Kurzfassung: Ein mathematisches Modell für kausale Emergenz wird auf die Vermessung der Emergenz sozialer Kommunikation, ein Collective Mind, angewendet. Die Gruppendynamik einer TV-Diskussion wird vermessen. Es wird gezeigt, wie die aus dieser Dynamik ermittelte Emergenz Führung, Coaching oder Moderation vorausschauend unterstützt. Mit Hilfe der Hybriden Collective Intelligence aus Mensch und Künstlicher Intelligenz/Maschine Learning wird ein Leadership Dashboard für die Gruppen- und Teamarbeit erstellen. Dieses Dashboard hebt Leadership auf eine neue Ebene der Professionalität.
Dieser Blog-Beitrag wurde in Hybrider Collective Intelligence mit Gemini Pro und Gemini (obiges Bild) erstellt
Der Begriff Emergenz ist einer der schillerndsten Begriffe in der Wissenschaft. Sehr viele Phänomene werden mit dem Begriff Emergenz oder mit emergent verbunden. Hier nur drei Beispiele: Die mikroskopischen Teilchenbewegungen eines Gases erzeugen auf Makro-Ebene Temperatur und Druck, die Neuronen unseres Gehirns erzeugen die emergente Eigenschaft des Bewusstseins, und eine Gruppe von Menschen verhält sich unter bestimmten Bedingungen wie ‚ein emergentes Ganzes‘, ein Collective Mind.
Emergenz entspricht damit der Aussage: ‚Das Ganze (Makro-Ebene) ist mehr als die Summe seiner Teile (Mikro-Ebene).‘ Selbstorganisation ist das Mittel, mit dem dieses Ganze erreicht wird.
Auch wenn es im Einzelnen sehr oft gelungen ist, diesen Übergang von der Mikro-Ebene auf die Makro-Ebene mathematisch zu beschreiben, so fehlte bis vor kurzem ein universeller, berechenbarer Rahmen dafür, was (kausale) Emergenz eigentlich genau ist. Vor kurzem bin ich auf die Arbeit von Rosas et al. [1] aufmerksam geworden. Diesen Autoren ist es gelungen, ein mathematisches Modell vorzulegen, das Emergenz informationstheoretisch schlüssig messbar macht.
Ihre Grundidee ist recht eingängig; die Umsetzung erfordert jedoch eine große Menge an mathematisch-informationswissenschaftlichem Wissen. Ich skizziere hier lediglich die Grundidee und verweise für die technischen Details auf die Anhänge 1 und 2. Meine Umsetzung interpretiert den abstrakten Formalismus aus [1] an diversen Stellen und wendet verschiedene Machine Learning (ML) Algorithmen an, um ihn direkt in den Kontext der Collective Mind Theorie zu überführen.
Zur Grundidee: Ein Computer besteht aus Hardware und Software. Die Hardware verkörpert die Mikro-Ebene und die Software verkörpert die Makro-Ebene. Die Software kann zwar nicht ohne die Hardware existieren, jedoch führen beide ein weitgehend unabhängiges ‚Leben‘. Eine Rechenoperation, wie die Addition zweier Zahlen, wird in der Software (Makro) ausgeführt und nutzt dafür sehr viele, ständig wechselnde Zustände der Hardware (Mikro). Die Zustände der Hardware und die der Software sind in einem gewissen Maße voneinander entkoppelt.
Diese informationelle Unabhängigkeit – man spricht von kausaler Geschlossenheit – kann man mit der Theorie aus [1] exakt vermessen. Dafür nutzt sie zwei theoretische Konstrukte: Eine  -Maschine bündelt vergangene System-Ebenen-Trajektorien, die exakt dieselbe Zukunftsvorhersage liefern, zu sogenannten „kausalen Zuständen“. Diese -Maschine ist die theoretische Abstraktion, die die Berechnungen einer System-Ebene beschreibt. Eine weitere Maschine, die v-Maschine, identifiziert die Zustände in der Vergangenheit der Mikro-Ebene, die einen tatsächlichen Unterschied für die Zukunft der Makro-Ebene machen.
-Maschine bündelt vergangene System-Ebenen-Trajektorien, die exakt dieselbe Zukunftsvorhersage liefern, zu sogenannten „kausalen Zuständen“. Diese -Maschine ist die theoretische Abstraktion, die die Berechnungen einer System-Ebene beschreibt. Eine weitere Maschine, die v-Maschine, identifiziert die Zustände in der Vergangenheit der Mikro-Ebene, die einen tatsächlichen Unterschied für die Zukunft der Makro-Ebene machen.
Kausale Emergenz liegt exakt dann vor, wenn ein makroskopischer Systemzustand eine höhere deterministische Vorhersagekraft über die Zukunft des Systems besitzt als das vollständige Wissen über alle seine mikroskopischen Einzelteile.
Anders ausgedrückt: Das System verhält sich nicht mehr nur als Summe seiner Teile („Bottom-up“), sondern das gewachsene Gesamtgebilde übernimmt die ursächliche Kontrolle über das Verhalten der Einzelteile („Top-down“).
Die Klassifizierung von System-Ebenen mittels Makro-, Meso- und Mikro-Ebene spielt in allen Wissenschaften – die sich mit Emergenz beschäftigen – eine große Rolle. In der Collective Mind Theorie (CMT) ist der Collective Mind ein emergenter Zustand auf Makro-Ebene: Der Collective Mind ist das gemeinsame Bewusstsein und Handeln eines Teams mit ausgeprägtem Wir-Gefühl. Er erzeugt per Selbstorganisation eine synergetische Leistung, die weit über die Leistung der Summe der Einzel-Leistungen der Teammitglieder hinausgeht bzw. hinausgehen kann. Die Teammitglieder selbst bilden die Mikro-Ebene.
Gleichzeitig benutzen wir in der CMT eine sogenannte Ziel-Hierarchie, die ebenfalls eine Dreiteilung aufweist. Diese Ziel-Hierarchie besteht aus den Ebenen Ziel-, Was- und Wie-Ebene und ist ein Operator, um einen Collective Mind herbeizuführen. In [2] haben wir gezeigt, dass diese inhaltlichen Ebenen, die zum Beispiel ein Projekt charakterisieren, zu den drei Team CMT-Ebenen korrespondieren. Der Collective Mind auf Makro-Ebene wird nur erreicht, wenn eine gemeinsame Ziel-Ebene, mit zum Beispiel gemeinsamer Vision und Mission, vorliegt.
Im vorliegenden Blog-Beitrag beschäftige ich mich nicht mit der inhaltlichen Ziel-Hierarchie, sondern ich möchte Algorithmen für eine Hybride Collective Intelligence aus Mensch und Künstlischer Intelligenz/Machine Learning (KI/ML) entwickeln, die auf den bisherigen Erkenntnissen der Attention Collective Mind Blog-Beiträge aufsetzt: Ziel ist es, dass diese Algorithmen aus KI und ML auf der Basis der Kommunikation im Team, Teamentwicklung verlässlich prognostizieren. Hierzu interpretiere ich die Theorie der kausalen Emergenz aus [1] im Kontext der bisherigen CMT.
Der entscheidende Punkt ist nun: Echte, messbare (Team-) Emergenz liegt nicht schon dann vor, wenn man diese Ebenen bilden kann. Kausale Emergenz existiert erst in dem Moment, in dem mathematisch bewiesen wird, dass das übergeordnete Makro-Regime (die Software) die Zukunft des Systems robuster und treffsicherer bestimmt als das exakte Wissen über alle einzelnen Bausteine (die Hardware). Genau dann hat das System kausale Autonomie erreicht und ich spreche von einem Collective Mind.
Ich übersetze die abstrakte Mathematik aus [1] in verfügbare Machine Learning Algorithmen (ML Algorithmen). Ich benutze wieder, wie in den vorherigen Blog-Beiträgen der Attention Collective Mind Reihe die Kommunikation eines Mitschnitts der TV-Sendung Markus Lanz. Die einzelnen Kommunikationsaussagen der Sprecher bezeichnete ich als Turns. Jeder Turn wurde in den Attention Collective Mind Blog-Beiträgen durch einen Valenz- und Disruption-Score gekennzeichnet.
Ich verwende folgende ML-Algorithmen (zur grundlegenden Mathematik siehe Anhang 1 und zu den CMT Ergebnissen siehe Anhang 2) :
-
Die
 -Maschine wird zum Decision Tree Regressor: Auf der Basis der 100 turns und der ermittelten Valenz und Disruption wird ein Entscheidungsbaum gebildet: Dieser durchsucht für jeden Turn die (acht ) vorausgehenden Turns nach den Turns, die jenen Turn voraussagen lassen. Die vorausgehenden Turns stellen die Features des Decision Tree Regressors dar: Valenz und Disruption die jeweilige Ausprägung. Aus den 100 turns werden mittels der so definierten epsilon-Maschine 19 kausale Zustände erzeugt. Diese 19 Zustände bilden die kausalen Zustände der Meso-Ebene: Aus den 100 turns der Mikro-Ebene ergeben sich auf Meso-Ebene lediglich 19 unterschiedliche kausal relevante Zustände.
-Maschine wird zum Decision Tree Regressor: Auf der Basis der 100 turns und der ermittelten Valenz und Disruption wird ein Entscheidungsbaum gebildet: Dieser durchsucht für jeden Turn die (acht ) vorausgehenden Turns nach den Turns, die jenen Turn voraussagen lassen. Die vorausgehenden Turns stellen die Features des Decision Tree Regressors dar: Valenz und Disruption die jeweilige Ausprägung. Aus den 100 turns werden mittels der so definierten epsilon-Maschine 19 kausale Zustände erzeugt. Diese 19 Zustände bilden die kausalen Zustände der Meso-Ebene: Aus den 100 turns der Mikro-Ebene ergeben sich auf Meso-Ebene lediglich 19 unterschiedliche kausal relevante Zustände. -
Die
-Maschine wird zum K-Means Clustering: Die im Decision Tree isolierten 19 Mikro-Zustände sind noch recht kleinteilig. Deshalb nutze ich im zweiten Schritt ein unüberwachtes K-Means Clustering. Ich gebe drei Makro-Zustände vor. Die Zahl drei für die Makro-Zustände ergibt sich als Ansatz aus den vorherigen Attention Collective Mind Analysen. Ich konnte beispielsweise den toxischen Identitätskampf (V0), die Sachdebatte (sachliche Kohärenz (V1)) und das Agenda-Setting (disruptive Neuausrichtung (V2)) in den Gesprächen erkennen. Die Benennung der Makro-Zustände ist nicht entscheidend, sondern lediglich, dass Valenz und Disruption eine klare Bedeutung für die drei Makro-Zustände haben (siehe Anhang 1 und 2). -
Der Emergenz-Beweis durch Mutual Information: Um die kausale Autonomie schlussendlich zu beweisen, nutzen wir einen informationstheoretischen Schätzer, den KSG-Algorithmus für die Messung der sogenannten ‚Kausalen Kraft‘. Erst wenn diese Mathematik zeigt, dass die gefundenen Makro-Regime die Zukunft des Gesprächs robuster vorhersagen als das genaue Wissen über die einzelnen Sprecher (Turns), haben wir einen emergenten Systemübergang: Der Collective Mind steuert dann die Kommunikation.
Welche Informationen stecken in der Meso-Ebene, dem Decison Tree?
Anhang 2 enthält eine Abbildung des Decision Tree und eine Liste der 19 relevanten Meso-Zustände der TV-Kommunikation
Der Baum verrät Kommunikationsstrukturen, also Kausalitäten, die dem menschlichen Auge in Echtzeit meist entgehen:
-
Die exakten Kipppunkte (Tipping Points): Der Baum enthält konkrete Schwellenwerte für Valenz und Disruption Score (D-Score). Er sagt nicht nur „es wurde lauter“, sondern er zeigt: Wenn der kombinierte Score aus Valenz und D-Score einen exakten Wert von z.B. -0.15 unterschreitet, bricht das System in 90% der Fälle im nächsten Turn zusammen.
-
Das Timing von Eskalationen: Da der Baum bis zu 8 Turns in die Vergangenheit schaut, offenbart er Latenzzeiten. Er zeigt, ob ein Streit sofort eskaliert (Split bei
t-1), oder ob eine schwelende toxische Bemerkung von vor 4 Runden (t-4) das System zeitverzögert vergiftet. -
Die Isolierung von Katalysatoren: Der Baum entlarvt objektiv Störer. Wenn die stärksten informationellen Lecks (Absturz zum Beispiel in den Identitätskampf) fast immer dann auftreten, wenn bestimmte Akteure – wie etwa Sprecher 4 – mit einer hohen Disruption ins Feld gehen, erlaubt dies die Identifikation von ’schwierigen Personen‘, unabhängig vom inhaltlichen Thema.
-
Die Erfolgsformel der Moderation: Der Baum zeigt exakt, welche Bedingungen erfüllt sein mussten, damit ein rettender Eingriff, z.B. die schöpferische Disruption, die Sachdebatte erfolgreich wiederhergestellt hat.
Wie wird daraus ein Coaching-Instrument?
Im agilen Management oder bei der Team-Mediation leidet Feedback oft unter Subjektivität („Ich fand, Du warst heute sehr dominant“). Der CMT-Decision-Tree objektiviert das Coaching völlig.
A. Das Frühwarnsystem (Predictive Coaching)
Ein Coach, der die Struktur dieses Baumes kennt, kann in einem Meeting Muster erkennen, bevor das System kollabiert. Wenn das Team gerade in einen Mikro-Zustand abgleitet, der im Baum zwingend zum „Regime 0“ (toxische Blockade: Identitätskampf) führt, kann der Coach die Reißleine ziehen und zum Beispiel ein disruptives Agenda-Setting eingeben.
B. Systemische Interventionen lehren
Führungskräften oder Moderatoren können anhand des Baumes lernen, wie sie „Kausale Kraft“ ( ) aufbauen. Man kann ihnen zeigen: „Schau hier auf den Datensatz. Wenn das System in Mikro-Zustand 7 feststeckt, nützt es nichts, inhaltlich zu argumentieren. Das System braucht jetzt einen V2-Agenda-Setting, um einen Reset auszulösen, der uns in Regime 1 (V1) bringt.“ Man coacht nicht mehr Inhalte, sondern System-Steuerung.
) aufbauen. Man kann ihnen zeigen: „Schau hier auf den Datensatz. Wenn das System in Mikro-Zustand 7 feststeckt, nützt es nichts, inhaltlich zu argumentieren. Das System braucht jetzt einen V2-Agenda-Setting, um einen Reset auszulösen, der uns in Regime 1 (V1) bringt.“ Man coacht nicht mehr Inhalte, sondern System-Steuerung.
C. Objektive Spiegelung (Das Debriefing)
Nach einem gescheiterten oder eskalierten Meeting kann das Transkript (oder die Videoanalyse) einer hier vorgestellten Hybriden Collective Intelligence unterzogen werden. Dem Team wird nicht gesagt „Ihr habt euch gestritten“, sondern man zeigt auf den Graphen: „Hier, bei Minute 45, ist unsere gemeinsame ‚Makro-Software‘ abgestürzt. Wir sind vom Erkenntnis-Modus (V1) in den reinen Identitäts-Verteidigungs-Modus (V0) gewechselt, weil die Valenz unter den Schwellenwert x fiel. Wie verhindern wir das beim nächsten Team-Meeting?“
Welche Informationen stecken in der Makro-Ebene und seinen drei Regimen V0, V1, V2
Anhang 2 listet die drei Regime 0, 1, 2 mit deren durch die upsilon-Maschine zugeordneten Meso-Zuständen und gibt genau an, unter welchen Bedingungen (Valenz und Disruption) diese das System steuern.
Wenn der Decision Tree (Mikro/Meso) uns schon die exakten Auslöser (z. B. „Valenz fällt unter -0.15“) liefert, wozu brauchen wir dann noch die Makro-Regime (V0, V1, V2)?
Die Antwort liegt im Kontext. Ein isolierter Mikro-Trigger bedeutet nie für sich allein dasselbe; seine Wirkung hängt komplett davon ab, in welchem Makro-Regime sich das System gerade befindet.
-
Der Decision Tree (Die Karte): Zeigt die mechanischen Schwellenwerte und die exakten Wenn-Dann-Pfade der Interaktion. Er ist extrem detailliert, aber blind für den Sinn des Ganzen.
-
Die Makro-Ebene (Der Kompass): Zeigt das übergeordnete „Betriebssystem“ oder die kulturelle Atmosphäre. Sie gibt den Mikro/Meso-Triggern ihre Bedeutung.
Ein praktisches Beispiel für diese Verbindung:
Man stelle sich vor, dass ein IT-Entwickler abrupt eine völlig neue IT-Architektur-Idee in den Raum wirft (hohe Disruption im Mikro-Zustand).
-
Befindet sich das Team gerade im Makro-Regime 1 (V1-Sachdebatte), wird diese Disruption vom System absorbiert und als konstruktiver Input verarbeitet.
-
Befindet sich das Team jedoch im Makro-Regime 0 (V0-Identitätskampf), wird exakt dieselbe Disruption vom System als feindlicher Angriff gewertet und führt zur totalen Eskalation.
Die Makro-Ebene sagt dem Coach also, welche strategische Phase gerade aktiv ist, während der Decision Tree dem Coach sagt, welche taktischen Schwellenwerte er bewachen muss, um diese Phase zu erhalten oder zu verlassen.
Die Ad-Hoc Nutzung (Das Live-Frühwarnsystem)
Wie kann man dies anwenden, wenn das Meeting gerade erst 10 Minuten läuft und noch keine 100 Turns vorliegen, um den Baum zu berechnen?
Das Geheimnis ist: Man berechnet den Baum nicht live im Meeting. Ein Live-Einsatz (Ad-Hoc) funktioniert immer in zwei getrennten Phasen:
Phase A: Das Basis-Modell (Die Offline-Vorbereitung)
Ein Team ist ein System – es hat eine konstante Struktur, die es unter Stress zeigt.
-
Aufzeichnungen oder Transkripte der letzten Meetings eines spezifischen Teams sind die Ausgangsbasis.
-
Diese historischen Daten werden mit den hier beschriebenen KI/ML Programmen analysiert.
-
Es wird ein Team spezifischer Decision Tree erzeugt und typischer Weise 3 Makro-Regime gebildet.
-
Dieses Modell wird ‚eingefroren‘. Es ist die Collective Mind DNA dieses Teams.
Phase B: Das Live-Dashboard (Der Ad-Hoc Einsatz im Meeting)
In den nachfolgenden Meetings wird der Führungskraft ein Dashboard zur Verfügung gestellt, das auf dem in den vorherigen 1-3 Meetings erzeugten Basis-Modell beruht. Im aktuellen Meeting läuft ein Sliding Window der letzten 8 Turns mit:
-
Die Live-Messung: Das Meeting läuft. Die KI-Tool ordnet jedem der Redebeiträge schnell einen D-Score und eine Valenz zu.
-
Der Daten-Feed: Sobald Turn 8 gesprochen wurde, schiebt sich das Sliding Window live in den eingefrorenen Decision Tree aus Phase A.
-
Der Sofort-Abgleich: Der Baum fragt seine Pfade ab: „Ah, Turn t-1 war negativ, t-4 war hoch disruptiv…“ und sortiert das Live-Fenster sofort in eines seiner zum Beispiel 19 Blätter (Mikro/Meso-Zustände) ein.
-
Die Prädiktion (Der Blick in die Zukunft): Das Modell gibt ad-hoc eine Warnung aus: „Basierend auf der historischen DNA dieses Teams bedeutet diese exakte Kombination der letzten 8 turns, dass wir im nächsten turn mit 85%iger Wahrscheinlichkeit in das Makro-Regime 0 (V0-Identitätskampf) abstürzen.“
In dem Moment, in dem das aktuelle Live-Gespräch in einen Mikro-Zustand wandert, der historisch gesehen zu einem toxischen Makro-Regime gehört, hat die Führungskraft (oder der Moderator oder der Coach) einen Zeitvorsprung.
Die Führungs-Intervention erfolgt nicht erst, wenn Leute sich anschreien (Makro-Ebene), sondern bevor die Wahrscheinlichkeit kippt (Mikro-Ebene): Es besteht die Möglichkeit das Gespräch rechtzeitig umzulenken: Der Team Stress-Score kann zum Beispiel durch eine beruhigende Zusammenfassung, eine Pause oder durch eine Disruption abgefangen werden und das Team wird damit auf einen anderen Pfad im Decision Tree umgeleitet.
Zu den berechneten Ergebnissen
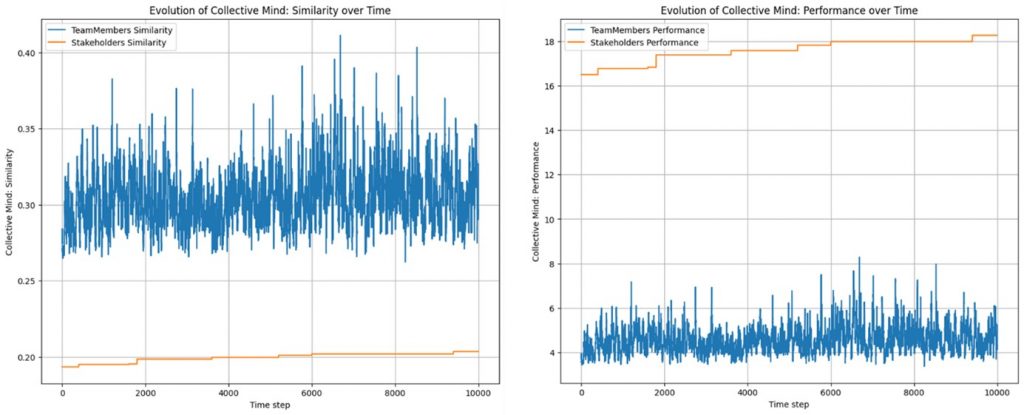
Die detaillierten berechneten Ergebnisse sind im Anhang 2 enthalten. Ich zeige hier lediglich die Abbildung zur kausalen Kraft, die als Maß der Emergenz verwendet wird. Diese Abbildung könnte Bestandteile eines Leadership Dashboards der Hybriden Collective Intelligence aus Mensch und Maschine sein:
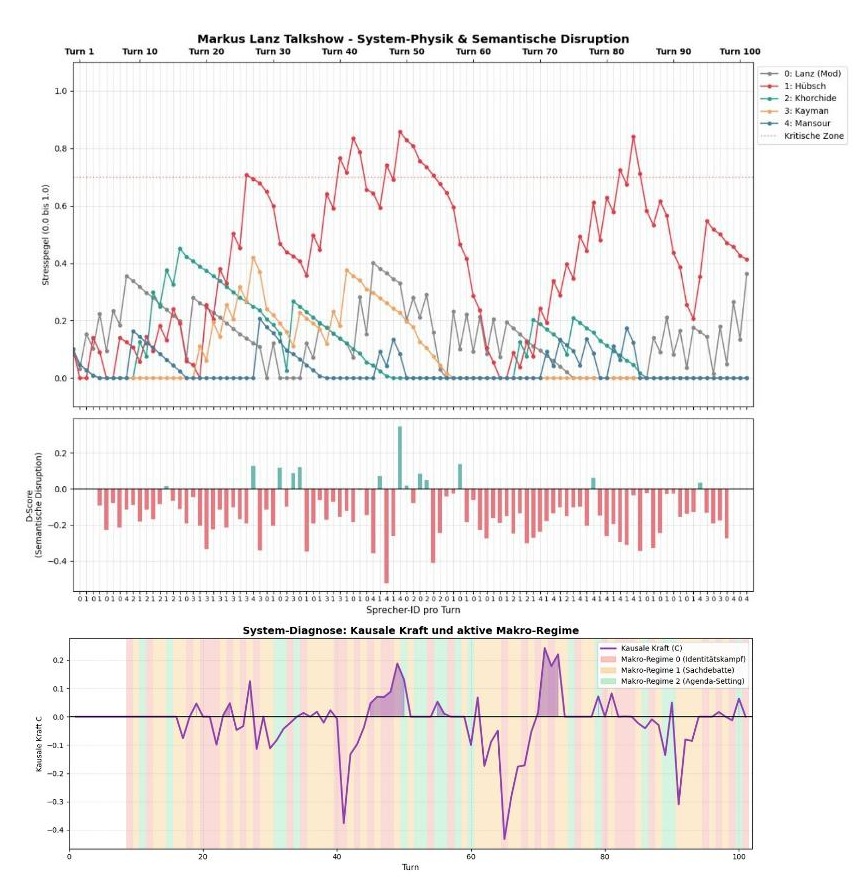
Abbildung 1: Abbildung 1 zeigt drei Teile. Die ersten beiden Teile stammen als Ergebnis aus dem Blog Attention Collective Mind III. Der dritte Teil, mit der violetten Kurve, zeigt die kausale Kraft. Ist die kausale Kraft positiv, liegt Emergenz vor: Dann steuert die Makro-Ebene des Systems ‚Markus Lanz vom 30. Mai 2024‘ das Verhalten der Teilnehmer.
Es werden zusätzlich die drei Makro-Regime V0, V1, V2 hervorgehoben. Wie man sieht, kann Emergenz auch ein dysfunktionales Regime wie V0 enthalten. Ich spreche hingegen nur dann von einem Collective Mind, wenn eines der Makro-Regime V1 oder V2 vorliegt. Die Makro-Regime V0, V1 und V2 können auch dann vorliegen, wenn die kausale Kraft nicht größer null ist, also keine Emergenz vorliegt. In diesem Fall ist die Makro-Ebene nicht kausal geschlossen: Das Verhalten der einzelnen Teilnehmer der TV-Runde bestimmt weiterhin in einem gewissen Maße die Kommunikation. Wenn die Kurve unter Null fällt, regiert die ‚Hardware‘ (die Akteure agieren unkoordiniert). Steigt sie über Null, übernimmt die ‚Software‘ (das kollektive System) die Führung.
Es lassen sich folgende Turn-Bereiche unterscheiden:
1. Das Rauschen und die Aufwärmphase (Turns 0 – 40)
Das Gespräch pendelt flach um die Nulllinie. Kurze Ausschläge ins Negative zeigen, dass die Akteure hier noch stark als isolierte Individuen argumentieren. Es gibt noch kein bindendes, übergeordnetes Feld. Die  -Maschine identifiziert keine signifikante kausale Übernahme durch ein Makro-Regime.
-Maschine identifiziert keine signifikante kausale Übernahme durch ein Makro-Regime.
2. Der erste Absturz ins Chaos (Turns 40 – 44)
Die kausale Kraft stürzt rapide auf  ab. Das System fragmentiert. Jede makroskopische Ordnung löst sich auf; die Vorhersagekraft liegt in dieser Phase extrem stark auf der Mikro-Ebene. Das bedeutet, das Verhalten der nächsten Runden wird rein durch die flüchtigen Reaktionen einzelner Personen diktiert, nicht durch eine Gruppendynamik.
ab. Das System fragmentiert. Jede makroskopische Ordnung löst sich auf; die Vorhersagekraft liegt in dieser Phase extrem stark auf der Mikro-Ebene. Das bedeutet, das Verhalten der nächsten Runden wird rein durch die flüchtigen Reaktionen einzelner Personen diktiert, nicht durch eine Gruppendynamik.
3. Die toxische Emergenz (Turns 45 – 55)
Direkt aus diesem Chaos heraus schnellt das System drastisch nach oben und erreicht bei Turn 50 einen ersten massiven Peak der Emergenz ( ). Exakt an diesem Punkt setzt Sprecher 4 den primären, disruptiven Impuls. Dieser Beitrag ist so stark krümmend, dass er die chaotische Mikro-Dynamik beendet und das System in einen geschlossenen Makro-Attraktor zwingt. Das System richtet sich vollständig an diesem Impuls von Sprecher 4 aus – der dysfunktionale Collective Mind erwacht, da es sich hierbei um das toxische Makro-Regime V0 des Identitätskampfes handelt.
). Exakt an diesem Punkt setzt Sprecher 4 den primären, disruptiven Impuls. Dieser Beitrag ist so stark krümmend, dass er die chaotische Mikro-Dynamik beendet und das System in einen geschlossenen Makro-Attraktor zwingt. Das System richtet sich vollständig an diesem Impuls von Sprecher 4 aus – der dysfunktionale Collective Mind erwacht, da es sich hierbei um das toxische Makro-Regime V0 des Identitätskampfes handelt.
4. Der absolute Kontrollverlust (Turns 60 – 68)
Nach einer kurzen Beruhigung kollabiert die Emergenz vollständig. Bei Turn 67 erreicht die Kausale Kraft den absoluten Tiefpunkt des gesamten Gesprächs ( ). Der zuvor durch Sprecher 4 etablierte Makro-Zustand wird zerschossen. Das System befindet sich im Zustand maximaler Entropie: Ein tiefes Tal, in dem die Akteure komplett aneinander vorbeireden und keine Resonanz existiert.
). Der zuvor durch Sprecher 4 etablierte Makro-Zustand wird zerschossen. Das System befindet sich im Zustand maximaler Entropie: Ein tiefes Tal, in dem die Akteure komplett aneinander vorbeireden und keine Resonanz existiert.
5. Die systemische Übernahme (Turns 70 – 75)
Das System erholt sich von dem Absturz durch eine beispiellose kausale Synchronisation. Die Kurve schießt auf den Maximalwert von  . In diesen fünf Runden ist die Vorhersagekraft des Makro-Regimes sehr hoch. Die isolierten Akteure sind kausal nahezu unbedeutend geworden; das Meeting wird in dieser Phase komplett durch die Makro-Ebene gesteuert.
. In diesen fünf Runden ist die Vorhersagekraft des Makro-Regimes sehr hoch. Die isolierten Akteure sind kausal nahezu unbedeutend geworden; das Meeting wird in dieser Phase komplett durch die Makro-Ebene gesteuert.
Interessant ist hier das Flackern des Hintergrunds zwischen Rosa (Identitätskampf) und Gelb (Sachdebatte). Das System ist in einer extrem hochfrequenten, verschränkten Aushandlung gefangen. Die Argumente (gelb) werden als unmittelbare Waffen im Identitätskampf (rosa) genutzt. Das Kollektiv ist hier absolut starr und deterministisch verschweißt – ein Entkommen ohne massiven Tabubruch von außen ist unmöglich.
6. Das Ausklingen (Turns 80 – 100)
Das Gespräch zerfällt wieder in eine unruhige Mikro-Dominanz mit einigen schwächeren Versuchen, ein neues Makro-Regime zu etablieren (kleinere Peaks bei 82 und 87). Bei Turn 93 durchläuft die Gruppe nochmals einen starken Abfall ins Chaos und läuft am Ende flach aus.
Die Abbildung weist folgende besondere Turns auf:
1. Das informationelle Vakuum der Sachdebatte (Turn 41 & Turn 66)
Schaut man sich die beiden extremsten Abstürze der Kausalen Kraft an ( ), fallen diese in oder an die Ränder der gelben Zonen (Makro-Regime V1: Sachdebatte).
), fallen diese in oder an die Ränder der gelben Zonen (Makro-Regime V1: Sachdebatte).
Dies widerlegt eine klassische Illusion vieler Moderatoren. Nur weil Menschen sachlich (gelb) argumentieren, bedeutet das nicht, dass sie sich verstehen. Bei Turn 66 herrscht das absolute informationelle Chaos. Die Akteure feuern ihre Fakten isoliert ab, ohne jegliche Resonanz beim Gegenüber zu erzeugen. Das System zersplittert in reine Mikro-Hardware. Es gibt keine gemeinsame Wellenlänge.
2. Das Scheitern der konstruktiven Führung (Die grünen Zonen)
Das Makro-Regime V2 (Agenda-Setting, grün) zeigt in diesem Plot eine dramatische Schwäche. Es taucht immer wieder als kurzer Versuch auf (z. B. Turns 31, 53, 58, 80, 89).
Die violette Kurve in diesen grünen Bändern liegt fast ausnahmslos unter oder exakt auf der Nulllinie. Das bedeutet: Jedes Mal, wenn jemand versucht, konstruktiv die Agenda zu setzen, verweigert das System die Gefolgschaft. Das Agenda-Setting wird nie zu einem emergenten Collective Mind. Die Vorhersagekraft bleibt bei den unkoordinierten Individuen. Der Raum akzeptiert diese Führung schlichtweg nicht.
Das Emergenz-Modell zeigt visuell: Die spezifische Kultur des TV-Meetings besitzt tiefe Attraktoren für Identitätskämpfe (rosa), die sofort das gesamte System kausal bestimmen. Versuche der Meta-Steuerung (grün) sind wirkungslos, da sie keine kausale Kraft ( ) aufbauen können.
) aufbauen können.
Zusammenfassung:
Das Modell der kausalen Emergenz, ursprünglich entwickelt für mathematisch-naturwissenschaftliche Fragestellungen, zeigt eine erstaunliche Vorhersagekraft für soziale Interaktionen. Zusammen mit den beiden Modellen zum Stresslevel und der Disruption, die beide ebenfalls aus einem mathematisch-naturwissenschaftlichen Kontext stammen, ergibt sich eine enorme Analyse- und Steuerungskraft für die Führung von Gruppen oder Teams. Der von mir gewählte Ansatz der hybriden Collective Intelligence hat sich damit bewiesen.
Anhang 1
Formeln und Erläuterungen
Dieser Anhang beschreibt die drei verwendeten Modelle und Algorithmen für die Ermittlung der kausalen Emergenz:
- Die epsilon-Maschine, die die kausalen Zustände innerhalb einer Hierarchie-Ebene erzeugt, implementiert durch einen Decision Tree Regessor Algorithmus
- Die upsilon-Maschine, die die kausalen Zustände von einer Ebene zur nächsten Ebene erzeugt, implementiert durch einen K-Means Algorithmus
- Die Berechnung der Mutual Information, des Information Leackage und des Kausalen Delta (der Kausalen Kraft). Diese drei Größen vermessen die Stärke der Emergenz.
Um die Algorithmen zu beschreiben werden folgende Notationen aus der Wahrscheinlichkeits- Informationstheorie verwendet:
-
Ein Komma
steht für die gemeinsame Wahrscheinlichkeit (beides passiert gleichzeitig). -
Ein senkrechter Strich
steht für die bedingte Wahrscheinlichkeit (X passiert, unter der Bedingung, dass Y schon passiert ist). -
Das Semikolon
drückt eine Schnittmenge an Information aus. Man liest es als: „Die Menge an Information, die zwischen der Variablen X und der Variablen Y geteilt wird.“ Mathematisch berechnet sich das so:In Worten: Das
steht für die Transinformation (auf Englisch Mutual Information). Das Semikolon ist hier extrem wichtig, um es von anderen Wahrscheinlichkeitsnotationen abzugrenzen. Die Transinformation ist die Entropie (Unsicherheit) von X, minus der verbleibenden Unsicherheit von X, wenn ich Y kenne. Das Semikolon zeigt also an, dass wir zwei Informationsquellen gegenüberstellen und fragen: Wie viel weiß ich durch die eine Quelle über die andere?



![\[I(X; Y) = H(X) - H(X|Y)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-6ea2f0728f662a90803268b6b78984c5_l3.png "Rendered by QuickLaTeX.com")

Wenn wir nun das Informationsleck (Leakage) als  betrachten, lesen wir das mit dem Wissen über das Semikolon so:
betrachten, lesen wir das mit dem Wissen über das Semikolon so:
„Wie viel Information teilen die Mikro-Vergangenheit  und die Makro-Zukunft
und die Makro-Zukunft  noch miteinander, wenn wir den Einfluss der Makro-Vergangenheit
noch miteinander, wenn wir den Einfluss der Makro-Vergangenheit  herausrechnen (bedingende Variable hinter dem Strich)?“
herausrechnen (bedingende Variable hinter dem Strich)?“
I. Die epsilon-Maschine, der Decision Tree Regressor Algorithmus
Der Sprung von einer linearen Liste mit 100 Textzeilen (Turns) zu einem multidimensionalen Baumalgorithmus ist die größte Hürde in der Zeitreihenanalyse. Um die Datenverarbeitung komplett transparent zu machen, zeichne ich den Weg der Daten vom rohen Transkript bis zur fertigen -Maschine nach.
Schritt 1: Die Datenpräparation (Das Sliding Window)
Ich starte mit einer eindimensionalen Kette von 100 Turns. Jeder Turn hat einen berechneten Mikro-Wert (z. B. den Durchschnitt aus Disruption und Valenz). Nennen wir diesen Wert für den Moment einfach  . Das führt also zur Sequenz:
. Das führt also zur Sequenz:  .
.
Ein rekursiver Partitionierungs-Algorithmus kann mit einer solchen Kette nichts anfangen. Er braucht klare „Wenn-Dann“-Tabellen. Deshalb zerschneiden wir die 100 Turns mit einem gleitenden Fenster (Window-Größe = 8) in eine Matrix.
Wir sagen dem System: „Nutze die letzten 8 Turns (die Vergangenheit), um den 9. Turn (die Zukunft) vorherzusagen.“ Das Fenster rutscht dann immer einen Turn weiter.
Die neue Daten-Matrix sieht so aus:
| Datenpunkt (Zeile) | t−8 | t−7 | t−6 | t−5 | t−4 | t−3 | t−2 | t−1 | Ziel (Zukunft t) |
| Zeile 1 | Turn 1 | Turn 2 | Turn 3 | Turn 4 | Turn 5 | Turn 6 | Turn 7 | Turn 8 | Turn 9 |
| Zeile 2 | Turn 2 | Turn 3 | Turn 4 | Turn 5 | Turn 6 | Turn 7 | Turn 8 | Turn 9 | Turn 10 |
| Zeile 3 | Turn 3 | Turn 4 | Turn 5 | Turn 6 | Turn 7 | Turn 8 | Turn 9 | Turn 10 | Turn 11 |
| … | … | … | … | … | … | … | … | … | … |
| Zeile 92 | Turn 92 | Turn 93 | Turn 94 | Turn 95 | Turn 96 | Turn 97 | Turn 98 | Turn 99 | Turn 100 |
Da die ersten 8 Turns für die allererste Vorhersage „verbraucht“ werden, hat man am Ende exakt 92 Zeilen (Datenpunkte), die in den Algorithmus eingespeist werden.
Schritt 2: Der erste Split (Die Wurzel des Baumes)
Jetzt startet der eigentliche Algorithmus. Der Baum betrachtet alle 92 Zeilen gleichzeitig und stellt sich eine einzige Frage: Welche Spalte aus der Vergangenheit und welcher exakte Schwellenwert trennt die Zukünfte am besten voneinander?
Der Algorithmus testet intern Tausende von Kombinationen durch. Er nimmt sich z. B. die Spalte  (den unmittelbar vorherigen Turn) und testet den angenommen Schwellenwert
(den unmittelbar vorherigen Turn) und testet den angenommen Schwellenwert  . Er teilt die 92 Zeilen probeweise in zwei Gruppen:
. Er teilt die 92 Zeilen probeweise in zwei Gruppen:
-
Gruppe Links: Alle Zeilen, bei denen
war. -
Gruppe Rechts: Alle Zeilen, bei denen
war.


Dann berechnet er für beide Gruppen, wie sehr die tatsächlichen Ziel-Werte (die Zukunft  ) innerhalb der Gruppe streuen. Das macht er mit dem mittleren quadratischen Fehler (
) innerhalb der Gruppe streuen. Das macht er mit dem mittleren quadratischen Fehler ( ):
):

-
ist die Anzahl der Zeilen in der jeweiligen Gruppe.
-
ist die tatsächliche Zukunft in Zeile .
-
ist der Durchschnitt aller Zukünfte in dieser Gruppe.


Wenn der Gesamt- dieser Aufteilung extrem niedrig ist, bedeutet das: Die Trennung war erfolgreich. Der Algorithmus sucht den allerbesten Split und verankert ihn als obersten Knotenpunkt (die Wurzel) des Baumes.
Schritt 3: Die Rekursion (Das Wachsen der Äste)
Nun hat der Baum die 92 Zeilen in zwei Gruppen geteilt (z. B. 40 Zeilen links, 52 Zeilen rechts).
Jetzt wendet er exakt denselben Prozess aus Schritt 2 auf die linke Gruppe an. Er ignoriert die rechte komplett. Er schaut sich die verbliebenen 40 Zeilen an und fragt sich wieder: Welche Spalte und welcher Schwellenwert teilt diese 40 Zeilen am besten auf? Vielleicht ist es diesmal  .
.
Der Baum spaltet die Daten weiter und weiter auf. Er sucht immer nach der Eigenschaft in der Vergangenheit, die die verbleibenden Zukünfte am präzisesten in homogene Gruppen sortiert.
Schritt 4: Der Stopp (Das Entstehen der Epsilon-Zustände)
Ein Baum würde die Daten im Normalfall so lange spalten, bis in jedem Endknoten nur noch eine einzige Zeile liegt. Das wäre nutzlos (ein reines Auswendiglernen der Daten). Deshalb existiert eine Bremse: Eine Mindestanzahl von Beobachtungen pro Blatt.
Der Baum hört sofort auf, einen Ast weiter zu spalten, wenn in der resultierenden Gruppe weniger als 4 Zeilen (Turns) landen würden. An diesem Punkt entsteht ein Endknoten (ein Blatt). In unserem Fall hat der Algorithmus den Prozess gestoppt und exakt 19 Blätter gebildet (siehe Anhang 2).
-
Jedes dieser 19 Blätter ist ein „Eimer“, in dem eine bestimmte Anzahl der 92 historischen Datenpunkte gelandet ist (z. B. 5 Turns im ersten Blatt, 12 im zweiten).
-
Alle Turns, die in demselben Blatt gelandet sind, teilen sich dieselbe kausale Eigenschaft: Sie führen statistisch gesehen zu exakt derselben Vorhersage für die Zukunft (
).
Diese 19 Blätter sind exakt das, was ich (angelehnt an Rosas et al.) als kausale Mikro-Zustände der -Maschine definiere.
II. Die upsilon-Maschine: Der K-Means Algorithmus
Um die 19 hochdetaillierten -Zustände zu einer übergeordneten Makro-Software zusammenzufassen, muss das System die Zustände abstrahieren. Dies geschieht durch einen unüberwachten Clustering-Algorithmus, der ähnliche Zukünfte zu übergeordneten Regimen verschmilzt.
Schritt 1: Der Input (Die 1D-Vorhersagematrix)
Der Algorithmus extrahiert aus den 19 Blättern des Baumes die exakten Vorhersagewerte  für jeden der 92 historischen Datenpunkte. Es entsteht eine eindimensionale Matrix (ein Vektor) aus 92 Kommazahlen. Ziel ist es, diese in genau
für jeden der 92 historischen Datenpunkte. Es entsteht eine eindimensionale Matrix (ein Vektor) aus 92 Kommazahlen. Ziel ist es, diese in genau  fundamentale Makro-Regime zu gruppieren.
fundamentale Makro-Regime zu gruppieren.
Schritt 2: Die K-Means Initialisierung (Der Maximalkontrast)
Das System wirft nicht einfach drei zufällige Schwerpunkte (Zentroide  ) in diese Daten. Um das zuverlässigste Ergebnis zu garantieren, wird iterativ vorgegangen:
) in diese Daten. Um das zuverlässigste Ergebnis zu garantieren, wird iterativ vorgegangen:
-
Der erste Zentroid
wird zufällig aus den 92 Werten gewählt. -
Der zweite Zentroid
wird exakt auf den Datenpunkt gesetzt, der die größte mathematische Distanz zu aufweist. -
Der dritte Zentroid
wird auf den Punkt gesetzt, der maximal weit von und entfernt ist. -
Dieses Vorgehen stellt sicher, dass die drei startenden Makro-Regime den größtmöglichen inhaltlichen Kontrast zueinander aufweisen.



Schritt 3: Das Zuweisungs-Update (Lloyds Algorithmus)
Der Algorithmus startet nun seinen eigentlichen Suchlauf. Für jeden der 92 Vorhersagewerte  misst er die quadrierte Differenz (Distanz) zu den drei Zentroiden:
misst er die quadrierte Differenz (Distanz) zu den drei Zentroiden:

Der Wert bekommt das Label des Zentroiden  , bei dem die Distanz
, bei dem die Distanz  am kleinsten ist. Mikro-Zustände, die ähnliche Zukunftswerte prognostizieren, werden so vom selben Zentroiden eingefangen.
am kleinsten ist. Mikro-Zustände, die ähnliche Zukunftswerte prognostizieren, werden so vom selben Zentroiden eingefangen.
Schritt 4: Das Zentroid-Update
Nachdem alle 92 Werte verteilt sind, berechnet das System die neuen, echten Schwerpunkte. Für jedes Cluster  summiert es alle zugewiesenen Werte auf und teilt sie durch die Anzahl
summiert es alle zugewiesenen Werte auf und teilt sie durch die Anzahl  der Werte im Cluster:
der Werte im Cluster:

Die Zentroide wandern exakt auf diese neuen Mittelwerte.
Schritt 5: Die Konvergenz (Das Einrasten des Systems)
Schritt 3 und 4 wiederholen sich in einer Schleife, bis das System einrastet – das bedeutet, kein einziger Datenpunkt verschiebt sich beim nächsten Durchlauf in ein anderes Cluster. Das Coarse-Graining ist abgeschlossen. Die 19 Mikro-Zustände sind nun zu einer Sequenz von 3 diskreten Makro-Regimen komprimiert. Die -Maschine ist konstruiert.
III. Die Messung der Emergenz C: Der KSG-Entropieschätzer
Um zu beweisen, dass die neu konstruierte Makro-Software mächtiger ist als die Mikro-Hardware, muss die Transinformation (Mutual Information) zwischen Vergangenheit () und Zukunft ( ) berechnet werden. Da wir es auf der Mikro/Meso-Ebene mit stufenlosen Kommazahlen zu tun haben, wird der hochpräzise Schätzer nach Kraskov, Stögbauer und Grassberger (KSG) angewandt.
) berechnet werden. Da wir es auf der Mikro/Meso-Ebene mit stufenlosen Kommazahlen zu tun haben, wird der hochpräzise Schätzer nach Kraskov, Stögbauer und Grassberger (KSG) angewandt.
Schritt 1: Raumaufspannung und das Verhindern von Singularitäten
Der Algorithmus spannt einen 2D-Raum auf, wobei die -Achse die Vergangenheit und die -Achse die Zukunft repräsentiert: Auf den Achsen wird jeweils der Mittelwert von Valenz und Disruption zum jeweiligen Zeitpunkt aufgetragen. Da menschliche Kommunikationsdaten oft redundante Werte erzeugen (z.B. exakt denselben Disruption-Score über zwei Runden), würden exakt übereinanderliegende Punkte im Algorithmus zu einer Division durch Null führen. Um diese Singularität zu verhindern, wird jedem Datenpunkt ein minimales thermodynamisches Rauschen (Jitter im Bereich von  ) hinzugefügt. Dies verschiebt die Punkte im infinitesimalen Bereich und macht Abstände messbar, ohne die topologische Information zu verfälschen.
) hinzugefügt. Dies verschiebt die Punkte im infinitesimalen Bereich und macht Abstände messbar, ohne die topologische Information zu verfälschen.
Schritt 2: Distanzmessung im gekoppelten Raum (-Nearest Neighbors)
Zur effizienten Suche wird im Hintergrund eine räumliche Datenstruktur (ein  -D-Tree) aufgebaut. Für jeden Punkt
-D-Tree) aufgebaut. Für jeden Punkt  im gemeinsamen
im gemeinsamen  -Raum sucht der Algorithmus den
-Raum sucht der Algorithmus den  -nächsten Nachbarn (standardmäßig
-nächsten Nachbarn (standardmäßig  ). Er misst die exakte Distanz zu diesem dritten Nachbarn unter Verwendung der Maximums-Metrik (Chebyshev-Distanz). Diese Distanzspanne nennen wir
). Er misst die exakte Distanz zu diesem dritten Nachbarn unter Verwendung der Maximums-Metrik (Chebyshev-Distanz). Diese Distanzspanne nennen wir  . Sie definiert ein lokales Suchfenster um jeden Punkt.
. Sie definiert ein lokales Suchfenster um jeden Punkt.
Schritt 3: Marginale Zählung (Die Zerlegung der Wahrscheinlichkeit)
Der Algorithmus nutzt dieses Suchfenster nun, um die Wahrscheinlichkeitsdichten auf den Einzelachsen zu schätzen:
-
Er blickt ausschließlich auf die
-Achse (die Vergangenheit) und zählt, wie viele Punkte innerhalb der Distanz liegen. -
Er blickt ausschließlich auf die
-Achse (die Zukunft) und zählt, wie viele Punkte innerhalb dieser Distanz liegen.


Schritt 4: Die Digamma-Integration
Anstatt Daten in ungenaue Histogramme zu pressen, setzt der Algorithmus diese präzisen Abstands-Zählungen in die KSG-Schätzgleichung ein. Diese Gleichung nutzt die Digamma-Funktion  (die logarithmische Ableitung der Gamma-Funktion), um die exakte Transinformation
(die logarithmische Ableitung der Gamma-Funktion), um die exakte Transinformation  in natürlichen Informationseinheiten (Nats) zu berechnen:
in natürlichen Informationseinheiten (Nats) zu berechnen:

Dabei ist  die Gesamtzahl der Runden im Beobachtungsfenster.
die Gesamtzahl der Runden im Beobachtungsfenster.
Schritt 5: Das Kausale Delta (Der finale Beweis)
Dieser gesamte KSG-Prozess wird dual ausgeführt: Einmal für die Informationstransfer-Rate der rohen Mikro-Ebene  und einmal für die Informationstransfer-Rate der konstruierten Makro-Ebene
und einmal für die Informationstransfer-Rate der konstruierten Makro-Ebene  .
.
Die Subtraktion beider Ergebnisse liefert die Kausale Kraft:

Wenn dieser Wert positiv ist, ist der mathematische Beweis für das Vorliegen der Emergenz, hier des (dysfunktionalen) Collective Mind, erbracht:
Wenn  positiv wird, geschieht etwas Fundamental-Systemisches: Die Mikro-Details (z. B. welches genaue Wort ein Akteur wählt oder wie seine individuelle Tagesform ist) werden kausal irrelevant.
positiv wird, geschieht etwas Fundamental-Systemisches: Die Mikro-Details (z. B. welches genaue Wort ein Akteur wählt oder wie seine individuelle Tagesform ist) werden kausal irrelevant.
Das Makro-Regime zwingt dem System sein eigenes physikalisches Gesetz auf. Wenn ein Meeting kausal emergent in den Identitätskampf (Regime V0, siehe Anhang 2) stürzt, greifen sich die Akteure nicht mehr an, weil sie sich als Individuen in diesem Moment dazu entscheiden. Sie greifen sich an, weil das emergente Feld (der dysfunktionale Collective Mind) sie kausal dazu zwingt. Das System reproduziert sich selbst.
Anhang 2
Mikro-, Meso- und Makro-Ebene für das TV-Beispiel
Mikro-Ebene:
Die Mikro-Ebene besteht aus den 100 Turns (= 100 Aussagen der TV- Teilnehmer). Diese 100 Turns stammen aus dem Mitschnitt der Markus Lanz TV-Sendung und anschließender Transkription. Die Turns wurden erstmals im Blog ‚AI & M 4.0: Markus Lanz vom 30.04.2024, Eine Collective Mind Analyse, vom Juni 2024‘ verwendet.
Meso-Ebene:
Die Meso-Ebene besteht aus den 19 End-Blättern der Decision Tree Regression. Die folgende Abbildung zeigt den Entscheidungsbaum.
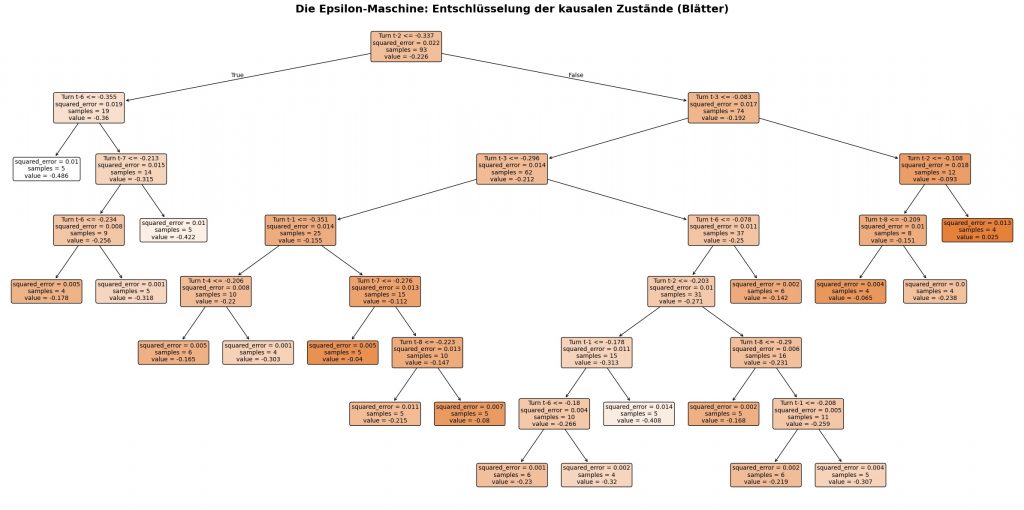
Die Anwendung in der Collective Mind Theorie:
-
Was passiert hier? Wir füttern den Baum mit den rohen Mikro-Eingaben (Disruption und Valenz der einzelnen Sprecher der letzten 8 Turns). Der Algorithmus spaltet diese Historie so lange auf, bis er in den Endknoten (Blättern) Gruppen von Vergangenheiten findet, bei denen der
minimal ist – sie also alle exakt denselben Erwartungswert für die Zukunft haben. -
Die theoretische Übersetzung: Genau das ist die Definition der Epsilon-Maschine. Der Baum filtert alle redundanten Informationen heraus (z. B. „Wer genau hat gesprochen?“). Wenn eine leise, giftige Bemerkung von Sprecher A und ein lauter Wutanfall von Sprecher B am Ende exakt dieselbe Systemreaktion für den nächsten Turn auslösen, wirft der Decision Tree beide in dasselbe Blatt. Dieses Blatt ist der kausale Mikro/Meso-Zustand (
). Wir haben damit die „Hardware“ der Konversation extrahiert.
 ). Wir haben damit die „Hardware“ der Konversation extrahiert.
). Wir haben damit die „Hardware“ der Konversation extrahiert.Makro-Ebene:
Die Makro-Ebene besteht aus den zu drei Clustern zusammengefassten 19 kausalen Zuständen der Meso-Ebene. Die Zusammenfassung wird durch den K-Means Algorithmus erzeugt. Die drei Regime stellen einen Vektor-Ordnungsparameter dar
Die Anwendung in der Collective Mind Theorie:
-
Was passiert hier? Wir nehmen die Vorhersagen
aus den 19 Blättern des Decision Trees und zwingen K-Means, diese in exakt Cluster/Regime zu pressen. -
Die theoretische Übersetzung: Das ist das „Coarse-Graining“ (die Vergröberung) zur Upsilon-Maschine. Die 19 Mikro/Meso-Zustände sind zu detailliert, um ein „Collective Mind“ zu sein. Indem K-Means ähnliche Vorhersagen mathematisch verschmilzt, entstehen die Makro-Regime. In diesem Fall hat der Algorithmus die drei fundamentalen Aggregatzustände (Makro-Regime) des Teams gefunden:
-
V0-Identitätskampf (Hohe negative Valenz, toxischer Stress)
-
V1-Sachdebatte (Moderate Valenz, Kohärenz)
-
V2-Agenda Setting (Schöpferische Disruption)
-
Das Resultat: Die Upsilon-Maschine repräsentiert nun die „Software“ oder die kulturelle Atmosphäre.
Auf dieser Basis wird die Transinformation berechnet und die zwei zentralen Kriterien für Emergenz
A. Die Kausale Kraft ():
Wir vergleichen die Vorhersagekraft der Upsilon-Maschine (Makro) mit der der reinen Rohdaten (Mikro):
![\[\mathcal{C} = I(Z_t ; Z_{t+1}) - I(X_t ; X_{t+1})\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-94a827622fe8f8a65ea2dbe29af802d6_l3.png "Rendered by QuickLaTeX.com")
-
Bedeutung: Wenn
ist, enthält das Wissen über das aktuelle Makro-Regime (, z. B. „Wir sind gerade in der Sachdebatte“) mehr Informationen über die Zukunft als das Wissen über das exakte Verhalten der Sprecher (). Das Team hat den Collective Mind Makro-Zustand erreicht.
B. Das Information Leakage ( ):
):
Das Information Leakage ist eine redundante Größe, wenn die kausale Kraft bekannt ist, da
![\[\mathcal{C} = -L\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-16b40c96fdd8506b574b79e687681d70_l3.png "Rendered by QuickLaTeX.com")
![\[L = I(Z_{t+1}; X_t | Z_t)\]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-c0fa7e6b6e25c68ae9e94a8f6360a0d5_l3.png "Rendered by QuickLaTeX.com")
-
Bedeutung: Das ist der Indikator für den Systemkollaps. Das Leakage misst, wie viel das Mikro-Verhalten (
) noch über die Zukunft verrät, obwohl wir den Collective Mind () schon kennen. Wenn ausschlägt, hat eine einzelne Person (durch extreme Disruption) das normative Gefüge des Teams gesprengt. Die Software (Makro) hat die Kontrolle über die Hardware (Mikro) verloren.
Im folgenden liste ich jeweils die drei Makro-Regime, in dem ich diese kurz skizziere und die dazugehörigen Meso kausalen Zustände anfügen:
MAKRO-Regime 0 –Der Identitäts-Kampf
-
Die Datenlage: Fast durchgehend tiefrote, extrem negative Valenzen (-0.50 bis -0.90).
-
Die Akteure: Hier dominieren Mansour (Sprecher 4, der die stärksten Systemdisruptionen treibt) und Kayman.
-
Der Inhalt: Es geht um harte inhaltliche und moralische Fronten („moralische Überlegenheit“, „politischer Islam“, „Extremisten“).
-
Die System-Diagnose: Dieses Regime markiert den Zusammenbruch des kausalen Flusses. Die Kommunikation ist informationell geschlossen, da die Sprecher auf ihre V0-Identitätswerte zurückfallen. Die Akteure verteidigen ihre Ingroup („Ich bin Muslim, ich rede über meine Community“). Es entsteht eine massive kollektive Interferenz, bei der sachliche Argumente (V1) nicht mehr durchdringen.
🔬 Meso-Ebene 2
Turn 24 | Kayman | D-Score: -0.10 | Val: -0.60 | "Wir müssen mit jungen Menschen darüber reden, dass dieses De..."
Turn 26 | Kayman | D-Score: -0.19 | Val: -0.90 | "Auch in der Ahmadiyya-Gemeinde gibt es eine Tradition des An..."
Turn 28 | Kayman | D-Score: -0.34 | Val: -0.90 | "Ich wollte das nicht aufbrechen, weil das das Feld zu weit ö..."
Turn 47 | Mansour | D-Score: -0.52 | Val: -0.50 | "Entschuldigung...."
Turn 101 | Mansour | D-Score: +0.00 | Val: -0.80 | "Zweitens. Dieser politische Islam, der versucht gerade, die ..."
🔬 Meso-Ebene 6
Turn 35 | Hübsch | D-Score: -0.35 | Val: -0.30 | "Unsere Gemeinschaft ist über 100 Jahre alt...."
Turn 40 | Kayman | D-Score: -0.15 | Val: -0.60 | "Sie ziehen sich immer auf die Position zurück, ab der es dan..."
Turn 43 | Hübsch | D-Score: -0.00 | Val: -0.60 | "Weil das vor dem internationalen Gerichtshof verhandelt wird..."
Turn 72 | Mansour | D-Score: -0.13 | Val: -0.50 | "Ich habe eine Grundsatzfrage gestellt...."
Turn 84 | Mansour | D-Score: -0.03 | Val: -0.50 | "Aber er darf kein Mitglied sein in Ihrer Gemeinde?..."
🔬 Meso-Ebene 7
Turn 20 | Kayman | D-Score: -0.33 | Val: -0.90 | "Ich bin Muslim, ich rede über meine Community. Ich glaube, e..."
Turn 22 | Kayman | D-Score: -0.12 | Val: -0.60 | "Entschuldigung, wir können nicht über Vorereignisse aus dem ..."
Turn 82 | Mansour | D-Score: -0.29 | Val: -0.50 | "Ein homosexuelles Paar...."
Turn 97 | Kayman | D-Score: -0.17 | Val: -0.60 | "Das ist die Vorstellung einer moralischen Überlegenheit durc..."
Turn 99 | Mansour | D-Score: +0.00 | Val: -0.70 | "Um das psychologisch zu betreiben, auf zwei Ebenen. Das indi..."
🔬Meso-Ebene 13
Turn 21 | Hübsch | D-Score: -0.23 | Val: -0.30 | "Was ist mit dem Vertrag von Medina?..."
Turn 41 | Hübsch | D-Score: -0.12 | Val: -0.60 | "Deswegen hatte ich auch diesen Einwand, weil ich so aufgewac..."
Turn 48 | Hübsch | D-Score: -0.26 | Val: -0.30 | "Ganz schlechter Wort über Autismus...."
Turn 83 | Hübsch | D-Score: -0.31 | Val: -0.30 | "Man muss sich entscheiden. Da ist es nicht anders als in der..."
🔬 Meso-Ebene 24
Turn 9 | Khorchide | D-Score: -0.09 | Val: -0.50 | "Wir müssen uns die Schriften anschauen. Es war in der islami..."
Turn 68 | Khorchide | D-Score: -0.30 | Val: -0.20 | "Das sind standardisierte Fragen, die man auch an Christen st..."
Turn 70 | Mansour | D-Score: -0.24 | Val: -0.50 | "Aber Sie reden nicht über die Christen, Frau Hübsch. Darf ic..."
Turn 95 | Kayman | D-Score: -0.13 | Val: -0.60 | "Ich glaube, das, was wir erlebt haben, ist exemplarisch für ..."
🔬 Meso-Ebene 25
Turn 12 | Hübsch | D-Score: -0.17 | Val: -0.60 | "Das ist umgekehrt. Die Interpretation der Extremisten, der H..."
Turn 18 | Kayman | D-Score: -0.04 | Val: -0.90 | "Wir haben aktuell kein Problem, dass Theologie eine Natur is..."
Turn 45 | Mansour | D-Score: -0.36 | Val: -0.80 | "Ich habe es Ihnen versprochen, Herr Mansur. Erst mal frage i..."
Turn 65 | Hübsch | D-Score: -0.15 | Val: -0.30 | "Ich glaube nicht. Das ist so weit verbreitet in der islamisc..."
Turn 80 | Mansour | D-Score: -0.26 | Val: -0.50 | "Ich kenne andere Rätsel von Mitgliedern bei Ihnen...."
🔬 Meso-Ebene 30
Turn 33 | Kayman | D-Score: +0.09 | Val: -0.90 | "Es geht es nur darum, man muss kein theologischer Islam-Expe..."
Turn 54 | Lanz (Mod) | D-Score: -0.41 | Val: +0.00 | "Zu sagen, ich bin auch da, ich bin auch wer...."
Turn 57 | Hübsch | D-Score: -0.03 | Val: -0.60 | "Keine Identifikation. Kennen Sie das? Ich kenne das total. I..."
Turn 76 | Mansour | D-Score: -0.10 | Val: -0.50 | "Aber Sie widersprechen sich...."
Turn 87 | Hübsch | D-Score: -0.33 | Val: -0.30 | "Auch Homosexualität. Sie dürfen Mitglied werden? Ja. Trotzde..."
MAKRO-Regime 1 Sachdebatte
-
Die Datenlage: Ein breiter Mix aus leicht negativer (-0.20 bis -0.30) bis neutraler Valenz. D-Scores sind meist im leichten Minus-Bereich.
-
Die Akteure: Hübsch ist hier überproportional präsent, oft im direkten Schlagabtausch mit Lanz, der versucht zu ordnen („Ich ordne kurz die Reihenfolge…“).
-
Der Inhalt: Das ist das „Tagesgeschäft“ der Talkshow. Es wird sich gerechtfertigt, relativiert und prozedural debattiert („Wir haben Mitglieder, die kein Kopftuch tragen“, „Wir leben in Deutschland“).
-
Die System-Diagnose: Das System operiert im Überlebensmodus. Es kollabiert nicht komplett in toxische Interferenz, erreicht aber auch keine echte Emergenz. Die Akteure reiben sich in der Verteidigung ihrer Positionen auf. Es ist ein ständiges Ausbalancieren zwischen V2-Tabubrüchen und V1-Rückzugsgefechten.
🔬 Meso-Ebene 5
Turn 14 | Hübsch | D-Score: +0.02 | Val: -0.30 | "Und was im Koran steht...."
Turn 30 | Hübsch | D-Score: -0.20 | Val: -0.30 | "Ich melde mich mal...."
Turn 42 | Lanz (Mod) | D-Score: -0.19 | Val: -0.30 | "Völkermord vielleicht sogar...."
Turn 49 | Mansour | D-Score: +0.35 | Val: -0.50 | "Nein, nein. Sie unterbrechen mich die ganze Zeit und lassen ..."
🔬 Meso-Ebene 12
Turn 23 | Hübsch | D-Score: -0.22 | Val: -0.30 | "Sie haben gesagt, es gibt keine positive Erzählung. Es gibt ..."
Turn 25 | Hübsch | D-Score: -0.17 | Val: -0.30 | "Vielleicht passiert es bei Ihnen nicht, bei uns passiert das..."
Turn 27 | Mansour | D-Score: +0.13 | Val: -0.50 | "Das müssen wir nicht verharmlosen...."
Turn 29 | Lanz (Mod) | D-Score: -0.11 | Val: +0.00 | "Ich ordne kurz die Reihenfolge...."
Turn 46 | Hübsch | D-Score: +0.07 | Val: -0.30 | "Das ist ein ganz schlechter Wort über Autismus...."
Turn 98 | Lanz (Mod) | D-Score: -0.27 | Val: +0.00 | "Der Mechanismus auf beiden Seiten...."
🔬 Meso-Ebene 17
Turn 36 | Lanz (Mod) | D-Score: -0.19 | Val: -0.30 | "Gibt es da Antisemitismus?..."
Turn 38 | Kayman | D-Score: -0.17 | Val: -0.60 | "Wie kamen Sie darauf? Ich habe doch nicht gesagt, dass alle ..."
Turn 44 | Lanz (Mod) | D-Score: -0.14 | Val: +0.00 | "Da ist wieder dieses relativierende Momentum. Sie müssen dar..."
Turn 73 | Hübsch | D-Score: -0.10 | Val: -0.30 | "Wir leben in Deutschland. In Deutschland gelten die deutsche..."
Turn 85 | Hübsch | D-Score: -0.34 | Val: +0.00 | "Natürlich darf jeder Mitglied sein. Wir haben auch Mitgliede..."
🔬 Meso-Ebene 23
Turn 10 | Hübsch | D-Score: -0.18 | Val: -0.30 | "Aber Sie sind Theologe. Ich erinnere mich noch an einen Arti..."
Turn 67 | Hübsch | D-Score: -0.14 | Val: -0.30 | "Wenn Sie die Leute in Positionierungsdruck versetzen und sag..."
Turn 69 | Hübsch | D-Score: -0.27 | Val: -0.30 | "Aber ein Christ würde im Zweifel sagen, mein Glaube ist mir ..."
Turn 71 | Hübsch | D-Score: -0.18 | Val: -0.30 | "Sie wissen, es gibt nicht nur eine Auslegung der Scharia. Di..."
Turn 74 | Khorchide | D-Score: -0.15 | Val: -0.20 | "Sind Sie für das oder für dieses Verständnis?..."
Turn 78 | Mansour | D-Score: +0.06 | Val: -0.50 | "Darf ein Homosexueller bei Ihnen Mitglied werden?..."
🔬 Meso-Ebene 27
Turn 16 | Hübsch | D-Score: -0.11 | Val: -0.30 | "Sie wissen als Theologe ganz genau, dass es in der gesamten ..."
Turn 17 | Lanz (Mod) | D-Score: -0.19 | Val: +0.00 | "Ich wollte gerade sagen, ich als Mensch mit christlichem Hin..."
Turn 51 | Khorchide | D-Score: -0.08 | Val: -0.20 | "Identitätssuche, Identitätsfindung in der Religion. Ich rede..."
Turn 88 | Lanz (Mod) | D-Score: -0.24 | Val: -0.20 | "Was heißt das?..."
Turn 91 | Hübsch | D-Score: -0.16 | Val: -0.20 | "Wir haben Mitglieder, die kein Kopftuch tragen. Wir verstehe..."
🔬 Meso-Ebene 29
Turn 13 | Khorchide | D-Score: -0.08 | Val: -0.20 | "Ich habe nicht Hamas zitiert, ich habe den Propheten, was in..."
Turn 19 | Hübsch | D-Score: -0.20 | Val: -0.30 | "Wir haben das auf beiden Seiten, das gehört zur Wahrheit daz..."
Turn 39 | Hübsch | D-Score: -0.07 | Val: -0.30 | "Ich kann Ihnen nur sagen, dass es bei uns Thema ist...."
Turn 77 | Hübsch | D-Score: -0.20 | Val: -0.30 | "Das ist konstruktiver, als wenn man Leute vor die Wahl stell..."
Turn 81 | Hübsch | D-Score: -0.19 | Val: -0.30 | "Homosexuell? Wir haben Mitglieder. Die haben unterschiedlich..."
Turn 94 | Mansour | D-Score: +0.04 | Val: -0.50 | "Wir dürfen das auch kritisieren. Wenn das mit den Grundwerte..."
🔬 Meso-Ebene 31
Turn 37 | Hübsch | D-Score: -0.06 | Val: -0.30 | "Es gibt nicht einen einzigen Fall, der mir bekannt wäre, wo ..."
Turn 62 | Lanz (Mod) | D-Score: -0.27 | Val: +0.00 | "Aber das, worüber ich hier spreche, das beginnt schon lange ..."
Turn 64 | Lanz (Mod) | D-Score: -0.19 | Val: +0.00 | "Da meint man......"
Turn 66 | Khorchide | D-Score: -0.25 | Val: -0.20 | "Sie reden politisch über diejenigen, die sagen, Scharia ist ..."
Turn 92 | Lanz (Mod) | D-Score: -0.14 | Val: -0.10 | "Wann beginnt das, in welchem Alter?..."
Turn 96 | Lanz (Mod) | D-Score: -0.19 | Val: +0.00 | "Ich würde gerne zum Schluss, weil ich vermute, wir werden gl..."
🔬 Meso-Ebene 35
Turn 59 | Hübsch | D-Score: -0.18 | Val: -0.30 | "Weil wir politische Debatten haben. Im Moment ist die Entfre..."
Turn 61 | Hübsch | D-Score: -0.23 | Val: -0.30 | "Weil Deutschland international isoliert dasteht. Weil man ni..."
Turn 63 | Hübsch | D-Score: -0.16 | Val: -0.30 | "Wir haben zu problembehaftete Debatten. Wegen Scharia noch m..."
Turn 93 | Hübsch | D-Score: -0.13 | Val: -0.30 | "Das ist individuell. Herr Lanz, das ist wichtig. Sie müssen ..."
MAKRO-Regime 2 Agenda-Setting
-
Die Datenlage: Plötzlich positive Valenzen (+0.10, +0.30) und, ganz entscheidend, positive D-Scores (+0.12, +0.14).
-
Die Akteure: Lanz und Khorchide dominieren hier massiv.
-
Der Inhalt: Hier wird das Gespräch aktiv und konstruktiv auf eine neue Ebene gehoben („Sie haben mir gerade einen guten Übergang geliefert“, „Wir haben ein theologisches Problem“, „Vielleicht sollten wir das auch mal machen“).
-
Die System-Diagnose: Das ist der informationstheoretische Beweis für das Emergenz-Plateau. Das System tritt in echte kollektive Resonanz. Positive Disruptionen (
) bedeuten hier keinen Streit, sondern Agenda-Setting und Führung. Wahrheit/Sachlichkeit übernimmt die Kontrolle. Die Makro-Software dominiert, das Team entwickelt einen gemeinsamen, vorwärts gerichteten Gedanken.
 ) bedeuten hier keinen Streit, sondern Agenda-Setting und Führung. Wahrheit/Sachlichkeit übernimmt die Kontrolle. Die Makro-Software dominiert, das Team entwickelt einen gemeinsamen, vorwärts gerichteten Gedanken.
) bedeuten hier keinen Streit, sondern Agenda-Setting und Führung. Wahrheit/Sachlichkeit übernimmt die Kontrolle. Die Makro-Software dominiert, das Team entwickelt einen gemeinsamen, vorwärts gerichteten Gedanken.🔬 Meso-Ebene 15
Turn 15 | Khorchide | D-Score: -0.07 | Val: -0.20 | "Kurz das Argument zu Ende. Diese Koranstellen, die müssen hi..."
Turn 31 | Lanz (Mod) | D-Score: +0.12 | Val: +0.00 | "Ein theologischer Satz, dann eine Frage an Sie und dann Ahma..."
Turn 50 | Lanz (Mod) | D-Score: +0.02 | Val: +0.00 | "Sie haben mir gerade einen guten Übergang geliefert. Sie sag..."
Turn 79 | Hübsch | D-Score: -0.15 | Val: +0.00 | "Natürlich. Unsere Moscheen sind offen für alle Menschen...."
Turn 90 | Lanz (Mod) | D-Score: -0.02 | Val: -0.10 | "Kopftuch tragen, ja oder nein?..."
🔬 Meso-Ebene 18
Turn 11 | Khorchide | D-Score: -0.11 | Val: -0.20 | "Und nicht, dass es nicht für allgemeinere ist. Das ist nicht..."
Turn 60 | Lanz (Mod) | D-Score: -0.06 | Val: +0.00 | "Das ist wahr...."
Turn 75 | Hübsch | D-Score: -0.10 | Val: -0.30 | "Ich bin für beides. Meine Scharia sagt mir, ich muss mich an..."
Turn 86 | Lanz (Mod) | D-Score: -0.02 | Val: +0.00 | "Er hat nach Homosexualität gefragt...."
Turn 100 | Lanz (Mod) | D-Score: +0.00 | Val: +0.00 | "Die Situation kenne ich aus Israel. Genau...."
🔬 Meso-Ebene 34
Turn 32 | Khorchide | D-Score: -0.10 | Val: +0.10 | "Ich würde dem widersprechen. Wir haben ein theologisches Pro..."
Turn 53 | Khorchide | D-Score: +0.05 | Val: -0.20 | "Wenn Sie diese Jugendlichen fragen, was meinen Sie mit Schar..."
Turn 56 | Lanz (Mod) | D-Score: -0.04 | Val: +0.00 | "Und wie gesagt, weltweit. Es war sehr interessant, diese Unt..."
Turn 89 | Hübsch | D-Score: -0.03 | Val: -0.30 | "Keine Sexualität vor der Ehe gehört dazu. Man muss das nicht..."
🔬 Meso-Ebene 36
Turn 34 | Lanz (Mod) | D-Score: +0.12 | Val: -0.30 | "Ich würde gerne Frau Hübsch an dem Punkt fragen, weil das ge..."
Turn 52 | Lanz (Mod) | D-Score: +0.09 | Val: +0.30 | "Vielleicht sollten wir das auch mal machen, zum Christentum ..."
Turn 55 | Khorchide | D-Score: -0.24 | Val: +0.10 | "Und in Abgrenzung zu euch sage ich Scharia. Und das ist das ..."
Turn 58 | Lanz (Mod) | D-Score: +0.14 | Val: +0.00 | "Aber woher kommt das?..."
Auf dieser Basis ergeben sich Regeln, die in einem Hybride Collective Intelligence Dashboard verwendet werden. Sie unterstützen eine Führungskraft oder einen Moderator bei der Führung eines Teams bzw. der Moderation einer Gruppe
====================================================================== SYSTEM-DIAGNOSE: DIE QUANTITATIVEN WENN-DANN REGELN ====================================================================== >>> MAKRO-REGIME 0 <<< -------------------------------------------------- Meso-Ebene (Blatt-Knoten 2) | Vorhersage (y_hat): -0.486 | Datenpunkte: 5 WENN t-2 <= -0.337 UND t-6 <= -0.355 DANN fällt das System in Makro-Regime 0 Meso-Ebene (Blatt-Knoten 6) | Vorhersage (y_hat): -0.318 | Datenpunkte: 5 WENN t-2 <= -0.337 UND t-6 > -0.355 UND t-7 <= -0.213 UND t-6 > -0.234 DANN fällt das System in Makro-Regime 0 Meso-Ebene (Blatt-Knoten 7) | Vorhersage (y_hat): -0.422 | Datenpunkte: 5 WENN t-2 <= -0.337 UND t-6 > -0.355 UND t-7 > -0.213 DANN fällt das System in Makro-Regime 0 Meso-Ebene (Blatt-Knoten 13) | Vorhersage (y_hat): -0.303 | Datenpunkte: 4 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 <= -0.296 UND t-1 <= -0.351 UND t-4 > -0.206 DANN fällt das System in Makro-Regime 0 Meso-Ebene (Blatt-Knoten 24) | Vorhersage (y_hat): -0.320 | Datenpunkte: 4 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 <= -0.078 UND t-2 <= -0.203 UND t-1 <= -0.178 UND t-6 > -0.180 DANN fällt das System in Makro-Regime 0 Meso-Ebene (Blatt-Knoten 25) | Vorhersage (y_hat): -0.408 | Datenpunkte: 5 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 <= -0.078 UND t-2 <= -0.203 UND t-1 > -0.178 DANN fällt das System in Makro-Regime 0 Meso-Ebene (Blatt-Knoten 30) | Vorhersage (y_hat): -0.307 | Datenpunkte: 5 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 <= -0.078 UND t-2 > -0.203 UND t-8 > -0.290 UND t-1 > -0.208 DANN fällt das System in Makro-Regime 0 >>> MAKRO-REGIME 1 <<< -------------------------------------------------- Meso-Ebene (Blatt-Knoten 5) | Vorhersage (y_hat): -0.178 | Datenpunkte: 4 WENN t-2 <= -0.337 UND t-6 > -0.355 UND t-7 <= -0.213 UND t-6 <= -0.234 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 12) | Vorhersage (y_hat): -0.165 | Datenpunkte: 6 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 <= -0.296 UND t-1 <= -0.351 UND t-4 <= -0.206 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 17) | Vorhersage (y_hat): -0.215 | Datenpunkte: 5 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 <= -0.296 UND t-1 > -0.351 UND t-7 > -0.276 UND t-8 <= -0.223 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 23) | Vorhersage (y_hat): -0.230 | Datenpunkte: 6 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 <= -0.078 UND t-2 <= -0.203 UND t-1 <= -0.178 UND t-6 <= -0.180 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 27) | Vorhersage (y_hat): -0.168 | Datenpunkte: 5 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 <= -0.078 UND t-2 > -0.203 UND t-8 <= -0.290 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 29) | Vorhersage (y_hat): -0.219 | Datenpunkte: 6 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 <= -0.078 UND t-2 > -0.203 UND t-8 > -0.290 UND t-1 <= -0.208 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 31) | Vorhersage (y_hat): -0.142 | Datenpunkte: 6 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 > -0.296 UND t-6 > -0.078 DANN fällt das System in Makro-Regime 1 Meso-Ebene (Blatt-Knoten 35) | Vorhersage (y_hat): -0.238 | Datenpunkte: 4 WENN t-2 > -0.337 UND t-3 > -0.083 UND t-2 <= -0.108 UND t-8 > -0.209 DANN fällt das System in Makro-Regime 1 >>> MAKRO-REGIME 2 <<< -------------------------------------------------- Meso-Ebene (Blatt-Knoten 15) | Vorhersage (y_hat): -0.040 | Datenpunkte: 5 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 <= -0.296 UND t-1 > -0.351 UND t-7 <= -0.276 DANN fällt das System in Makro-Regime 2 Meso-Ebene (Blatt-Knoten 18) | Vorhersage (y_hat): -0.080 | Datenpunkte: 5 WENN t-2 > -0.337 UND t-3 <= -0.083 UND t-3 <= -0.296 UND t-1 > -0.351 UND t-7 > -0.276 UND t-8 > -0.223 DANN fällt das System in Makro-Regime 2 Meso-Ebene (Blatt-Knoten 34) | Vorhersage (y_hat): -0.065 | Datenpunkte: 4 WENN t-2 > -0.337 UND t-3 > -0.083 UND t-2 <= -0.108 UND t-8 <= -0.209 DANN fällt das System in Makro-Regime 2 Meso-Ebene (Blatt-Knoten 36) | Vorhersage (y_hat): 0.025 | Datenpunkte: 4 WENN t-2 > -0.337 UND t-3 > -0.083 UND t-2 > -0.108 DANN fällt das System in Makro-Regime 2
Literatur
[1] Rosas F E et al. (2024) Software in the natural world: A computational approach to hierarchical emergence, arXiv:2402.09090v2, 5 Jun 2024
[2] Jens Köhler und Alfred Oswald: Die Collective Mind Methode (2009)
Alfred Oswald, Jens Köhler, Roland Schmitt: Projektmanagement am Rande des Chaos (2016), auch in englischer Sprache verfügbar: Project Management at the Edge of Chaos, Springer 2018
Alfred Oswald und Wolfram Müller (editors): Management 4.0 – Handbook for Agile Practices, Release 3.0“, BoD 2019


















![[0, 1]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.png "Rendered by QuickLaTeX.com")