
Kurzfassung: In diesem Beitrag untersuche ich die praktische Anwendung von Quantencomputern im Finanzsektor mittels einer hybriden Quantum Asset Portfolio Optimisation (QAPO). Ich kombiniere die quantenmechanische Asset-Selektion eines D-Wave-Systems mit einer klassischen Minimum-Variance-Kapitalallokation. Durch ein strenges Out-of-Sample-Backtesting unter realen Transaktionskosten demonstriere ich transparent, wie das Modell auf unterschiedliche Marktphasen reagiert. Ein besonderer Fokus liegt auf der Architektur von ‚All-Wetter-Portfolios‘ und dem Verhalten unkorrelierter Assets wie Gold, die als Volatilitäts-Stoßdämpfer fungieren. Zudem erkläre ich anschaulich die physikalischen Vorteile des makroskopischen Quantentunnelns gegenüber klassischer Optimierung. Der Beitrag zeigt, wie Quantum Finance schon heute für (private) Anleger in die Praxis umgesetzt werden kann.
Den folgenden Blog-Beitrag habe ich noch überwiegend mit ChatGPT erstellt. Während der Erstellung nahm die KI-Demenz des Systems enorm zu: ChatGPT hat immer wieder schon erarbeitete Zusammenhänge vergessen. Außerdem hat sich an der schlechten Qualität des Codes für Latex unter WordPress nichts geändert. Dies hat mich bewogen, auf Google Gemini 3 Pro umzusteigen: Das System vergisst (aktuell) nichts, macht mich sogar auf Zusammenhänge zu vergangenen Ergebnissen aufmerksam und erzeugt lauffähigen Latex Code für WordPress. – Gemini hat den Prompt für das Eingangsbild erzeugt und ChatGPT hat diesen umgesetzt.
Dieser Blog-Beitrag ist der zweite Beitrag in der Blog Reihe ‚Quantum Asset Portfolio Optimisation‘ (QAPO). Ziel dieses Beitrages ist es, einen Algorithmus zu entwickeln, der eine persönliche Anlagestrategie von Assets (u.a. Aktien, ETFs) unterstützen kann.
Schaut man sich die Entwicklung der letzten Wochen und Tage an, so nehmen die (medialen) Veröffentlichungen zum Thema Quantum Computing (QC) immer mehr Fahrt auf.
Ich sehe drei große Themenbereiche, in denen sich das QC entwickelt:
- Der Aufbau von großen stabilen Qubit Hardware Systemen: Dieser Bereich erfährt derzeit die meiste mediale Aufmerksamkeit
- Die Entwicklung von Anwendungsfällen, in denen QC seine ungeheuren Möglichkeiten zeigen kann. Dieser Bereich zeigt meines Erachtens in den letzten Wochen enorme Fortschritte: QC wird u.a. mit KI Systemen kombiniert und liefert bahnbrechende Erkenntnisse. Nimmt man zum Beispiel die Likes auf Linkedin zu Veröffentlichungen als Indikator für die mediale Aufmerksamkeit, so ist diese allerdings sehr gering. – In meinem nächsten Blog-Beitrag werde ich deshalb hierzu einen faszinierenden Anwendungsfall behandeln.
- Die Optimierung des Wechselspiels von klassischen Systemen und QC: Im letzten Blog habe ich schon erwähnt, dass die Anwendung eines QAOA Qiskit Python Codes auf entsprechender IBM Hardware wenig erfolgreich war, da mein Rechenbudget nahezu vollständig vom klassischen Rechnen ‚aufgefressen‘ wurde. Die typischen QC Gate Laufzeiten liegen im Mikro- bis Milli-Sekunden Bereich, so dass 1000 bis 1 Mio. Wiederholungen zusammenkommen müssen, damit sich im QC eine Gesamtlaufzeit von einer Sekunde aufbaut. Im Anhang 1 habe ich deshalb die ‚Zeitfaktoren‘ pro QC Methode zusammengestellt. Man kann sehr schnell erkennen, dass für Gesamtlaufzeiten (also klassisch+quantum Laufzeit) von maximal einer Stunde ein überwiegender Teil der Rechenzeit in die klassische Aufbereitungs- und Nachbearbeitungszeit fließt.
Im Jahre 2024 habe ich erstmals mit QC Hardware gerechnet. Damals war es noch sehr einfach und schnell ein kleines aber ausreichendes Kontingent an (kostenloser) QC Rechenzeit zu erhalten. Heute ist dies ungleich schwieriger. Da die Simulations-Rechenzeit für das QAOA schon im Stundenbereich liegt und das Laufzeitverhalten auf der IBM Hardware für mich nicht transparent ist, verzichte ich für diesen Blog auf die QAOA Methode und konzentriere mich lediglich auf die D-Wave Methode.
Aber auch hier habe ich bisher keinen Hardware Zugang erhalten. Der Übergang auf die D-Wave Hardware macht evtl. aus zwei Gründen Sinn:
- Das Problem ist so groß, dass eine Simulation in 1-2 Stunden zu keinem guten Ergebnis kommt. Die Einschränkung von 1-2 Stunden erscheint sinnvoll, da ich das QAPO für meine persönliche Anlagenstrategie verwenden will. Da die Rechenzeiten auf meinem Laptop, für 44 Assets und einer Portfolio Auswahl von 4 Assets, im Ein-Minutenbereich liegen, ist der Wechsel auf eine D-Wave Hardware aus diesem Grunde noch nicht notwendig.
- Man möchte den energetisch tiefsten Zustand finden, also das beste Portfolio aus einer gegebenen Anzahl an Assets. Quantenmechanische Systeme können nicht nur unglaublich große Probleme bearbeiten, sie tun dies auch anders als klassische Systeme: Energetisch tiefe Zustände (also Täler) sind durch energetische hohe Zustände (also Berge) voneinander getrennt. In klassischen Systemen muss Energie zugeführt werden um ein System über einen Berg in ein neues Tal zu hieven. Es kostet also viel Zeit, immer wieder so einen Hebeprozess durchzuführen, um schließlich in der gesamten Energielandschaft den niedrigsten Zustand zu finden. Quantensysteme können durch die Energiebarrieren (Berge) hindurchtunneln. Sie sparen sich also sehr viel Zeit, um das niedrigste Tal zu finden. Leider ist die D-Wave Simulation eine solche klassische Simulation: Es könnte also sein, dass mit der Simulation nicht das niedrigste Tal, also das beste Portfolio gefunden wird. Da ich bisher keinen D-Wave Hardware Zugang habe, muss ich mit dieser Einschränkung arbeiten.- Falls ich den Zugang noch bekommen sollte, ist dies sicherlich später eine Beitragsergänzung wert.
Die Grundidee des D-Wave Algorithmus ist recht einfach: Mittels yahoo finance werden für 252 Tage vergangene Kurse einer Asset-Watchlist geladen und die Renditen und die Kovarianzen dieser Assets ermittelt. Es wird eine Hamiltonfunktion als Zielfunktion definiert und in der Energielandschaft dieser Funktion mittels Annealing nach dem niedrigsten Tal gesucht. – Die Hamiltonfunktion enthält als Nebenbedingung, dass nur K Assets aus der Watchlist auszuwählen sind. Der Annealing Teil des gesamten Alogrithmus wird entweder quantenmechanisch oder klassisch durchgeführt. In der Simulation werden die Qubits klassisch über kleine Magnete simuliert. Das niedrigste Tal innerhalb einer vorgegebenen Anzahl an Suchvorgängen (Annealing Vorgänge) liefert die unkorreliertesten und stärksten Assets innerhalb dieser Suchvorgänge. Mit Hilfe dieser K Assets verteilt ein weiterer klassischer Algorithmus ein vorgegebenes Kapital auf diese K Assets. Die Verteilung findet so statt, dass die Varianz der Assets minimiert wird. Theoretisch sollte diese Kapitalallokation auch über den quantenmechanischen Algorithmus stattfinden. Falls man die Kapitalallokation nur schon in 10% Schritten vornimmt, ist jedes bisherige Qubit, das lediglich angibt ob ein Asset ausgewählt wurde, durch 10 Qubits zu ersetzen. Die klassische Simulation hierzu scheitert an der Anzahl der Zustände, die größer ist als die geschätzte Anzahl an Atomen im Universum. Und die quantenmechanische Rechnung scheitert derzeit noch an der Anzahl an kohärenten Qubits in aktuellen Hardwaresystemen. Durch die Aufteilung in Asset-Auswahl (Quantum, in der Simulation auch klassisch) und Kapitalallokation (klassisch) schneiden wir theoretisch einen Teil des Lösungsraums ab. Wir finden eine heuristische Näherung, und nicht das globale Minimum. Aber genau dieser Kompromiss ist aktuell zwingend nötig, um reale Finanzprobleme auf heutigen Quantencomputern überhaupt berechnen zu können, ohne dass die Fragilität der Qubits (Noise) Ergebnisse verhindert.
Mit dieser Einschränkung konstruiere ich den Prognose-Algorithmus für die Wertentwicklung der ausgewählten K Assets: Bei 252 Handelstagen pro Jahr soll jeden Monat (21 Handelstage im Mittel) eine Überprüfung der K Assets vorgenommen werden und ggf. Assets ausgetauscht werden. Natürlich fallen für den Austausch Transaktionskosten an, die die Gesamtrendite schmälern. Ich nehme 0,25 % des Anlagevolumens für die Transaktionskosten an. Vorherige Tests haben ergeben, dass eine wöchentliche Umschichtung zu teuer wird und eine Umschichtung pro Quartal weniger Rendite erwirtschaftet. Das Anlagevolumen habe ich auf 1 Million Euro gesetzt.
Auf dieser Basis starte ich mit 252 vergangenen Handelstagen als Trainingsdaten und ermittele das beste K Asset. Der Algorithmus schiebt die 252 Tage 21 Tage nach vorne und ermittelt wieder das beste K Asset, usw. – Es liegt also ein gleitendes Berechnungsfenster vor. Der Algorithmus soll ein Jahr in die Zukunft prognostizieren (sogenanntes Out-of-Sample (OOS) für ein Jahr).
Ich verweise auf Anhang 2 für eine ergänzende Beschreibung des Algorithmus.
Ich benutze folgende Watchlist:
=== Lade Marktdaten (Benötigt: 504 Handelstage) ===
Zeitraum: 2024-04-01 bis 2026-03-09
Verbleibende Assets nach Filterung: 43
=======================================================
=== IN-SAMPLE DIAGNOSE beim Start MIT KAPITAL-ALLOKATION ===
=======================================================
Die D-Wave Simulation hat folgende 4 Assets am Start als optimal identifiziert (Minimum-Variance):
- 2330.TW | Gewicht: 15.00% | Budget: 150,000.00 €
- ABEA.DE | Gewicht: 17.95% | Budget: 179,481.81 €
- RWE.DE | Gewicht: 32.05% | Budget: 320,518.19 €
- ^DJI | Gewicht: 35.00% | Budget: 350,000.00 €
=======================================================
=== STARTE OUT-OF-SAMPLE BACKTEST (FORECASTING) ===
=======================================================
Trainingsfenster: 252 Tage
Rebalancing: Alle 21 Tage
Startkapital: 1,000,000.00 €
Transaktionsgebühren: 0.25% pro umschichtetes Volumen
Leitplanken: Min 15.0% / Max 35.0% pro Asset
Allokation: Minimum-Variance-Portfolio
Simuliere 12 Rebalancing-Zyklen (Monatlich)...
=== OUT-OF-SAMPLE PERFORMANCE ===
Zeitraum: 2025-03-20 bis 2026-03-09 (252 Tage)
Endkapital: 1,345,730.50 € (Gewinn: 345,730.50 €)
Rendite (annualisiert):+37.28%
Volatilität (ann.): 20.01%
Sharpe Ratio: 1.58
Max Drawdown: -13.28%
Total Turnover: 8.66x umgeschlagen
Abbildung 1: Diese Abbildung zeigt die oben prognostizierte Out-of-Sample (OOS) Entwicklung der K Assets. Unten in der Abbildung wird monatlich die prognostizierte Rendite der realen Rendite gegenüber gestellt: Die Prognose kann natürlich keine geopolitischen Probleme (Zölle, Naher Osten) wie zum Beispiel im Juli 2025 vorhersehen. – Was sich in diesem speziellen Zeitraum sehr positiv auswirkt.
Da der Algorithmus Assets mit geringer Varianz bevorzugt, zeige ich im Folgendem, wie mit Aktien nahezu unkorrelierte Assets (wie Gold, Anleihen, Bitcoin, Immobilien) in die Prognose eingehen. Ich habe folgende unkorrelierte Assets, zusätzlich zu den obigen Assets, ausgewählt:
„GLD“, # Gold ETF (Sicherer Hafen)
„TLT“, # 20+ Year US Treasury Bonds (Krisen-Absicherung)
„BTC-USD“, # Bitcoin (Rendite-Booster)
„VNQ“ # US Real Estate ETF (Immobilien)
Auf dieser Basis ergeben sich die nachfolgenden Ergebnisse: Da Bitcoin auch an Feiertagen und nicht nur von Mo. bis Fr. gehandelt werden, ist der Zeitraum für die Markdaten nicht 100% identisch mit dem obigen Zeitraum, die Abweichung von 2 Tagen ist aber minimal. Zusätzlich enthält diese Ergebnis-Ausgabe die monatlich neu prognostizierten K Assets (siehe Bereich ‚Simuliere 12 Rebalancing-Zyklen).
=== Lade Marktdaten (Benötigt: 504 Handelstage) ===
Zeitraum: 2024-04-03 bis 2026-03-09
Verbleibende Assets nach Filterung: 47
=======================================================
=== IN-SAMPLE DIAGNOSE beim Start VIA Simulation ===
=======================================================
Die D-Wave Simulation hat folgende 4 Assets am Start als optimal identifiziert (Minimum-Variance Allokation):
- GLD | Gewicht: 35.00% | Budget: 350,000.00 €
- GOOGL | Gewicht: 15.00% | Budget: 150,000.00 €
- MBB.DE | Gewicht: 18.54% | Budget: 185,405.02 €
- ^IXIC | Gewicht: 31.46% | Budget: 314,594.98 €
=======================================================
=== STARTE OUT-OF-SAMPLE BACKTEST (FORECASTING) ===
=======================================================
Trainingsfenster: 252 Tage
Rebalancing: Alle 21 Tage
Startkapital: 1,000,000.00 €
Transaktionsgebühren: 0.25% pro umschichtetes Volumen
Leitplanken: Min 15.0% / Max 35.0% pro Asset
Simuliere 12 Rebalancing-Zyklen (Mode: 'sim')...
------------------------------------------------------------
-> Datum: 2025-03-21 | Portfolio: AHLA.DE (15.0%), DTE.DE (35.0%), RHM.DE (15.0%), ^HSI (35.0%)
-> Datum: 2025-04-21 | Portfolio: 639.DE (15.0%), RHM.DE (15.0%), TLT (35.0%), ^IXIC (35.0%)
-> Datum: 2025-05-20 | Portfolio: 2330.TW (15.3%), GLD (35.0%), RHM.DE (15.0%), ^IXIC (34.7%)
-> Datum: 2025-06-18 | Portfolio: DTE.DE (35.0%), IBM.F (15.0%), RHM.DE (15.0%), VNQ (35.0%)
-> Datum: 2025-07-17 | Portfolio: GLD (35.0%), GOOGL (15.0%), RHM.DE (15.0%), TLT (35.0%)
-> Datum: 2025-08-15 | Portfolio: GLD (35.0%), MBB.DE (35.0%), RHM.DE (15.0%), SFT.F (15.0%)
-> Datum: 2025-09-15 | Portfolio: 0PTN.IL (26.9%), EOS.AX (15.0%), GLD (35.0%), RHM.DE (23.1%)
-> Datum: 2025-10-14 | Portfolio: EOS.AX (15.0%), GLD (35.0%), RHM.DE (15.0%), ^IXIC (35.0%)
-> Datum: 2025-11-12 | Portfolio: GLD (35.0%), RHM.DE (15.0%), SFT.F (15.0%), ^IXIC (35.0%)
-> Datum: 2025-12-11 | Portfolio: DTE.DE (33.5%), GOOGL (24.3%), RHM.DE (15.0%), RWE.DE (27.2%)
-> Datum: 2026-01-09 | Portfolio: EOS.AX (15.0%), GLD (35.0%), RHM.DE (15.0%), RWE.DE (35.0%)
-> Datum: 2026-02-09 | Portfolio: GLD (25.5%), GOOGL (15.0%), RWE.DE (35.0%), ^IXIC (24.5%)
------------------------------------------------------------
=== OUT-OF-SAMPLE PERFORMANCE ===
Zeitraum: 2025-03-21 bis 2026-03-09 (252 Tage)
Endkapital: 1,168,157.89 € (Gewinn: 168,157.89 €)
Rendite (annualisiert):+19.32%
Volatilität (ann.): 20.57%
Sharpe Ratio: 0.86
Max Drawdown: -15.86%
Total Turnover: 7.38x umgeschlagen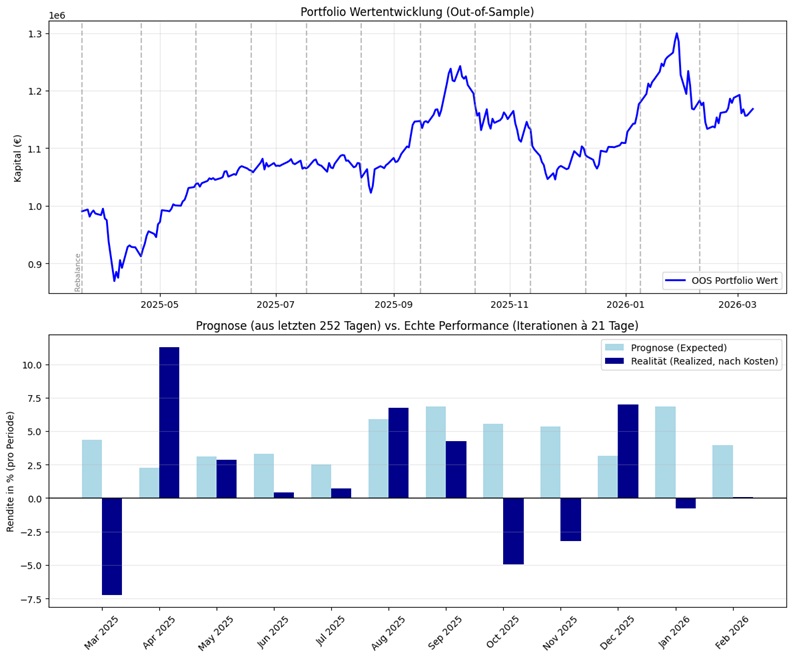
Abbildung 2: Diese Abbildung zeigt die oben prognostizierte Out-of-Sample (OOS) Entwicklung der 44+4 K Assets (ein Asset wurde entfernt, da nicht ausreichend Daten vorliegen). Unten in der Abbildung wird monatlich die prognostizierte Rendite der realen Rendite gegenüber gestellt.
Überraschender Weise zeigt dieses Portfolio eine leicht höhere Volatilität, es werden andere Fehler-Zeitpunkte zwischen Prognose und Realität angezeigt und die Rendite geht deutlich zurück:
Warum bricht die Gesamtrendite massiv ein? (37 % vs. 19 %)
Wir befinden uns in dem Zeitraum von April 2024 bis März 2026. In dieser Phase gab es an den Börsen massive, einseitige Bullenmärkte (insbesondere bei Tech-Werten wie Nvidia, TSMC, Google und Rüstungswerten wie Rheinmetall).
-
Ohne unkorrelierte Assets: Der Algorithmus war gezwungen, sein gesamtes Geld in den Aktienmarkt zu stecken. Er verwendete also voll die sehr gut laufenden Tech- und Rüstungs-Werte. Das brachte gigantische Gewinne.
-
Mit unkorrelierten Assets: Der Algorithmus sucht nach Minimum-Variance (minimalem Risiko). Er sieht, dass Tech-Aktien stark schwanken. Also nutzt er die neuen ’sicheren Häfen‘ wie Gold (GLD) oder langlaufende Staatsanleihen (TLT) und packt diese mit bis zu 35 % ins Portfolio.
-
Die Konsequenz: Diversifikation kostet in einem extremen Bullenmarkt immer Rendite! Parkt man 35 % des Geldes in Gold, das vielleicht ’nur‘ 10 % im Jahr an Rendite zeigt, fehlen diese 35 % bei den Tech-Aktien, die in derselben Zeit vielleicht 60 % Rendite erzielen. Der Algorithmus hat also Rendite für (vermeintliche) Sicherheit geopfert.
Warum ist die Volatilität dann trotzdem leicht höher? (20,5 % vs 20,0 %)
Korrelationen sind nicht stabil:
-
Die Theorie sagt: Anleihen (TLT) und Immobilien (VNQ) federn Aktienkrisen ab.
-
Die Realität der letzten Jahre (Zinswenden, Inflation) war aber: Wenn die Zentralbanken die Zinsen hochhielten oder überraschende Inflationsdaten kamen, sind Staatsanleihen (TLT) und Immobilien (VNQ) zusammen mit den Aktien abgestürzt.
-
Der Algorithmus hat in die Vergangenheit geschaut (seine 252 Tage) und dachte: „Ah, Anleihen sind ein toller Puffer!“ In der Realität der nächsten 21 Tage kam dann aber vielleicht ein Makro-Schock (z.B. Zinsangst), der plötzlich alle Anlageklassen gleichzeitig nach unten riss.
-
Weil das gemischte Portfolio nun Assets enthielt, die sehr empfindlich auf Zinsen reagieren (TLT, VNQ, Gold), entstanden neue, eigene Schwankungen, die das reine Aktien-Portfolio so gar nicht hatte.
Warum sind die Prognose-Fehler an völlig anderen Zeitpunkten?
Ein reines Aktien-Portfolio und ein gemischtes All-Wetter-Portfolio haben eine völlig unterschiedliche ‚DNA‚. Sie reagieren auf komplett andere Krisen-Auslöser:
-
Das reine Aktien-Portfolio crasht (die dunkelblauen Balken tief im Minus), wenn die Unternehmensgewinne enttäuschen, wenn die Arbeitslosigkeit steigt oder wenn ein Tech-Beben (z.B. schwache Halbleiter-Zahlen) durch den Markt geht.
-
Das gemischte Portfolio (mit Gold & Anleihen) reagiert darauf vielleicht völlig gelassen (Gold fängt es ab). Dafür crasht dieses Portfolio in Monaten, in denen z.B. die Inflation überraschend hoch ausfällt oder Notenbank-Chefs Zinserhöhungen andeuten. Anleihen und Gold ‚hassen‘ solche Nachrichten, während Tech-Aktien das vielleicht ignorieren.
-
Das bedeutet: Die ‚Schocks‘ (die Abweichungen zwischen Prognose und Realität) passieren an exakt den Zeitpunkten, an denen die spezifischen Schwachstellen des jeweiligen Portfolios von der Makroökonomie getroffen wurden. Da die Portfolios völlig unterschiedlich aufgebaut sind, sind auch die Schock-Monate völlig andere.
Schaut man sich die 12 simulierten Rebalancing Zeitpunkt an, so ergibt sich folgendes:
GLD(Gold) taucht oft im Portfolio auf. Von Juli 2025 bis November 2025 war Gold in jedem einzelnen Monat mit der maximalen Gewichtung von 35,0 % (dem maximal möglichen Gewicht) vertreten. Der Algorithmus hat erkannt, dass in dieser Phase klassische Aktien stark miteinander schwankten und hat Gold als stabilen Anker genutzt.
- Schauen wir auf den 21. April 2025. Hier springt plötzlich
TLT(US-Staatsanleihen) mit vollen 35,0 % ins Portfolio. Das ist der klassische „Risk-Off“-Trade der Wall Street. Der Optimizer hat in den 252 Tagen davor gesehen, dass Aktien zu riskant wurden, und hat das Kapital in den sicheren Hafen der Anleihen gerettet. Im Juli passiert das Gleiche noch einmal.
RHM.DE(Rheinmetall) ist extrem interessant. Es taucht in 11 von 12 Zyklen auf, wird aber in 10 Fällen starr auf exakt 15,0 % (das absolute Minimum) gedrückt. Warum? Rheinmetall hatte in diesem Zeitraum eine extrem gute Rendite, war dem Minimum-Variance-Optimizer aber viel zu volatil (zu hohes Risiko). Die Leitplanken haben den Algorithmus gezwungen, es zu behalten, haben es aber sicherheitshalber auf dem Minimum gehalten.
BTC-USDtaucht in den 12 Monaten kein einziges Mal auf! Warum? Weil der Algorithmus auf Minimum-Variance (minimales Risiko) optimiert. Bitcoin ist historisch so extrem volatil, dass die Kovarianzmatrix sofort Alarm schlägt. Ein reiner Risiko-Minimierer fasst Krypto fast nie an, es sei denn, man zwingt ihn dazu oder wechselt die Optimierungs-Strategie (z.B. auf die maximale Sharpe-Ratio).
Zusammenfassend: Der D-Wave Algorithmus hats sich als tragfähig erwiesen und kann sehr gut als Werkzeug für die Ausgestaltung der (persönlichen) Anlagestrategie benutzt werden. Der Übergang von der D-Wave Simulation auf die Quanten Hardware ist problemlos möglich, da nur eine andere Annealing Funktion aufgerufen wird. Vielleicht klappt es ja noch mit einem D-Wave Hardware Quantum Annealing.
Anhang 1
Vergleich des Laufzeitverhaltens der QC Systeme
Die nachfolgenden zwei Gleichungen beschreiben in aggregierter Form das Laufzeitverhalten der (Hardware) Systeme QAOA, VQE, D-Wave QA-Hybrid und D-Wave QPU. Weiter unten findet sich jeweils eine genauere Formel pro System/Hardware:

| Beitrag | QAOA | VQE | D-Wave QPU | D-Wave Hybrid |
|---|---|---|---|---|
| Optimizer-Iterationen (N_iter) | 10–1000 | 10–1000 | – | – |
| Auswertungen/Iteration (N_eval/iter) | 1 bis viele | 1 bis viele | – | – |
| Shots | 10²–10⁵ | 10³–10⁶ | – | – |
| Messgruppen | klein–mittel | oft groß | – | – |
| Reads | – | – | 10²–10⁵ | intern |
| Unit-Zeit | Shot-Zeit (tiefeabh.) | Shot-Zeit + Basisrotationen | Anneal+Readout+Reset | time_limit |
| Queue | kann dominieren | kann dominieren | kann dominieren | kann dominieren |
| Compile/Transpile | klein–mittel | klein–mittel | – | – |
| Embedding | – | – | oft relevant | intern |
| I/O | klein–mittel | klein–mittel | klein–mittel | klein–mittel |
| Postprocessing | klein–mittel | klein–mittel | klein–mittel | klein–mittel |
Die Tabelle ist als ‚Zeitbudget-Landkarte‘ zu lesen: Sie zerlegt die Gesamtlaufzeit einer Optimierung in typische Bausteine und zeigt, welche Bausteine bei QAOA, VQE und D-Wave (QPU/Hybrid) überhaupt vorkommen und welche Größenordnung sie typischerweise haben.
Die verwendeten Begriffe und was sie bedeuten:
Optimizer-Iterationen
Anzahl der Schritte, die ein klassischer Optimierer (z.B. COBYLA, Powell, SPSA, Adam) macht, um Parameter zu verbessern.
- Kommt bei QAOA und VQE vor (weil beide variational sind).
- Bei Annealing (QPU/Hybrid) gibt es meist keinen äußeren klassischen Iterationsloop in der Standardnutzung → „–“.
Auswertungen/Iteration
Wie oft pro Iteration die Zielfunktion (z.B. Energie/Cost) neu ausgewertet werden muss.
- Bei gradientenfreien Optimierern oft ≈ 1, bei Line-Search/Gradienten/Parameter-Shift oft größer als 1.
- Bei VQE kann eine ‚Auswertung‘ zusätzlich viele Messungen enthalten (Messgruppen).
Shots
Anzahl der Messwiederholungen eines Quantum-Circuits bei Gate-basierten Methoden (QAOA/VQE).
Mehr Shots → geringeres statistisches Rauschen der gemessenen Erwartungswerte, aber längere Laufzeit.
Messgruppen
VQE (und manchmal auch QAOA, wenn man viele Terme misst) misst die Energie oft als Summe vieler Operatoren. Um nicht jeden Term einzeln zu messen, fasst man kommutierende Terme zusammen, die in derselben Messbasis ausgelesen werden können.
- klein–mittel: wenige Gruppen (z.B. einfache Cost-Funktionen).
- oft groß bei VQE: viele Hamiltonian-Terme → viele Gruppen, selbst nach Gruppierung.
Reads
Anzahl der Samples (Anneals), die ein Annealer liefert.
- Entspricht dem „Sampling-Äquivalent“ zu Shots, aber für D-Wave.
- Bei Hybrid steht „intern“, weil du meist nur ein
time_limitgibst; wie viele Samples intern erzeugt werden, ist solverabhängig.
Unit-Zeit
‚Zeit pro elementarer Wiederholung‘:
- QAOA/VQE: Zeit pro Shot (Circuit ausführen + messen). Bei VQE oft plus zusätzliche Basis-Rotationen vor der Messung.
- D-Wave QPU: Zeit pro Read ≈ Anneal + Readout + Reset.
- D-Wave Hybrid: Zeit wird primär über
time_limitgesteuert, nicht über ein explizites „pro Read“-Budget.
Queue
Wartezeit, bis dein Job auf der Hardware (oder im Cloud-Dienst) tatsächlich läuft.
Kann bei allen Hardware-nahen Varianten (QAOA/VQE auf QPU, D-Wave QPU, D-Wave Hybrid) dominant sein, je nach Auslastung.
Compile/Transpile
Nur Gate-basiert:
- Compile/Transpile bedeutet: Circuit wird an die echte Hardware angepasst (Gate-Set, Kopplungstopologie, Optimierungs-Pässe). Das ist oft „klein–mittel“, kann aber bei großen Circuits oder häufigem Re-Compile relevant werden.
Embedding
Nur D-Wave QPU (und teilweise intern bei Hybrid):
- Embedding ist das Mapping deines logischen Problems (BQM-Graph) auf die physische D-Wave-Hardware-Topologie (Pegasus).
- Kann „oft relevant“ sein, weil es bei dichten Problemen schwer ist und Zeit kostet; außerdem beeinflusst es die Qualität (Chains).
I/O
Upload/Download/Parsing:
- Netzwerk-Overhead, Serialisierung, Job-Handling, Ergebnis-Abholung.
Meist „klein–mittel“, aber bei vielen Jobs/Iteration kann es sich summieren.
Postprocessing
Alles, was nach dem Roh-Ergebnis passiert:
- Bei Gate-basiert: Mittelwertbildung, Gruppensummen, evtl. Error-Mitigation.
- Bei D-Wave QPU: Unembedding, Chain-break-Auflösung, Feasibility-Checks, Ranking/Filterung.
Meist „klein–mittel“, kann aber bei großen Samplesets oder strengen Constraints wachsen.
Zussammenfassung
- QAOA und VQE: Laufzeit wird häufig durch
(Optimizer-Iterationen) × (Auswertungen/Iteration) × (Shots) × (Shot-Zeit)
plus Queue/Transpile/I/O bestimmt. - VQE ist oft teurer als QAOA, weil zusätzlich Messgruppen stark wachsen können.
- D-Wave QPU: Laufzeit wird häufig durch
Embedding + Queue + Reads × (Anneal+Readout+Reset)
geprägt. - D-Wave Hybrid: Das dominierende Stellrad ist meist
time_limit(plus Queue/I/O). Dadurch ist Hybrid „budget-getrieben“ statt „shots-getrieben“.
Im Folgenden die Formeln für die Laufzeit pro QC-Hardware
Die folgenden Laufzeitmodelle berücksichtigen den gesamten Workflow der Algorithmen („End-to-End“), inklusive Kompilierung, Wartezeiten und klassischem Overhead. Dies entspricht der realen Erfahrung bei der Nutzung von Cloud-Quantencomputern.
1. QAOA (Quantum Approximate Optimization Algorithm)
QAOA ist ein iterativer Algorithmus. Ein klassischer Optimierer bestimmt Parameter, der Quantencomputer evaluiert die Kostenfunktion.
Die Formel:

Beschreibung:
Die Gesamtlaufzeit wird dominiert durch die Schleife des Optimierers. Für jeden Iterationsschritt muss der Quantenschaltkreis oft mehrfach ausgeführt werden (z.B. zur Gradientenbestimmung). Bei Cloud-Systemen fällt oft pro Ausführung erneut eine Wartezeit (Queue) an.
Glossar:
 : Zeit für die Transpilierung des Schaltkreises vor dem ersten Lauf.
: Zeit für die Transpilierung des Schaltkreises vor dem ersten Lauf.- : Anzahl der Schritte des klassischen Optimierers bis zur Konvergenz.
- : Anzahl der Funktionsaufrufe pro Optimierungsschritt.
- : Anzahl der Messwiederholungen pro Schaltkreis (shots).
- : Wartezeit in der Cloud-Warteschlange.
 : Zeit für die Transpilierung des Schaltkreises vor dem ersten Lauf.
: Zeit für die Transpilierung des Schaltkreises vor dem ersten Lauf. : Anzahl der Schritte des klassischen Optimierers bis zur Konvergenz.
: Anzahl der Schritte des klassischen Optimierers bis zur Konvergenz. : Anzahl der Funktionsaufrufe pro Optimierungsschritt.
: Anzahl der Funktionsaufrufe pro Optimierungsschritt. : Anzahl der Messwiederholungen pro Schaltkreis (shots).
: Anzahl der Messwiederholungen pro Schaltkreis (shots). : Wartezeit in der Cloud-Warteschlange.
: Wartezeit in der Cloud-Warteschlange.2. VQE (Variational Quantum Eigensolver)
VQE wird oft in der Quantenchemie eingesetzt. Die Herausforderung ist hier das Messen vieler verschiedener Terme (Pauli-Strings).
Die Formel:

Beschreibung:
Da nicht alle Observablen gleichzeitig gemessen werden können, werden sie in kompatible Gruppen k unterteilt. Die Laufzeit summiert sich über diese Gruppen auf. Eine effiziente Gruppierung  ist entscheidend für die Performance.
ist entscheidend für die Performance.
Glossar:
- : Anzahl der Messgruppen (Measurement Groups).
- : Latenzzeit für das Senden (Input/Output) der Daten der jeweiligen Gruppe.
- : Zeit für die klassische Berechnung der Parameter Updates.
 : Anzahl der Messgruppen (Measurement Groups).
: Anzahl der Messgruppen (Measurement Groups). : Latenzzeit für das Senden (Input/Output) der Daten der jeweiligen Gruppe.
: Latenzzeit für das Senden (Input/Output) der Daten der jeweiligen Gruppe. : Zeit für die klassische Berechnung der Parameter Updates.
: Zeit für die klassische Berechnung der Parameter Updates.3. D-Wave QPU (Pure Quantum Annealing)
Beim direkten Zugriff auf den Quantum Annealer (z.B. Advantage System) spielen Embedding und physikalische Annealing-Zyklen die Hauptrolle.
Die Formel:

Beschreibung:
Im Gegensatz zu Gate-Modellen läuft dies sehr deterministisch ab. Vor der Rechnung muss das logische Problem auf die Hardware-Qubits abgebildet werden (Embedding). Danach folgen schnelle, physikalische Annealing-Zyklen.
Glossar:
- : Zeit für das „Minor Embedding“ (Mapping auf Hardware-Topologie).
- : Zeit zum Initialisieren der QPU.
- : Die reine Quanten-Rechenzeit (Standard ~20 µs).
- : Thermalisierungszeit („Abkühlung“) des Chips.
- : Rückübersetzung der physikalischen Qubits in logische Lösungen.
 : Zeit für das „Minor Embedding“ (Mapping auf Hardware-Topologie).
: Zeit für das „Minor Embedding“ (Mapping auf Hardware-Topologie). : Zeit zum Initialisieren der QPU.
: Zeit zum Initialisieren der QPU. : Die reine Quanten-Rechenzeit (Standard ~20 µs).
: Die reine Quanten-Rechenzeit (Standard ~20 µs). : Thermalisierungszeit („Abkühlung“) des Chips.
: Thermalisierungszeit („Abkühlung“) des Chips. : Rückübersetzung der physikalischen Qubits in logische Lösungen.
: Rückübersetzung der physikalischen Qubits in logische Lösungen.4. Hybrid D-Wave (Leap Hybrid Solvers)
Hier übernimmt ein Cloud-Service die Arbeit, zerlegt große Probleme und nutzt QPU sowie CPU im Verbund.
Die Formel:

Beschreibung:
Für den Nutzer ist dies oft eine „Black Box“. Man definiert ein Zeitlimit, und der Solver versucht innerhalb dieser Zeit die beste Lösung zu finden.
Glossar:
- : Das vom Nutzer oder System gesetzte Zeitlimit.
- : Nachbearbeitungszeit durch den klassischen Solver-Teil.
- : Wartezeit bis der komplexe Hybrid-Job startet.
 : Das vom Nutzer oder System gesetzte Zeitlimit.
: Das vom Nutzer oder System gesetzte Zeitlimit. : Nachbearbeitungszeit durch den klassischen Solver-Teil.
: Nachbearbeitungszeit durch den klassischen Solver-Teil.Anhang 2
Der D-Wave QAPO Algorithmus
1. Finanz Daten Aufbereitung
Bevor der Algorithmus optimieren kann, müssen die rohen Aktienkurse in vergleichbare Metriken umgewandelt werden. Das Modell berechnet zunächst die logarithmischen Tagesrenditen und skaliert diese anschließend auf ein handelsübliches Jahr (252 Tage).

Erklärung:  ist die logarithmische Rendite des Assets
ist die logarithmische Rendite des Assets  zum Zeitpunkt
zum Zeitpunkt  , berechnet aus dem Verhältnis des heutigen Kurses
, berechnet aus dem Verhältnis des heutigen Kurses  zum gestrigen Kurs
zum gestrigen Kurs  . Log-Renditen sind symmetrisch und eignen sich mathematisch besser für die Schätzung von Varianzen als einfache prozentuale Renditen.
. Log-Renditen sind symmetrisch und eignen sich mathematisch besser für die Schätzung von Varianzen als einfache prozentuale Renditen.
![\begin{equation<em>} \mu_i = \mathbb{E}[r_i] \cdot 252 \quad \text{und} \quad \Sigma_{ij} = \mathrm{Cov}(r_i, r_j) \cdot 252 \end{equation</em>}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-22d8582377dc536737c71037c368c270_l3.png "Rendered by QuickLaTeX.com")
Erklärung:  ist die erwartete, annualisierte Rendite des Assets . Die Matrix
ist die erwartete, annualisierte Rendite des Assets . Die Matrix  ist die Kovarianzmatrix. Sie beschreibt nicht nur das Risiko (die Varianz) einer einzelnen Anlage, sondern misst auch, wie stark sich zwei verschiedene Assets und
ist die Kovarianzmatrix. Sie beschreibt nicht nur das Risiko (die Varianz) einer einzelnen Anlage, sondern misst auch, wie stark sich zwei verschiedene Assets und  gemeinsam bewegen. Dies ist der mathematische Kern der Diversifikation.
gemeinsam bewegen. Dies ist der mathematische Kern der Diversifikation.
2. Die Quanten-Zielfunktion: Feature Selection
In diesem Schritt entscheidet der Quantencomputer (D-Wave), welche  Assets aus dem gesamten Universum von
Assets aus dem gesamten Universum von  Assets (z.B.
Assets (z.B.  ) in das Portfolio aufgenommen werden. Die Entscheidungsvariable ist binär:
) in das Portfolio aufgenommen werden. Die Entscheidungsvariable ist binär:  .
.

Erklärung: Dies ist die physikalische Energiefunktion  für das klassische Markowitz-Problem. Der erste Term berechnet das Gesamtrisiko des Portfolios, der zweite Term die erwartete Rendite. Der Parameter
für das klassische Markowitz-Problem. Der erste Term berechnet das Gesamtrisiko des Portfolios, der zweite Term die erwartete Rendite. Der Parameter  bestimmt, wie stark die Rendite gegenüber dem Risiko gewichtet wird. Da der Quantencomputer das System auf die niedrigste Energie minimiert, erhält der Rendite-Term ein negatives Vorzeichen.
bestimmt, wie stark die Rendite gegenüber dem Risiko gewichtet wird. Da der Quantencomputer das System auf die niedrigste Energie minimiert, erhält der Rendite-Term ein negatives Vorzeichen.
3. Die Nebenbedingung: Exakt K Assets wählen
Ein QUBO (Quadratic Unconstrained Binary Optimization) versteht von Haus aus keine Nebenbedingungen. Daher muss die Regel „Wähle genau  Assets“ als mathematische Straf-Energie (Penalty) formuliert werden.
Assets“ als mathematische Straf-Energie (Penalty) formuliert werden.

Erklärung: Die Summe über alle  zählt, wie viele Assets vom Solver aktuell ausgewählt wurden. Stimmt diese Anzahl exakt mit überein, wird die Klammer zu Null und es gibt keine Strafe. Weicht die Anzahl ab, wird die Differenz quadriert und mit einem massiven Straf-Faktor
zählt, wie viele Assets vom Solver aktuell ausgewählt wurden. Stimmt diese Anzahl exakt mit überein, wird die Klammer zu Null und es gibt keine Strafe. Weicht die Anzahl ab, wird die Differenz quadriert und mit einem massiven Straf-Faktor  multipliziert. Der Quantencomputer wird diese energetisch extrem ungünstigen Zustände zwingend vermeiden. Das finale Problem, das an die Hardware geschickt wird, ist die Summe beider Gleichungen (
multipliziert. Der Quantencomputer wird diese energetisch extrem ungünstigen Zustände zwingend vermeiden. Das finale Problem, das an die Hardware geschickt wird, ist die Summe beider Gleichungen ( ).
).
4. Die klassische Allokation: Das Minimum-Variance Portfolio
Sobald D-Wave die unkorreliertesten und stärksten Assets selektiert hat, übernimmt ein klassischer Solver (wie SciPy) die Kapitalallokation. Da historische Renditen extrem schwer vorherzusagen sind, fokussiert sich der Solver auf die Minimierung des Risikos (Minimum-Variance-Ansatz).

Erklärung: Gesucht wird der Gewichtsvektor  (z.B. 15% in Gold, 35% in Telekom), der die Gesamtvarianz dieses Sub-Portfolios minimiert.
(z.B. 15% in Gold, 35% in Telekom), der die Gesamtvarianz dieses Sub-Portfolios minimiert.  ist die gefilterte Kovarianzmatrix, die nur noch unsere ausgewählten Gewinner-Assets enthält.
ist die gefilterte Kovarianzmatrix, die nur noch unsere ausgewählten Gewinner-Assets enthält.

Erklärung: Unter den Nebenbedingungen (u.d.N.) müssen alle Gewichte in Summe  (also 100%) ergeben. Zusätzlich darf kein Asset ein Gewicht unter
(also 100%) ergeben. Zusätzlich darf kein Asset ein Gewicht unter  (z.B. 15%) oder über
(z.B. 15%) oder über  (z.B. 35%) erhalten. Diese Leitplanken verhindern, dass der Algorithmus das gesamte Budget in nur ein einziges Asset umschichtet (Vermeidung des Error-Maximization-Problems).
(z.B. 35%) erhalten. Diese Leitplanken verhindern, dass der Algorithmus das gesamte Budget in nur ein einziges Asset umschichtet (Vermeidung des Error-Maximization-Problems).
5. Out-of-Sample Forecasting: Realität & Transaktionskosten
Im Backtest wird das Trainingsfenster (z.B. alle 21 Tage) weitergerollt. Wenn sich das Portfolio ändert, fallen reale Umschichtungskosten an, die exakt berechnet werden müssen.

Erklärung: Der Turnover misst das umgeschlagene Kapital. Die Formel summiert die absoluten Differenzen zwischen dem neuen Ziel-Gewicht  und dem alten Gewicht
und dem alten Gewicht  . Die Division durch 2 korrigiert den Umstand, dass jeder Verkauf automatisch einen Kauf finanziert (das Volumen würde sonst doppelt gezählt).
. Die Division durch 2 korrigiert den Umstand, dass jeder Verkauf automatisch einen Kauf finanziert (das Volumen würde sonst doppelt gezählt).

Erklärung: Die echte Netto-Periodenrendite  errechnet sich aus dem Portfoliowert am Ende des Intervalls
errechnet sich aus dem Portfoliowert am Ende des Intervalls  geteilt durch den Startwert
geteilt durch den Startwert  . Davon werden die Transaktionskosten subtrahiert, welche sich aus dem Turnover multipliziert mit der prozentualen Gebühr
. Davon werden die Transaktionskosten subtrahiert, welche sich aus dem Turnover multipliziert mit der prozentualen Gebühr  (Slippage & Ordergebühren, z.B. 0.25%) ergeben.
(Slippage & Ordergebühren, z.B. 0.25%) ergeben.









