix}\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-660b822e9328fb41729db5a2a50d050a_l3.png "Rendered by QuickLaTeX.com")
 ist eine geometrische Phase, die nur aus der unitären Schleife entsteht. Der Pfad-Ordered Exponential-Term
ist eine geometrische Phase, die nur aus der unitären Schleife entsteht. Der Pfad-Ordered Exponential-Term  fasst alle infinitesimalen Unitärschritte entlang des geschlossenen Pfads zusammen.
fasst alle infinitesimalen Unitärschritte entlang des geschlossenen Pfads zusammen.  stellt sicher, dass nicht-kommutierende Hamiltonians in richtiger Reihenfolge multipliziert werden. Das Argument dieses Matrixelements gegen
stellt sicher, dass nicht-kommutierende Hamiltonians in richtiger Reihenfolge multipliziert werden. Das Argument dieses Matrixelements gegen  liefert die geometrische Phase. Ein nicht-Null-Ergebnis weist auf topologisch nicht-triviale Schleifen hin.
liefert die geometrische Phase. Ein nicht-Null-Ergebnis weist auf topologisch nicht-triviale Schleifen hin.![\[\gamma_{\mathrm{Berry}}=\arg\Bigl\langle\psi(0)\Bigm|\mathcal{P}\exp\!\Bigl(-\tfrac{i}{\hbar}\int_{0}^{T}H_{\mathrm{coll}}(t)\,dt\Bigr)\Bigm|\psi(0)\Bigr\rangle.\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-3c76af0e164c4560d6271799e9c1e960_l3.png "Rendered by QuickLaTeX.com")

![\[\phi_{\text{Berry}} = \sum_{n=0}^{N-1} \arg\langle\psi(t_n)|\psi(t_{n+1})\rangle\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-379fea845901c7a4b1983526c6031f68_l3.png "Rendered by QuickLaTeX.com")
 ist das Argument des Skalarprodukts von Anfangs- und Endzustand. Sie enthält beide unitäre und dissipative Effekte und misst die offene Holonomie. Ein Wert 0 bedeutet phasengleiche Ausrichtung. Ein nicht-Null-Wert zeigt, dass die Endzustände einen phasenmäßigen Versatz zum Anfang haben. Die Funktion
ist das Argument des Skalarprodukts von Anfangs- und Endzustand. Sie enthält beide unitäre und dissipative Effekte und misst die offene Holonomie. Ein Wert 0 bedeutet phasengleiche Ausrichtung. Ein nicht-Null-Wert zeigt, dass die Endzustände einen phasenmäßigen Versatz zum Anfang haben. Die Funktion  extrahiert genau diese Phase.
extrahiert genau diese Phase.




