In diesem Blog-Beitrag beschreibe ich meine weiteren Erfahrungen zur Modellierung und Programmierung eines Collective Mind Agent Based Models (CM ABM).
Anders als beim Blog-Beitrag vom Februar 2023 benutze ich als ‚Erweiterung‘ meiner kognitiven Fähigkeiten chatGPTplus, also die Bezahlversion von chatGPT auf der Basis von GPT-4. Außerdem soll dieses Mal ein dynamisches ABM entwickelt werden, das auf MESA Python beruht und die zeitliche Entwicklung eines Team Collective Mind‘s modelliert.
Der Titel (Collective Intelligence)**2, also Collective Intelligence zum Quadrat, weist daraufhin, dass es in diesem Beitrag in mehrfacher Hinsicht um Collective Intelligence geht: Ich benutze zum einen unserer aller Collective Intelligence, die in GPT-4 trainiert vorliegt und zum anderen die hybride Collective Intelligence von GPT-4 und mir. Außerdem ist ein CM ABM ein Team Collective Intelligence Modell.
Vor zwei Wochen habe ich mit der Entwicklung des CM ABM begonnen, indem ich chatGPTplus eine Aufgabenstellung als Prompt eingab. Diese anspruchsvolle Aufgabenstellung ist weiter unten im Anhang dieses Beitrages zu finden. Meine Erwartung war nicht, dass chatGPTplus diese Aufgabenstellung sofort ohne Kommunikation mit mir umsetzen kann. Jedoch ist meine Erfahrung zur ‚Erweiterung‘ meiner kognitiven Fähigkeiten durch chatGPTplus derart positiv, dass diese Collective Intelligence Erfahrung, bestehend aus AI und Mensch, mehr als nur einmal bei mir Gänsehaut erzeugte. – Der Zuwachs an Geschwindigkeit sowie wissenschaftlicher Kreativität und Python Kompetenz liegt deutlich näher am Faktor 100 als am Faktor 2!
Ich fasse meine Collective Intelligence Erfahrungen mit chatGPTplus zusammen:
- ChatGPTplus hat die unten stehende Aufgabenstellung mit ersten Ideen zur Ziel-Hierarchie und deren Ähnlichkeitsvermessung umgesetzt. Es fehlten lediglich vollständig die Projekttypisierung und die Stakeholder. – Eine Einbettung von chatGPTplus in die Agentenlogik habe ich nachträglich gestrichen, da dies zu kompliziert für mich wurde.
- Zur Verfeinerung und Verbesserung der Aufgabenstellung war es notwendig, im Dialog mit chatGPTplus das Python-Programm weiter zu entwickeln. Die Kommunikation mit chatGPTplus entspricht hierbei der Kommunikation mit einem hochintelligenten Experten: Die chatGPTplus Expertise in den Bereichen Python, Mathematik und spezifischer Modellierungskompetenz übersteigt meine bei weitem. Hierbei habe ich die Erfahrung gemacht, dass die Verwendung von Ratgebern à la ‚Wie gestalte ich die chatGPT Prompteingabe optimal?‘ für mich keinen Sinn macht. – Meines Erachtens genügt es, die Prompts so zu erstellen, dass ein menschlicher Experte:inn sie nachvollziehen kann. – Dies genügt, um eine gelungene Kommunikation mit super Ergebnissen zu erhalten!
- Auf der Basis der Kommunikation habe ich von chatGPTplus Pythoncode erstellen lassen. Dieser Code wurde in einer Colab-Umgebung laufen gelassen. Manchmal enthielt dieser Code einen Fehler, manchmal habe ich einen Fehler eingebaut, da ich noch Veränderungen am Code vorgenommen habe. Die Rückmeldung des vollständigen Fehlers als Prompt hat immer zum direkten Auffinden des Fehlers durch chatGPTplus geführt.
- Die Analyse der Ergebnis-Daten zeigte den ein oder anderen Mangel in der Modellierungslogik auf. Eine textuelle Beschreibung der Ergebnis-Daten als Prompt führte immer innerhalb weniger Schritte zur Behebung dieses Mangels.
- Es gibt eine Unzulänglichkeit in der Zusammenarbeit mit chatGPTPlus, die ich nicht beheben konnte und durch einen Workaround umgehen musste: In den ersten Tagen der Bearbeitung der Aufgabenstellung stellte ich mit fortschreitender Zeit immer häufiger fest, dass chatGPTplus vorherige gute Ergebnisse vergessen hatte. Dies führte dazu, dass an Stellen, die ich als abgeschlossen und korrekt betrachtet habe, plötzlich anderer Code und nicht selten zur Aufgabenstellung nicht passender Code auftauchte. So geschah es zum Beispiel, dass die Ziel-Hierarchie Berechnung verändert wurde oder dass das 7-köpfige Team wie Stakeholder behandelt wurde, also die MBTI Typ-Zuordnung zufällig erfolgte und nicht nach dem gewünschten Schema der Aufgabenstellung. Dieses ‚Fehlverhalten‘ tauchte umso häufiger auf, je länger die Modellierung der Aufgabenstellung dauerte. Das ‚Fehlverhalten‘ wurde noch verstärkt, wenn ich chatGPTPlus darauf hinwies, dass der Code an einer bestimmten Stelle falsch ist. Dann versuchte das System ein völlig anderes Modellverhalten zu erstellen. Am vierten Tag nach insgesamt ca. 4-5 Std. chatGPTplus Interaktion, habe ich mich zu folgendem Workaround entschlossen: Ich habe das gesamte Programm selbst immer wieder integriert und alle Änderungen selbst in das gesamte Programm eingegeben. Um erwünschte neue Modellierungs-Änderungen zu erhalten, habe ich chatGPTplus lediglich eine konkrete überschaubare aber durchaus schwierige Teilaufgabe gegeben. Wenn Änderungen größere Auswirkungen im Code hatten oder mehr als ca. 1 Std. Interaktion verstrichen war, habe ich den gesamten Code wieder als Prompt eingegeben. chatGPTplus hat sich hierfür meistens bedankt 😉: Es sei hilfreich, den gesamten Code zur Verfügung zu haben. Zusammenfassend interpretiere ich dieses Verhalten von chatGPTplus dahingehend, dass chatGPTplus über kein Kurzzeitgedächtnis verfügt.
Und nun zu den Ergebnissen. – Auf Nachfrage stelle ich gerne den CM ABM Code als Colab-Jupyter Notebook zur Verfügung. Ich beschreibe hier das Modell und diskutiere einige Ergebnisse:
Das Modell basiert auf der ABM Bibliothek MESA-Python [1]. Die Teammitglieder eines Teams und die Stakeholder werden als Agenten unterschiedlichen Typs behandelt. Die Agenten werden über eine MBTI Typologie mit Persönlichkeits-Polwahrscheinlichkeit charakterisiert (siehe Anhang). Alternativ könnte auch das Standardmodell der Psychologie, das Big Five Persönlichkeitsmodell (NEO-PI-R), verwendet werden. Das Persönlichkeitsmodell lässt sich auch um Werte/Motive oder Glaubenssätze erweitern.
Entsprechend der Aufgabenstellung haben die Teammitglieder fest vorgegebene Persönlichkeiten. Die Stakeholder erhalten ihre Persönlichkeit gemäß der globalen statistischen Verteilung der MBTI Persönlichkeiten.
Jeder Agent verfügt über eine eigene dreiteilige Ziel-Hierarchie. Die dreiteilige Ziel-Hierarchie entspricht dem einfachsten Collective Mind Schema, das wahlweise als Teil eine Dilts Pyramide angesehen werden kann oder als persönliche Story Map oder als OKR [2, 3]. Die Agenten verändern ihre Ziel-Hierarchie in Abhängigkeit ihrer individuellen MBTI Präferenzen, also der individuellen Persönlichkeits-Polwahrscheinlichkeiten. Zum Beispiel ändert ein extrovertierter NT-Typ durch Kommunikation vornehmlich die oberste Ebene der Ziel-Hierarchie – ein introvertierter NT-Typ tut dies auch, jedoch nicht so oft.
Die dreiteilige Ziel-Hierarchie besteht aus alphanumerischen Zeichenketten einer bestimmten Länge. Diese Zeichenketten werden am Anfang, wenn die Simulation beginnt, per Zufall ermittelt. Der Inhalt der Ziel-Hierarchie sollte keine entscheidende Rolle für das Auftauchen prinzipiell emergenter Systemeigenschaften haben. Dies trägt der langjährigen Erfahrung aus anderen ABM Modellen und deren Systemeigenschaften Rechnung [4]. – Die Mathematik ist vielleicht doch viel entscheidender als der Inhalt!
Die Änderung der Ziel-Hierarchien erfolgt zufällig und paarweise zwischen zufällig ausgewählten Agenten. Das Ändern der Ziel-Hierarchien durch Kommunikation ist eine Form von Lernen und wird über einen Lernparameter alphaT für Teammitglieder und alphaS für Stakeholder eingestellt. Typischerweise ist alphaS kleiner gleich alphaT, da die Interaktion im Team zu einem besseren Lernen führt.
Zusätzlich erhalten die Stakeholder weniger Möglichkeiten ihre Ziel-Hierarchie zu ändern. Dies erfolgt über eine gesondert einzustellende Zeit-Steprate: Die Stakeholder erhalten zum Beispiel eine um den Faktor 200 reduziert Möglichkeit ihre Ziel-Hierarchie zu ändern. Dies trägt der Annahme Rechnung, dass die Stakeholder untereinander weniger oft kommunizieren und auch weniger oft mit den Teammitgliedern.
In der Sprache der Theorie der Selbstorganisation ergeben sich damit folgende Parameter:
Rahmenparameter: Anzahl und Persönlichkeit der Teammitglieder, Anzahl und Persönlichkeit der Stakeholder, reduzierte Steprate für die Stakeholder
Kontrollparameter: alphaT, alphaS
Ordnungsparameter: dreiteilige Ziel-Hierarchie, am Anfang gefüllt mit zufällig ermittelten Zeichenfolgen der Länge k. Die Ziel-Hierarchien werden gemäß MBTI-Profil geändert. Die Ähnlichkeiten der Ziel-Hierarchien wird über die Ratcliff-Obershelp Funktion bestimmt [5].
Die nachfolgenden Abbildungen zeigen jeweils links das resultierende emergente Systemverhalten, gemessen über die mittlere Ähnlichkeit aller Ziel-Hierarchien getrennt nach den Teammitgliedern und den Stakeholdern.
Jeweils rechts ist die Performance des Teams bzw. der Stakeholder zu sehen. Die Performance ist keine emergente Eigenschaft sondern wird über folgende Formel aus der Ähnlichkeit ermittelt: Performance=(Anzahl der Agenten eines Typs* mittlere Ähnlichkeit der Ziel-Hierarchien des Agententyps)**2. Diese Formel basiert auf folgender Betrachtung: Es werden alle bilateralen Verbindungen innerhalb einer Gruppe (Teammitglieder, Stakeholder) aufsummiert – gewichtet mit der mittleren Ähnlichkeit der Ziel-Hierarchien innerhalb der Gruppe. Wie man weiter untern sehen kann, folgt die Performance der Ähnlichkeit, natürlich erhöht um einen Faktor, der die Anzahl der Gruppenmitglieder berücksichtigt.
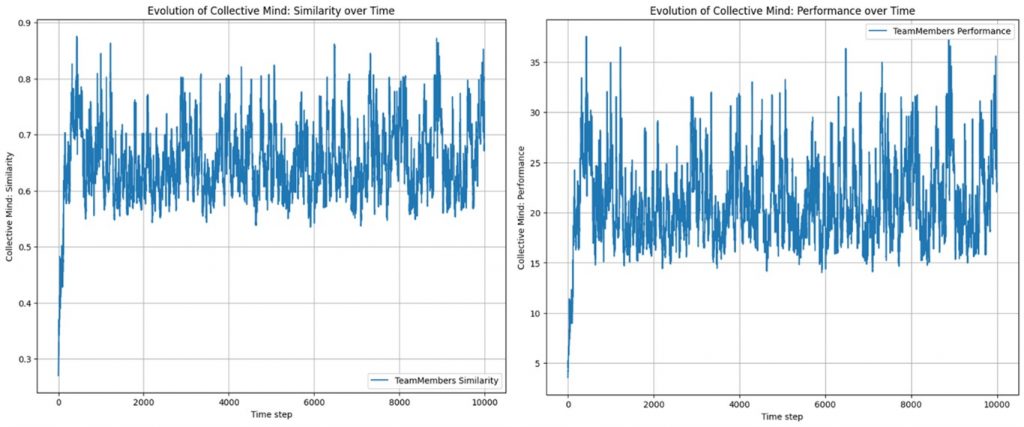
Rahmenparameter: 7 Teammitglieder mit definierter MBTI-Persönlichkeit, keine Stakeholder
Kontrollparameter: Lernparameter Teammitglieder alphaT = 0.1
Ordnungsparameter: Ziel-Hierarchie-Ähnlichkeit mit der Ratcliff-Obershelp Funktion berechnet, ermittelt aus den dreiteiligen Ziel-Hierarchien mit jeweils am Anfang zufällig generierter Zeichenfolge von k = 100 Zeichen pro Ebene
Wie man aus Abbildung 1 sehen kann, steigt die Ähnlichkeit recht schnell auf Werte von über 0,7 und die Teamperformance damit auf Werte von 21 und mehr, bei 7 Teammitgliedern. – Der Synergieeffekt beträgt also 3 und mehr!
Selbstverständlich genügt diese Aussage, wie auch die nachfolgend abgeleiteten Aussagen, keinen wissenschaftlichen Ansprüchen. Um wissenschaftlichen Ansprüchen zu genügen, müsste ich u.a. ggf. 10.000 und mehr Durchläufe errechnen lassen, um dann auf dieser Basis eine statistische Auswertung aller errechneten Werte zu erhalten. Hierauf verzichte ich, da dies meine (derzeitigen) Möglichkeiten übersteigt. Abbildung 2 zeigt den Einfluss der Stakeholder auf das Team. Die Anzahl der Stakeholder entspricht der Anzahl der Teammitglieder, ist also 7. Die Fähigkeit der Stakeholder ein Collective Mind auszubilden, bestimmt auch die Fähigkeit des Teams ein Collective Mind auszubilden: Die Stakeholder ziehen die Leistungsfähigkeit des Teams runter, obwohl die Lernrate der Stakeholder genau so groß ist wie diejenige der Teammitglieder. – Die Interaktionsrate der Stakeholder ist jedoch um den Faktor 200 geringer als die Interaktionsrate der Teammitglieder.
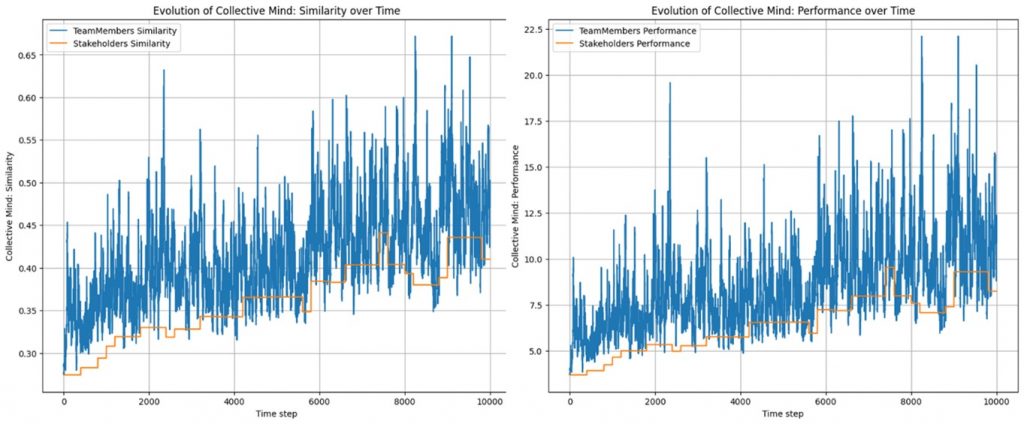
Rahmenparameter: 7 Teammitglieder mit definierter MBTI-Persönlichkeit, 7 Stakeholder mit zufälliger MBTI-Persönlichkeit, Abschottung des Teams und zwischen den Stakeholdern durch 200-fach geringere Steprate als im Team selbst.
Kontrollparameter: Lernparameter Teammitglieder alphaT= 0.1, Lernparameter Stakeholder alphaS= 0.1
Ordnungsparameter: Ziel-Hierarchie-Ähnlichkeit mit der Ratcliff-Obershelp Funktion berechnet, ermittelt aus den dreiteiligen Ziel-Hierarchien mit jeweils am Anfang zufällig generierter Zeichenfolge von k = 100 Zeichen pro Ebene
Abbildung 3 zeigt eine Simulation mit 21 Stakeholdern und einer zehnmal geringeren Lernrate der Stakeholder (diese Simulation benötigt in der Colab Umgebung ohne spezielle Hardware ca. 3-4 Stunden elapsed time). Die Ziel-Hierarchie-Ähnlichkeit der Stakeholder sinkt weiter ab und zieht das Collective Mind des Teams mit sich weiter runter. Die Stakeholder wie das Team zeigen jetzt eine Performance die weiter unterhalb der Anzahl der Teammitglieder bzw. der Stakeholder liegt.
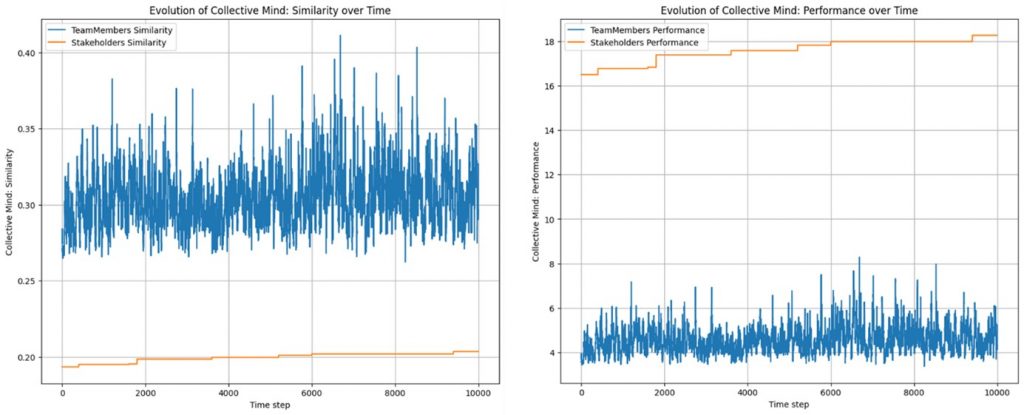
Rahmenparameter: 7 Teammitglieder mit definierter MBTI-Persönlichkeit, 21 Stakeholder mit zufälliger MBTI-Persönlichkeit, Abschottung des Teams und zwischen den Stakeholdern durch 200-fach geringere Steprate als im Team selbst.
Kontrollparameter: Lernparameter Teammitglieder alphaT= 0.1, Lernparameter Stakeholder alphaS = 0.01
Ordnungsparameter: Ziel-Hierarchie-Ähnlichkeit mit der Ratcliff-Obershelp Funktion berechnet, ermittelt aus den dreiteiligen Ziel-Hierarchien mit jeweils am Anfang zufällig generierter Zeichenfolge von k = 100 Zeichen pro Ebene
Was sagt uns dies?
Es sieht so aus, als wenn die hybride Collective Intelligence von chatGPTplus und mir, ein Modell gefunden hätte, das emergentes Collective Mind Verhalten eines Teams in Interaktion mit Stakeholdern recht gut abbildet. – Dies ist ein weiterer Schritt in Richtung von Management 5.0, der Synergie von AI und Management 4.0.
Anhang: Erst-Aufgabenstellung für GPT4/ChatGPTplus
Die Aufgabenstellung zur Digitalen Transformation des Unternehmens KüchenManufaktur verwende ich in meinen Management 4.0 Trainings, um eine Scrum Simulation durchzuführen und eine Ziel-Hierarchie zu erstellen. Die zugrundeliegende Theorie hierzu ist in [2], [3] zu finden.
Erzeuge ein Agent Based Model (ABM) in der Programmiersprache Python, z. B. mittels MESA Python, für ein Team von 7 Teammitgliedern und 100 Stakeholdern. Die 7 Teammitglieder und die 100 Stakeholder sind Agenten im ABM. Die Teammitglieder und die 100 Stakeholder gehören zu dem Unternehmen KüchenManufaktur, das sogenannte Weiße Ware, also u.a. Herde, Kühlschränke und Gefrierschränke herstellt. Bisher hat das Unternehmen KüchenManufaktur diese Weiße Ware ohne große Digitalisierungsfunktionen hergestellt. Jetzt soll die Weiße Ware smart werden und als Life Style Produkt positioniert werden. Der Einsatz von smarter Technologie kann auch den Einsatz von AI oder ML beinhalten. Zum Beispiel könnte eine zukünftige Anforderung für einen Kühlschrank beinhalten, dass ‚er sich von alleine füllt‘. ‚Von alleine füllen‘ bedeutet, dass er über ein intelligentes Füllmanagement verfügt, das u.a. Zugriff auf Lebensmittellieferanten hat.
Es geht also um die Digitale Transformation des Unternehmens KüchenManufaktur. Die Digitale Transformation soll mittels eine Projektes durchgeführt werden. In einem ersten Schritt ist ein Konzept für die Digitale Transformation zu erstellen. Für diesen ersten Schritt ist das ABM mittels Python zu erstellen.
Die Aufgabe der Konzepterstellung typisieren wir als Projekt mittels des Diamantmodells: Das Projekt ist für KüchenManufaktur ein Projekt mit hohem Innovationsgrad. Nicht alle Stakeholder sind vom Sinn der Digitalen Transformation überzeugt und deshalb zeigen auch recht viele Stakeholder innere Widerstände gegen das Projekt. Deshalb sprechen wir von einem hohen Missionsgrad.- Das Team hat also viel Überzeugungsarbeit zu leisten. Der Kompliziertheitsgrad der neuen smarten Weißen Ware ist eher gering bis mittelgroß. Der Managementgrad ist mittel, da KüchenManufaktur innerhalb eines Jahres mit ersten smarten Produkten auf den Markt kommen möchte.
Die Persönlichkeiten der 7 Teammitglieder beschreiben wir mittels des MBTI, wobei die dominante Persönlichkeitsdimension des jeweiligen Teammitgliedes als Wahrscheinlichkeit angegeben wird. Wir nennen vereinfacht die jeweiligen Teammitglieder entsprechend ihrer MBTI Typologie und einer MBTI-Polwahrscheinlichkeit, also:
Teammitglied 1: ENTJ heißt: Extraversion = E = 0.8, Intuition = N = 0.8, Thinking = T = 0.6, Judging = J = 0.6
Teammitglied 2: INTJ heißt: Introversion = I = 0.8, Intuition = N = 0.7, Thinking = T = 0.7, Judging = J = 0.6
Teammitglied 3: ISFP heißt: Introversion = I = 0.6, Sensing = S = 0.7, Feeling = F = 0.7, Perceiving = P = 0.6
Teammitglied 4: ISTJ heißt: Introversion = I = 0.8, Sensing = S = 0.7, Thinking = T = 0.7, Judging = J = 0.9
Teammitglied 5: ESTJ heißt: Extraversion = E = 0.8, Sensing = S = 0.9, Thinking = T = 0.7, Judging = J = 0.6
Teammitglied 6: ISTP heißt: Introversion = I = 0.9, Sensing = S = 0.9, Thinking = T = 0.6, Perceiving = P = 0.6
Teammitglied 7: ISTJ heißt: Introversion = I = 0.7, Sensing = S = 0.6, Thinking = T = 0.6, Judging = J = 0.6
Die Stakeholder erhalten per Zufall eine Persönlichkeit gemäß MBTI.
Die Aufgabe der Konzepterstellung ist erledigt, wenn die 7 Teammitglieder, die das Konzept erstellen, eine gemeinsame Ziel-Hierarchie erstellt haben. Eine Ziel-Hierarchie besteht aus Informationseinheiten, die abstrakt oder detailliert sind. Eine Vision oder ein übergeordnetes Ziel bilden die oberste Ebene, es folgen darunter größere Informationseinheiten, die in weitere Informationseinheiten runtergebrochen werden. Im Agilen Management beginnt die Ziel-Hierarchie zum Beispiel mit einer Vision, gefolgt von Epics, die in Features zerlegt werden, die Features werden in User Stories zerlegt und diese wieder in Tasks und Tasks in Subtasks usw.
Für die Generierung der Informationseinheiten kann pro Teammitglied auf chatGPT zurückgegriffen werden
Um die Ziel-Hierarchie zu erstellen, tauschen die 7 Teammitglieder gemäß ihrer Persönlichkeitspräferenzen Informationseinheiten aus. Diese Informationseinheiten werden gemäß ihrer Präferenzen und der damit verbundenen Wahrscheinlichkeiten in die persönliche Ziel-Hierarchie aufgenommen.
Im ABM Model wird der Informationsaustausch in Zeitschritten durchgeführt. Wir definieren die Performance des Teams über die Ähnlichkeit der persönlichen Ziel-Hierarchien. Wenn alle persönlichen Ziel-Hierarchien identisch sind, sprechen wir von einem Collective Mind. Der Collective Mind kann durch die Kommunikation mit den Stakeholdern stabilisiert oder destabilisiert werden. Die Ähnlichkeit der Ziel-Hierarchien aller Stakeholder und der 7 Teammitglieder ist ein Maß für den Collective Mind im Team bzw. im Stakeholderkreis bzgl. der Digitalen Transformation.
Zeichne den Verlauf des Colletive Mind im Team und den Verlauf des Collective Mind für den Stakeholderkreis über die Zeit.
[1] Complexity Explorer (2023) MESA-Python Lecture, https://www.complexityexplorer.org/courses/172-agent-based-models-with-python-an-introduction-to-mesa/segments/17326, Santa Fe Institute, zugegriffen am 30.04.2023
[2] Oswald A, Köhler J, Schmitt R (2017) Projektmanagement am Rande des Chaos. 2. Auflage, Springer, Heidelberg, auch in englischer Sprache unter ‚Project Management at the Edge of Chaos‘ verfügbar.
[3] Köhler J, Oswald A. (2009) Die Collective Mind Methode, Projekterfolg durch Soft Skills, Springer Verlag
[4] Epstein J M, Axtell R (1996) Growing Artificial Societies – Social Science from the Bottom Up, The Brookings Institution, Washington D.C.
[5] Wikipedia (2023) Ratcliff-Obershelp Funktion, https://de.wikipedia.org/wiki/Gestalt_Pattern_Matching#:~:text=Gestalt%20Pattern%20Matching%2C%20auch%20Ratcliff,im%20Juli%201988%20im%20Dr.