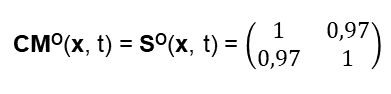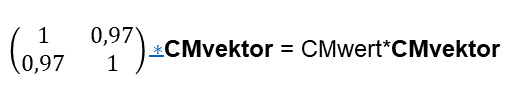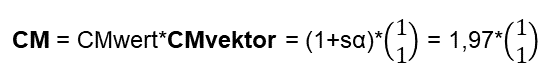Im diesem Blogartikel beschäftige ich mich mit der Erstellung von Text-Zusammenfassungen und Bild-Metaphern. Dies sind wichtige Bereiche jeglicher Informations- und Wissens-Verarbeitung, insbesondere auch im Management und Projektmanagement. – Man siehe hierzu auch meinen Blog-Beitrag vom Dezember 2021.
Ich beschreibe im Folgenden die Benutzung der verwendeten AI-Werkzeuge etwas genauer. – Vielleicht mag der ein oder andere meine Erfahrungen weiterentwickeln.
Da die verwendeten AI-Werkzeuge mehrere Abstraktionsebenen über den in den letzten Blog-Beiträgen verwendeten AI-Werkzeugen liegen und jene über eine recht einfache Benutzerschnittstelle angesprochen werden können, spreche ich von Black-Box AI-Werkzeugen
Für die Erzeugungen von Bild-Metaphern verwende ich die KI midjourney und für die Erzeugung von Text-Zusammenfassungen die KI GPT-3.
Auf die KI midjourney wurde ich über den Artikel „Kunst per Künstlicher Intelligenz“ von Patrick Hannemann aufmerksam [1]. Er stellt dort die Kommunikationsplattform discord.com [2] vor, die die KI midjourney über einen Bot integriert enthält [3].
Ich widme mich zuerst den Bild-Metaphern: Bild-Metaphern können zum Beispiel bei der Ausbildung eines Collective Minds in Teams eine sehr große Rolle spielen. – Sie dienen u.a. der Teamausrichtung und -fokussierung.
Also habe ich ausprobiert, inwieweit sich midjourney für die Kreation von Bild-Metaphern eignet. – Ich starte mit einem Thema zu meinem Bogenschieß-Hobby und gebe dem Bot über den Prompt ‚/imagine…‘ folgende Aufgabe: Kreiere ein Bild zu der Aussage „Ein Bogenschütze mit einem fantastisch schönen Bogen und goldenen Pfeilen“.
Der Bot liefert mehrere Bilder als Vorschläge zurück. Abbildung 1 zeigt das von mir ausgewählte Bild:

Für mich ist das Ergebnis beeindruckend kreativ und schön!
Ich habe daraufhin getestet, welche Bilder die AI aus der Kurzdefinition von Management 4.0 erzeugt. Abbildung 2 zeigt einen Screenshot-Auszug der vier generierten Bildvorschläge:
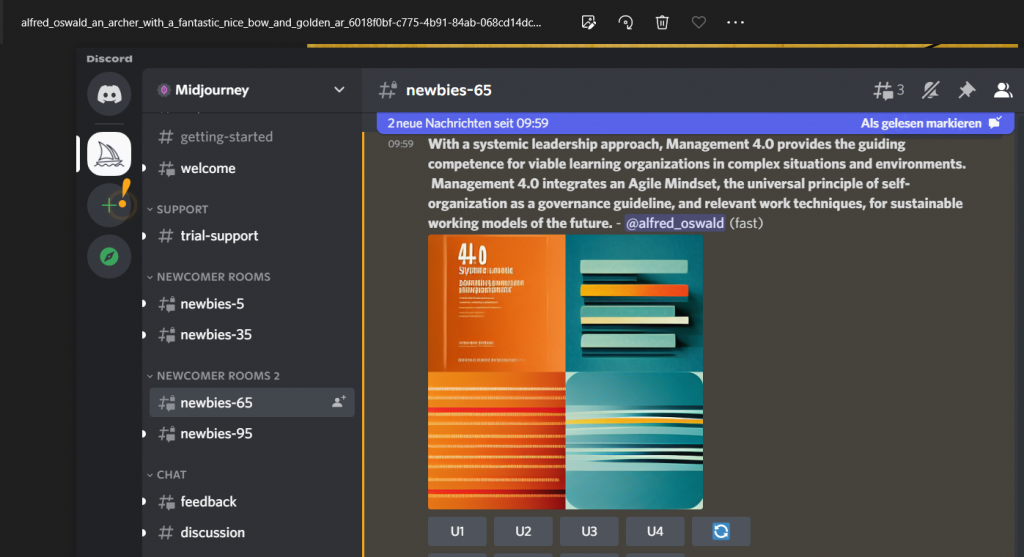
Das war wohl etwas abstrakt, die generierten Bilder sind recht nichtssagend 😉.
Eine Kürzung auf die wesentlichen, in der Definition enthaltenen Themen erzeugt jedoch innerhalb von wenigen Sekunden vier recht gute Bild-Metapher Vorschläge:
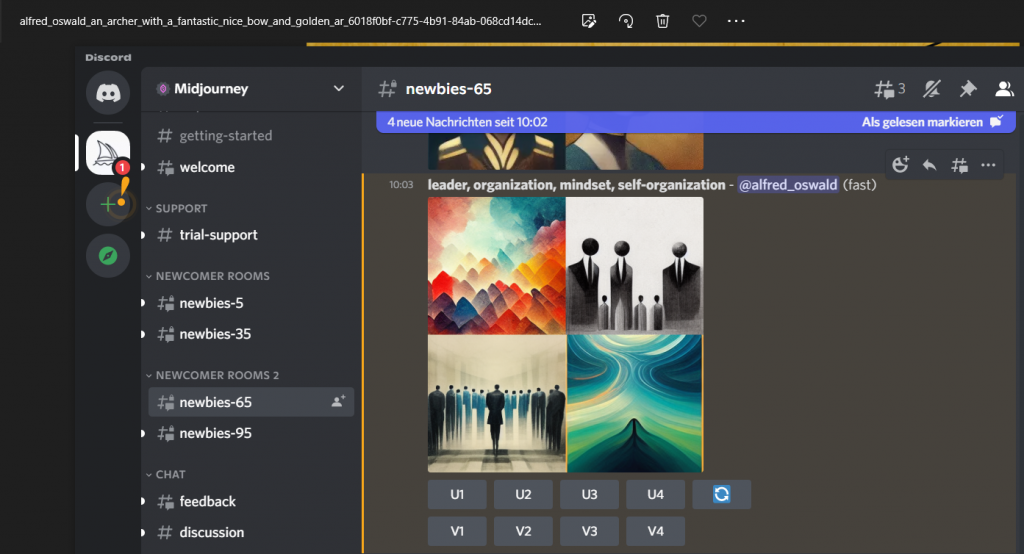
Ich habe das erste Bild für die weitere Generierung von Versionen ausgewählt und mich schließlich für folgende Bild-Metapher entschieden:

Dies ist ein Ergebnis, generiert nach ca. 5 Minuten Interaktion mit dem AI-Bot. Wie ich finde: beeindruckend!
Für den Bereich Bild-Metaphern fasse ich zusammen: Selbst öffentlich verfügbare AI-Systeme liefern beeindruckende Bild-Metaphern auf der Basis von Themen (Topics). Topics können aus von AI-Systemen generierten Wissens-Netzwerken (man siehe den Juni 2022 Blog-Beitrag) entnommen werden oder über spezifische Topic AI-Systeme [4], [5] generiert werden.
Legt man folgende Definition für eine Künstliche Allgemeine Intelligenz zugrunde, “Artificial general intelligence (AGI) is the ability of an intelligent agent to understand or learn any intellectual task that a human being can.“ [6], so ist der AI-Bot midjourney vermutlich noch weit von einer AGI entfernt.
Gleichwohl stelle ich für mich selbst fest, dass ich wohl kaum in der Lage bin, mit ähnlicher Kreativität wie diese AI, die oben gezeigten Bilder zu erzeugen.
Überträgt man die Messung des Intelligenzquotienten für Menschen auf AI-Systeme, so dürfte eine Zusammenschaltung von mehreren AI-Systemen schon heute fantastisch hohe Intelligenzquotienten ergeben. Die AI-Systeme, die im Jahre 2019 verfügbar waren, liefern IQ-Werte die bei ca. 25%-50% eines mittleren menschlichen IQ von 100 liegen. – Ein IQ von 50 entspricht in etwa dem IQ eines 6-jährigen Kindes [7], [8], [9]. Sehr große AI-Systeme wie GPT-3, das ich weiter unten verwende, waren in diesen Untersuchungen noch nicht berücksichtigt. – Für GPT-3 dürfte der IQ schon deutlich näher bei 100 liegen.
Sollte die AGI eines Tages Realität sein, so nehme ich an, dass keine 9 Milliarden AI-Systeme erforderlich sind, um das (kognitive) Intelligenzspektrum von 9 Milliarden Menschen abzubilden. – Wahrscheinlicher ist, dass einige wenige AI-Systeme das kognitive Intelligenzspektrum von Milliarden von Menschen abdecken werden, und dies mit wesentlich höheren IQ-Werten als wir Menschen im besten Fall haben.
Die Ergebnisse der Forschungsarbeit der GPM Fachgruppe Agile Management zum Thema NLP-Verarbeitung (Natural Language Processing Verarbeitung) von Projektmanagement Fragestellungen mittels AI-Systemen zeigen in diese Richtung.
Wir haben verschiedenen AI-Systemen PM Know-How Fragen gestellt, wie sie in einer Prüfung für das IPMA Level D vorkommen könnten. Das Ergebnis ist ziemlich beeindruckend: „Kleinere“ AI-Systeme liefern keine befriedigenden Ergebnisse, meistens sogar mangelhafte Ergebnisse. Jedoch liefert das große System GPT-3 von openai.com in allen! Fragen sehr gute oder gute Ergebnisse: GPT-3 hat hiernach das IPMA Level D Zertifikat mit gut bestanden! – Diese Ergebnisse haben wir auf der diesjährigen IPMA Research Konferenz vorgestellt [10], [11].
Ich widme mich jetzt den Text-Zusammenfassungen mittels GPT-3 [12], [13].
Ich nehme das Gesamtergebnis vorweg: Mein! Versuch mittels GPT-3 sinnvolle Zusammenfassungen von Texten zu erzeugen liefert (bisher) keine wirklich überzeugenden Ergebnisse. Es gibt also aktuell auch noch Wermutstropfen in dieser „schönen neuen AI-Welt“😉.
Ich habe dem AI-System GPT-3 die Aufgabe gestellt, für einen meiner Blog-Artikel eine Zusammenfassung zu erstellen. Ich habe den Beitrag vom September 2021 „Metabetrachtungen: Zur Schnittmenge von Intuitivem Bogenschießen, Künstlicher Intelligenz und Management 4.0“ ausgewählt. Er hat einen Bezug zur obigen Bild-Metapher Abbildung 1 und stellt verschiedene Themen (Bogenschießen, AI und M 4.0) in einen eventuell ungewöhnlichen Zusammenhang und ist damit ein Text, den man wahrscheinlich sonst nirgendwo im Internet finden kann. Die AI kennt also mit ziemlicher Sicherheit keine ähnlichen Texte.
Ich greife auf GPT-3 als Black-Box AI-System zu und nicht wie für andere AI & M 4.0 Blog-Beiträge auf verschiedene AI/ML Bibliotheken. Wie bei der Unterhaltung mit dem AI-Bot midjourney ist auch hier das Abstraktionsniveau der „Ansprache“ sehr hoch.
Um Zugriff auf GPT-3 zu erhalten [13], ist es notwendig, sich bei openai.com zu registrieren. Solange man GPT-3 nicht für produktive Zwecke nutzen will, wird ein budgetierter Zugang von $18 als Geschenk freigegeben. Openai.com orientiert sich für die Freigabe an einer Risiko-Bewertung: Forschungsaktivitäten, wie ich sie hier durchgeführt habe, werden als sandbox-Aktivitäten behandelt und unterliegen keinen Restriktionen. – Dies ist sehr ähnlich den Anforderungen, die im EU AI Act zu finden sind. – Man siehe hierzu meinen Blogbeitrag vom August 2022.
Eine Möglichkeit auf GPT-3 zuzugreifen, ist der Zugriff über das User Interface ‚Playground‘ (man siehe Abbildung 5).
In ersten Versuchen habe ich die sogenannten Presets verwendet (man siehe Abbildung 5, und dort die rot eingefassten Bereiche). – Dies sind vorkonfektionierte Aufgabentypen, u.a. auch für die Erstellung von Zusammenfassungen. Die Ergebnisse waren richtig schlecht und recht oft unsinnig: Teilweise wurden Texte abgerufen, in denen wohl ein Bogenschütze auf die Jagd geht oder der deutsche Text, der zusammenzufassen war (man kann also auch nicht-englischen Text eingeben), wurde „einfach“ übersetzt.
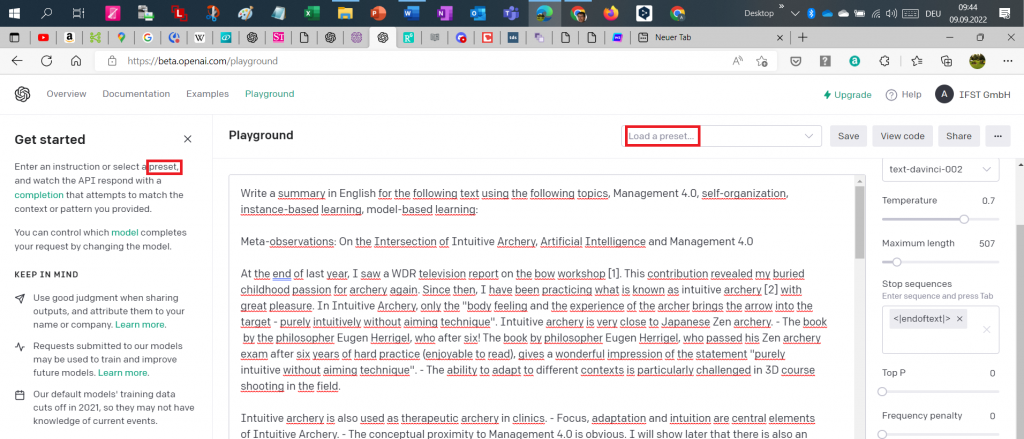
Wie ich heute weiss, habe ich mit den presets das Potential von GPT-3 überhaupt nicht angesprochen. – Man kann nämlich über die Prompteingabe mit GPT-3 „reden“, d.h. der AI in Satzform sagen, was sie machen soll. Die Aufgabe „Write a summary in English for the following text using the following topics, Management 4.0, self-organization, instance-based learning, model-based learning:” (siehe Abbildung 5 erster Satz im Eingabefeld) brachte bisher das beste Zusammenfassungs-Ergebnis:
“The article discusses the intersection of intuitive archery, artificial intelligence, and management 4.0. It argues that learning is the key element to align the human system, the technical system neural network, and the social system team or organization to the environment. The article distinguishes between instance-based learning and model-based learning. It argues that learning in management 4.0 is model-based learning, and that instance-based learning is insufficient for learning in a complex context.”
An diesem Ergebnis kann man erkennen, dass GPT-3 in der Lage ist, explorative und abstrahierende Zusammenfassungen zu erstellen. Explorative Zusammenfassungen enthalten lediglich Sätze aus dem Original, die als wichtig erkannt werden. Abstrahierende Zusammenfassungen enthalten neue Sätze, die so nicht im Original enthalten sind.- Die abstrahierende Zusammenfassung ist u.a. an Sätzen wie „The article distinguishes…“ zu erkennen.
Ich habe dieses Ergebnis als bestes ausgewählt, weil dies das einzige Beispiel ist, in dem der Satz „It argues that learning in management 4.0 is model-based learning, and that instance-based learning is insufficient for learning in a complex context.” enthalten ist. Dieser Satz ist eine zentrale Erkenntnis des Blog-Beitrages. Leider sind nicht alle Erkenntnisse enthalten; z.B. wird das Thema Selbstorganisation als zentrales verbindendes Element der drei Bereich, Management 4.0, AI und Bogenschießen, nicht erkannt. Deshalb gebe ich GPT-3 in diesem Fall auch nur die Schulnote ausreichend.
Im Playground können nur Texte eingegeben werden, deren Anzahl an Tokens (ungefähr gleich der Anzahl an Worten), addiert mit der Anzahl an Tokens für die Zusammenfassung, 4000 Tokens nicht überschreiten. Ich habe für die Zusammenfassung 507 Tokens vorgegeben und habe damit noch ca. 3500 Tokens für den eigentlichen zusammenzufassenden Text zur Verfügung. Falls der Text in einer Fremdsprache eingegeben wird, halbiert sich der verfügbare Raum für den Text auf etwa die Hälfte an Tokens: GPT-3 benötigt Raum für die Übersetzung. – Die „Muttersprache“ von GPT-3 ist Englisch! Aus diesem Grund konnte ich auch nur einen Auszug des Blogs verwenden. Aus Gründen der Vergleichbarkeit habe ich für die deutschen und die englischen Texte den Auszug gleich beibehalten und jeweils ca. 1400 Wörtern verwendet. In allen Tests habe ich die von opneai.com empfohlene Stop sequence <|endoftext|> am Ende des Textes eingesetzt. – Das Verwenden einer Stop sequence zum Anzeigen des Textendes hat einen recht großen Einfluss auf das Zusammenfassungsergebnis.
Statt GPT-3, verwende ich den google-Übersetzer [15] und den Übersetzer deepl.com [17], um einen englischen Text für meinen Blog-Beitrag zu erzeugen. Die Übersetzungen sind sehr ähnlich, wobei meines Erachtens bei genauerer Betrachtung doch manchmal recht große Unterschiede auffallen. So übersetzt zum Beispiel deepl.com „Meta-Betrachtungen“ mit „Meta-observations“ und der google-Übersetzer mit „Meta considerations“. – Dies scheint mir ein nicht unerheblicher Unterschied zu sein.
Google verändert auch in erheblichem Maße die Syntax. So wurde wie hier zu sehen, u.a. der Bindestrich zwischen Meta und consideration einfach entfernt. Groß- und Kleinschreibung und Satzzeichen wurden verändert, so dass selten – aber immerhin geschah es – sich ein vollständig anderer Sinn ergeben hat. Mehrmals wurden ganze Satzteile einfach weggelassen. – Ein schwerwiegender Fehler.
Bei deepl.com ist dies im vorliegenden Beispiel einmal vorgekommen bei google dreimal. Der google-Übersetzer liefert auch leicht andere Ergebnisse, je nachdem, ob man ihn mit einer zu übersetzenden Internetseite füttert oder einer Worddatei, die den Inhalt der Internetseite enthält.
Ich betone dies, weil beide Übersetzer mit AI betrieben werden. Es ist nicht auszuschließen, dass die AI sauber funktioniert, jedoch die Aufbereitung der Daten, also der Texte, nicht fehlerfrei ist. – Versteckte Satzzeichen oder Abschnittszeichen werden unterschiedlich interpretiert. Die AI-Systeme benötigen trotz ihrer „Intelligenz“ Daten in einer wohldefinierten Form. – Es gibt keinen Spielraum für „intelligentes Ausbessern“ wie in der menschlichen Kommunikation. Das macht das Arbeiten mit AI-Systemen nicht selten zu einem Geduldsspiel. Die korrekte Dateneingabe wurde, nach meiner bisherigen Erfahrung, von AI-Erstellern nicht gut dokumentiert.
Um die Restriktion bezüglich des Textumfanges zu umgehen, kann man GPT-3 auch über ein Jupyter Notebook [17] in der Colab-Umgebung [18] ansprechen. – Man beachte, GPT-3 ist in der Colab-Umgebung aufrufbar, obwohl google und openai im Wettbewerb stehen. – Bemerkenswert erfreulich!
Ich habe den Code von [19] verwendet und für meine Aufgabenstellung angepasst. Für den vollständigen Text in Deutsch erzeugt GPT-3 eine deutlich größere explorative Zusammenfassung in Englisch, obwohl ich GPT-3 um eine deutsche Zusammenfassung gebeten habe.
Den mittels deepl.com ins Englische übersetzten Blog-Artikel habe ich einmal als .pdf Datei Seite für Seite eingelesen und alternativ direkt als Text in die Colab-Umgebung eingebracht. In beiden Fällen wurde eine abstrahierende Zusammenfassung erstellt. Die erste Zusammenfassung entspricht der schon bekannten besten Zusammenfassung, die zweite Zusammenfassung ist eine andere:
“The article discusses the intersections of intuitive archery, artificial intelligence, and Management 4.0. Intuitive archery is a form of archery that does not rely on aiming technique, and is used for therapeutic archery in clinics. The author argues that the ability to focus, adapt, and intuition are central elements of Intuitive Archery, which are also important for Management 4.0. The author describes their experience with a Deep Learning course using Tensorflow, and how it has helped them understand the potential for artificial intelligence in project management.”
Ich konnte also an meiner Aufgabenstellung nicht erkennen, dass GPT-3 mit jedem Aufgabendurchlauf dazu lernt. – Eine Aussage, die andere schon getroffen haben [12].
Zusammenfassung: Meine Untersuchungen zu Text-Zusammenfassungen mittels GPT-3 und Bild-Metaphern mittels midjourney zeigen schon recht gute Ergebnisse, jedoch ist Vorsicht geboten, wenn man die Werkzeuge (schon) im produktiven Betrieb benutzen möchte. Jedoch ist schon heute auf einfachen Wegen selbst erfahrbar, dass der Weg in Richtung einer Künstlichen Allgemeinen Intelligenz eingeschlagen wurde.
[1] Hannemann P (2022) Kunst per künstlicher Intelligenz: Mit diesen Tools können Sie das selbst ausprobieren, https://www.chip.de/news/Kunst-per-kuenstlicher-Intelligenz-Mit-diesen-Tools-koennen-Sie-das-selbst-ausprobieren_184386657.html, zugegriffen am 06.09.2022
[2] Discord (2022) Discord.com, Innovative Kommunikationsplattform, zugegriffen am 06.09.2022
[3] midjourney(2022) Forschungsprojekt zu AI, https://www.midjourney.com/home/, zugegriffen am 06.09.2022, zugegriffen am 06.09.2022
[4] Keita Z (2022) Meet BERTopic— BERT’s Cousin For Advanced Topic Modeling, https://towardsdatascience.com/meet-bertopic-berts-cousin-for-advanced-topic-modeling-ea5bf0b7faa3, zugegriffen am 09.04.2022
[5] Dwivedi P (2022) NLP: Extracting the main topics from your dataset using LDA in minutes, https://towardsdatascience.com/nlp-extracting-the-main-topics-from-your-dataset-using-lda-in-minutes-21486f5aa925, zugegriffen am 09.04.2022
[6] Wikipedia (2022) Artificial General Intelligence, https://en.wikipedia.org/wiki/Artificial_general_intelligence, zugegriffen am 06.09.2022
[7] Liu Y, He F, Zhang H, Rao G, Feng Z and Zhou Y (2019) How Well Do Machines Perform on IQ tests: a Comparison Study on a Large-Scale Dataset, Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19)
[8] Tschopp M, Ruef M (2019) An Interdisciplinary Approach to Artificial Intelligence Testing: Developing an Artificial Intelligence Quotient (A-IQ) for Conversational AI, siehe researchgate.net
[9] Liu F, Liu Y, Shi Y (2020) Three IQs of AI systems and their testing methods, https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/joe.2019.1135, zugegriffen am 05.09.2022
[10] Nuhn H, Oswald A, Flore A, Lang R, (2022) AI-supported Natural Language Processing in project management – capabilities and research agenda, IPMA Research Conference 2022, www.ipma-research-conference.world
[11] Lang R (2022) Kann Künstliche Intelligenz (KI) das Projektmanagement unterstützen? https://www.linkedin.com/feed/update/urn:li:activity:6970285127754997760/, zugegriffen am 09.09.2022
[12] Romero A (2022) A Complete Overview of GPT-3 — The Largest Neural Network Ever Created, https://towardsdatascience.com/gpt-3-a-complete-overview-190232eb25fd, zugegriffen am 09.08.2022
[13] Willison S (2022) How to play with the GPT-3 language model, https://simonwillison.net/2022/Jun/5/play-with-gpt3/, zugegriffen am 09.08.2022
[14] GPT-3 playground (2022) openai.com, zugegriffen am 09.09.2022
[15] google Übersetzer (2022) https://translate.google.de/?hl=de&tab=rT, zugegriffen am 09.09.2022
[16] Deepl (2022) https://www.deepl.com/translator, zugegriffen am 09.09.2022, verwendet für diesen Blog-Beitrag in der kostenpflichtigen Version deepl Pro
[17] Jupyter Notebooks (2021) https://jupyter.org/, zugegriffen am 02.12.2022
[18] Colab (2021) https://colab.research.google.com/
[19] Soares L (2022) Summarizing Papers With Python and GPT-3, https://medium.com/p/2c718bc3bc88, zugegriffen am 22.07.2022