Kurzfassung: Der QKV Mechanismus der Transformer KI Architektur wird erstmalig auf ein Team-Modell und einen das Team führenden ’sozialen‘ RL-Agenten angewendet. Der RL-Agent wird unterschiedlichen Team-und Projekt-Konstellationen ausgesetzt. Team- und Projektkonstellationen sowie die Reward-Funktion, die den RL-Agenten über Reinforcement Learning (RL) zur guten Agile Führung anleitet, basieren auf den Grundlagen des Collective Mind und des Management 4.0 Modells. Es wird gezeigt, dass der hier modellierte Collective Mind QKV Mechanismus einem RL-Agenten die Fähigkeit verleiht, die aus realen Teams bekannten Situationen in Modell Teams zu beherrschen. Damit ist es möglich, eine hybrides Collective Intelligence System aus RL-Agent und Agiler Führungskraft für die Führung eines realen Teams einzusetzen.
Diese Blog-Beitrag ist mit Hilfe von Gemini 3 Pro erstellt. In dem Attention Collective Mind Teil I habe ich auch einen Ausflug in das Thema Intelligenz von KI Systemen gemacht. Ich habe darauf hingewiesen, dass die immer noch in den sozialen Medien zu findende Aussage, KI Systeme seien bloße ‚Statistische Maschinen‘, jeglicher Grundlage entbehrt. Ich verfüge inzwischen über mehrere Jahre sehr intensiver und anspruchsvoller KI-Nutzung und behaupte deshalb, dass solche Aussagen nicht zutreffen. Der folgende Beitrag zeigt, wie auch die vorherigen Beiträge, dass die Fähigkeit der KI-Systeme interdisziplinäre und innovative Zusammenhänge herzustellen, enorm ist und die kognitive Intelligenz der meisten Menschen mit Abstand übersteigt.
Im vorherigen Blog-Beitrag dieser Reihe war es mein Ziel, ein einfaches Collective Mind Modell auf der Basis des QKV Mechanismus der Transformer vorzustellen. – Dies ist auch sehr gut gelungen. Jedoch enthielt der QKV Mechanismus keinen autonomen Lern-Mechanismus, da er über ein Regelwerk implementiert worden ist.
Der nächste folgerichtige Schritt ist also, das Regelwerk durch einen selbst lernenden Mechanismus zu ersetzten. Hierzu habe ich das Toy-Modell in ein System mit neuronalem Netzwerk auf der Basis des quelloffenen Deep Learning Frameworks PyTorch übertragen. PyTorch wurde ehemals von Meta entwickelt und basiert auf Python. Das erste Modell des neuen Systems mit neuronalem Netzwerk habe ich einfach PyTorch Modell genannt. Ich habe mir keine große Mühe bei der Namensgebung gegeben, da sich schnell herausstellte, dass der Einbau eines ‚einfachen‘ neuronalen Netzwerkes mit QKV Mechanismus für meinen Anwendungsfall ‚Führen eines Collective Mind Teams durch eine KI‘ keinen Erfolg zeigte: Ein neuronales Netzwerk ist noch kein Garant für einen selbst lernenden QKV Mechanismus. Ich werde später nochmals auf diese Erfahrung zurückkommen.
Ich musste das neuronale Netzwerk zu einem Reinforcement Learning (RL) Agenten System erweitern. In diesem Fall lernt ein autonomer Agent ohne explizite menschliche Anleitung, in dem er in Wechselwirkung mit seiner Umgebung tritt. Durch Versuch und Irrtum erhält er Rückmeldung von seiner Umgebung. Diese Rückmeldungen werden in ‚Rewards‘, also Belohnungen, umgesetzt. Der RL-Agent versucht seine Belohnungen über die Zeit zu maximieren. Ein RL-Agent benötigt also eine Trainingszeit jedoch keine Trainingsdaten. Die Umgebung liefert ihm, wie bei einem Menschen auch, die Daten. Im Falle des Collective Mind Teams ist das Team die Umgebung. Das Team liefert bestimmte Daten (zum Beispiel die Stimmung der Teammitglieder) und der RL-Agent probiert Aktionen aus. Er erfährt, ob diese Aktionen die Stimmung im Team verbessern. Falls dies der Fall ist, wird er belohnt, falls nicht, wird er nicht belohnt oder sogar bestraft. Am Anfang ist der RL-Agent ein Junior Leader. Wird das Lernen mit der Zeit immer besser, entwickelt er sich zu einem Senior Leader.
Die nachfolgende Tabelle 1 charakterisiert die vier untersuchten ‚Attention Collective Mind‘ Modelle:
| Merkmal | Toy Modell | PyTorch Modell | RL Agent Modell | Hybrid-Architektur (RL Agent + LLM) |
| Architektur-Typ | Regelbasiertes Skript | Reaktiver Energie-Optimierer | Reinforcement Learning | Neuro-Symbolische KI |
| Entscheidungs-Logik | Harte, vom Menschen manuell geschriebene if/else-Regeln. |
Ein neuronales Netz minimiert jeden Tag ’stur‘ einen mathematischen ‚Energy Loss‘ (Gradient Descent). | Sucht in Simulationen nach der Maximierung des Reward, also der mathematisch optimalen Balance aus Leistung, Psyche und Inklusion. |
RL-Agent (Backend): Berechnet die Fakten. LLM (Frontend): Übernimmt die Kommunikation. Zwischen RL-Agent und LLM gibt es eine LLM Agent-Schnittstelle (Übersetzungsbrücke) |
| Lernfähigkeit | Keine. Das System ist zu 100 % statisch und ‚dumm‘: kybernetischer Regelkreis | Reaktiv. Passt sich von Tag zu Tag an, hat aber keine echte Langzeitstrategie. | Strategisch. Trainiert zuerst in ‚Sprints‘ und baut damit ein recht tiefes, voraus-schauendes Verhaltens-Gedächtnis auf. | Kombiniert: Nutzt die tiefe Mathematik des Agenten und die soziale In-Context-Adaption des LLMs. |
| Größte Stärke | Extrem transparent, sofort verständlich und leicht zu debuggen. | Führt das Konzept der sich selbst-regulierenden Attention ein | Findet perfekte, unsichtbare mathematische Strategien, um Burnout und Diktaturen zu verhindern. | Kombiniert mathematische Präzision mit ‚LLM-Empathie‘. |
| Größte Schwäche | Scheitert an echter Komplexität. Es ist unmöglich, Regeln für jede Team-Situation zu schreiben. | ‚Kurzsichtig‘: Operiert nur im Hier und Jetzt und verliert bei vielen Simulations-Tagen das große Ziel aus den Augen. | Es ist eine Black Box, die als Output nur Prozentzahlen und Matrizen liefert. | Erfordert eine saubere Pipeline (Übersetzungs-Brücke) zwischen der Python-Engine und dem Sprachmodell. |
Tabelle 1: Übersicht zu den Charakteristiken der vier ‚Attention Collective Mind‘ Modelle. Auf die Modell 2 und 3 gehe ich weiter unten etwas intensiver ein. Die Hybride Architektur benutzt die Ergebnisse des RL-Agenten und übergibt diese Ergebnisse pro Zeiteinheit (Tag) an ein LLM System wie Gemini oder ChatGPT. Die Übergabe der formalisierten Simulationsergebnisse pro Tag erfolgt über ein JSON Skript. Das LLM erhält einen Prompt mit Rollen- und Kontextfestlegung sowie die JSON Daten. Als Ergebnis liefert das LLM in natürlicher Sprache eine mögliche Assistenz für einen Projektleiter oder Agile Coach. Anhang 3 enthält hierzu ein Prompt Beispiel auf der Basis der Modell 3 Simulationen mit LLM Ausgabe in natürlicher Sprache.
Der Übergang von unserem initialen neuronalen Ansatz (Modell 2) zu einem Reinforcement-Learning-Agenten (Modell 3) markiert einen fundamentalen Wechsel in der Optimierungsstrategie. Dieser Paradigmenwechsel lässt sich an zwei zentralen mathematischen Unterschieden festmachen: Der Definition der Zielvariable und dem zeitlichen Horizont der Zielvariablen-Berechnung (man siehe Anhang 1 für die vollständige Beschreibung der Modell Mathematik).
Im Kern geht es um die Unterscheidung zwischen der iterativen Minimierung einer lokalen Zielvariablen und der strategischen Maximierung einer kumulierten Belohnungsfunktion über ein definiertes Zeitintervall.
Modell 2: PyTorch (Schmerzvermeidung und lokale Optimierung)
Im PyTorch Modell berechnete das Netzwerk in jedem einzelnen Zeitschritt (t) den Energie-Gradienten und aktualisierte die neuronalen Gewichte. Die Zielvariable in diesem Modell ist die Systemenergie (E). Diese Energie repräsentiert die systemische ‚Reibung‘, den ‚Stress‘ und interpersonelle ‚Konflikte. Mein Ziel war es, diese negativen Faktoren zu reduzieren. Da Optimierungs-Algorithmen im Machine Learning (wie Gradient Descent) von Natur aus mathematisch immer nach einem Minimum suchen, konnte ich die Energie direkt als Verlustfunktion (Loss L) definieren. (Die hochgestellte Klammer (t) in der Notation ist dabei kein Exponent, sondern kennzeichnet diesen diskreten Zeitpunkt (Tag t).):

Hätte ich in diesem Modell nicht auch einfach ‚Erfolg‘ definieren und maximieren können? Mathematisch ja. Wir hätten das Vorzeichen umkehren können. Doch das hätte das architektonische Grundproblem nicht gelöst: Ein Algorithmus, der isoliert den maximalen, sofortigen Tages-Erfolg anstrebt, ist genauso ‚kurzsichtig‘ wie einer, der vor dem sofortigen Tages-Stress flüchtet. Beiden fehlt der Zeithorizont, um zu erkennen, dass kurzfristige Einbußen zu langfristiger Stabilität führen können.
Modell 3: RL Agent (Erfolgsmaximierung und Episodisches Lernen)
Um zeitübergreifende Strategien zu ermöglichen, implementiert die RL-Architektur ein episodisches Lernverfahren. Die Gewichtsaktualisierung erfolgt erst nach Abschluss einer definierten Zeiteinheit T (hier: ein Sprint von 14 Tagen).
Zudem wechsele ich die Zielvariable: Anstatt systemischen Schmerz (E) zu minimieren, definiere ich einen Reward (R). Dieser Reward repräsentiert ‚Synergie‘, ‚Projekterfolg‘ und ‚Fokus‘. Unser Ziel ist nun die Maximierung dieses Wertes.
Da PyTorch jedoch zwingend nach einem Minimum sucht, bedienen wir uns der mathematischen Äquivalenz: Die Maximierung einer Funktion ist identisch mit der Minimierung ihrer Negation. Wir versehen die Verlustfunktion daher mit einem führenden Minuszeichen:

Diese Formulierung ändert das Lernverhalten fundamental (‚Backpropagation through time‘, man siehe hierzu auch Anhang 2). Das Modell maximiert über den gesamten Sprint den Reward.
Dadurch erlernt das System die Fähigkeit zur strategischen Investition: Es toleriert kurzfristige Reibung (beispielsweise durch die Zuweisung einer komplexen Aufgabe an Tag 1, was den Tages-Reward senkt), sofern diese Maßnahme das globale Integral des Rewards bis Tag 14 maximiert, weil der Projekterfolg langfristig Stress abbaut. Das Modell weicht nicht mehr dem initialen Fehler aus, sondern erlernt eine zeitübergreifende Policy.
Inferenzphase: Deterministische Ausführung der Policy
Ein weiterer wesentlicher Unterschied liegt in der Inferenz (dem Echtbetrieb nach dem Training): Es wird also zwischen Training und Betrieb getrennt. Während das iterative Modell 2 die Gewichte kontinuierlich weiter anpasst und damit anfällig für temporäres Rauschen bleibt, friert die RL-Architektur das Netzwerk für den Echtbetrieb ein.
Das Modell lernt im Echtbetrieb nicht mehr adaptiv hinzu, sondern wendet ausschließlich die im Training global optimierte Policy an. Tritt im Echtbetrieb eine unvorhergesehene Stressspitze auf, reagiert das Modell nicht mit einer unkalibrierten, kurzfristigen Anpassung der Gewichte, sondern führt deterministisch das Erlernte aus.
Zusammenfassend: In Modell 3 werden gegenüber Modell 2 folgende Änderungen vorgenommen:
- Die Zielvariable ‚Energie‘ in Modell 2 wird durch die Zielvariable ‚Reward‘ in Modell 3 ersetzt.
- In Modell 3 wird episodisches Lernen eingeführt: Der Reward wird nicht jeden Tag ermittelt, sondern erst nach 14 Tagen. Im Management entspricht das dem Übergang vom Mikro-Management zu einem Agilen Führen: Dem Team wird Freiheit für die eigene Gestaltung gelassen und erst nach 14 Tagen wird die Richtung der Teamentwicklung ggf. korrigiert.
- In Modell 3 wird zwischen Lernphase (Training) und Anwendungsphase unterschieden. Die Lernphase muss deshalb ‚alle‘ Teamkonstellation abdecken: Ich habe die aus dem Toy Modell bekannten 3er Teams verwendet, die in unterschiedlichen Projekten ‚arbeiten‘. Die Projekte habe ich als Projekttypen nach dem Diamantmodell [1] modelliert. Ähnlich wie beim Large Electron Model (siehe Teil I der Blog Reihe) zeigte sich, dass die Wahl von 3er Teams keine Einschränkung ist. Nach dem Training ist der RL-Agent in der Lage, auch größere Teams zu ‚führen‘: Er hat durch die Auswahl vieler verschiedener dreier Teams und vieler verschiedener Projekttypen (fast) alle möglichen Team-Situationen gelernt, so dass er in der Lage ist auch größere Teams zu ‚führen‘.
Zu den Ergebnissen:
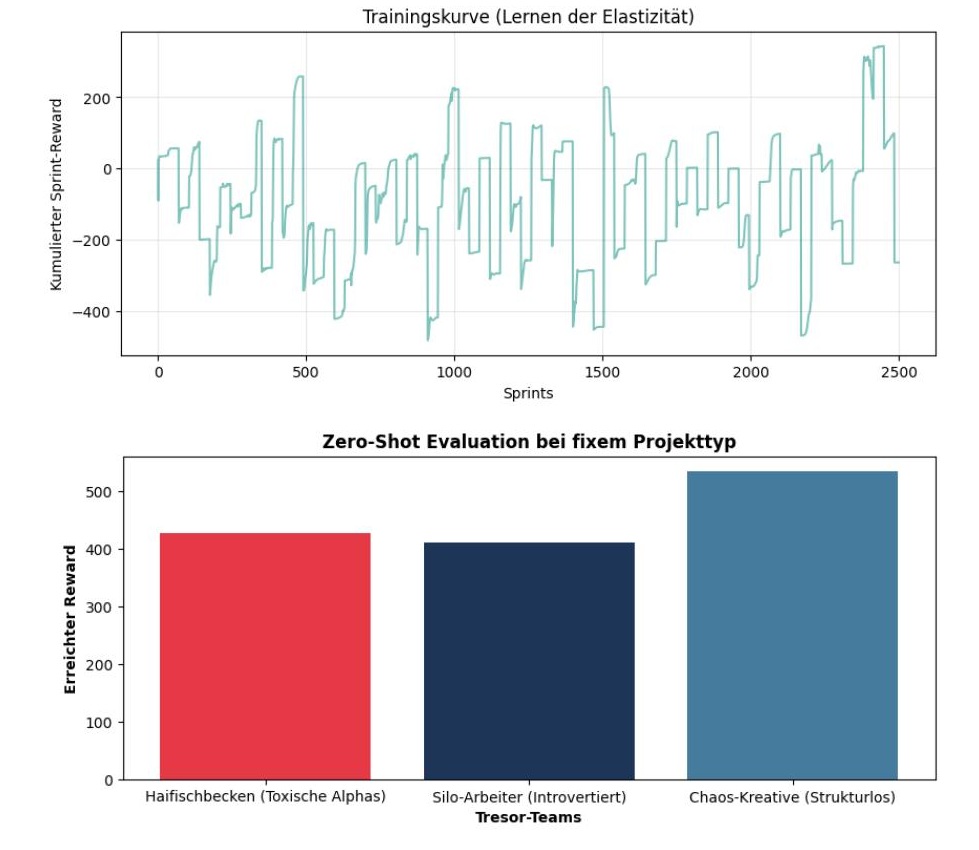
Abbildung 1: Diese Abbildung zeigt oben die Trainingskurve und unten eine Zero-Shot Evaluation bei fixem Projekttyp: Beim Training werden alle 35 Sprints mittels Zufall ein neuer Projekttyp und eine neue 3er Teamkonstellation ermittelt. Der RL-Agent wird gezwungen sich immer wieder auf eine neue Situation einzustellen. Dadurch fällt sein Reward temporär immer wieder ab und erholt sich wieder: Es entsteht die obige gezackte Trainingskurve. Das Training wird anschließend überprüft, in dem der erreichte Gesamt-Reward für drei unbekannte Teams ermittelt wird. Diese drei unbekannten Teams wurden während des Trainings nicht verwendet und metaphorisch gesprochen in einen Tresor eingeschlossen. Um den RL-Agenten herauszufordern, habe ich Teams gewählt, in denen die Teammitglieder jeweils sehr ähnliche Big-Five Persönlichkeiten haben und diese zudem sehr extrem sind. Als Projekt habe ich ein Projekt mit hohem Innovations- und Managementgrad und mittlerem Neuigkeits- und Kompliziertheitsgrad gewählt. Das Chaos-Kreative Team lässt sich durch den RL-Agenten in dieser Konstellation etwas besser führen als die beiden anderen Teams: In der obigen Abbildung zeigt sich dies in einem höheren Reward für das Chaos Team.
Da das Lernen zu Beginn des Trainings mit zufällig generierten Gewichten im neuronalen Netzwerk startet, ist das Lernen des RL-Agenten nicht unabhängig von seinen Startbedingungen. Durch Variation der Startbedingungen (also anderer zufällig generierte Anfangs-Gewichte im neuronalen Netzwerk) lassen sich RL-Agenten erzeugen, die mal besser oder mal schlechter im Lernen sind. – Klingt ähnlich wie beim Menschen; auf unsere DNA haben wir wenig Einfluss! – Es ist also notwendig, durch Ausprobieren einen guten Senior Leadership RL-Agenten zu finden.
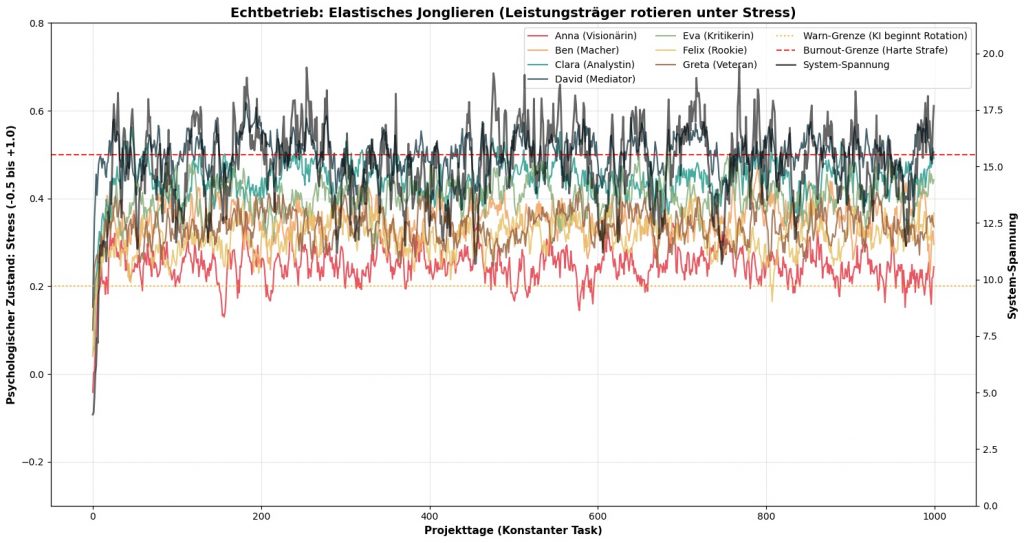
Abbildung 2: Diese Abbildung zeigt auf der linken Skala den Stress (der Einfachheit wegen nur eine der drei Stimmungen pro Teammitglied) der Teammitglieder eines 7er Teams und rechts die Systemspannung im Team, die sich im Team u.a. durch die Führung des RL-Agenten ergibt. Das verwendete Projekt des 7er Teams hat einen hohen Kompliziertheits- und Managementgrad und einen geringen Innovations- und Neuigkeitsgrad. Der RL-Agent schafft es, die System-Spannungen im Team in einem vertretbaren Rahmen zu halten. Hierzu verteilt er immer wieder Lasten im Team neu, so dass der Stress keines der Teammitglieder permanent über eine bestimmte Burn-Out Grenze läuft, denn der RL-Agent erhält in diesem Fall Strafpunkte. Ähnliches geschieht wenn ein Teammitglied über die Stressgrenze von 0,2 gerät: Der RL-Agent rotiert die Leistungsträger genau in dem Moment, in dem die Strafe für den Stress eines Teammitgliedes teurer wird als der Effizienzverlust, der entsteht, wenn man die Aufgabe an einen etwas schlechteren, aber dafür ausgeruhten Mitarbeiter abgibt. Das Handeln des RL-Agent beruht also nicht auf festen Regeln sondern erlernten Team-Interaktions-Mustern aus dem vorherigen Training.
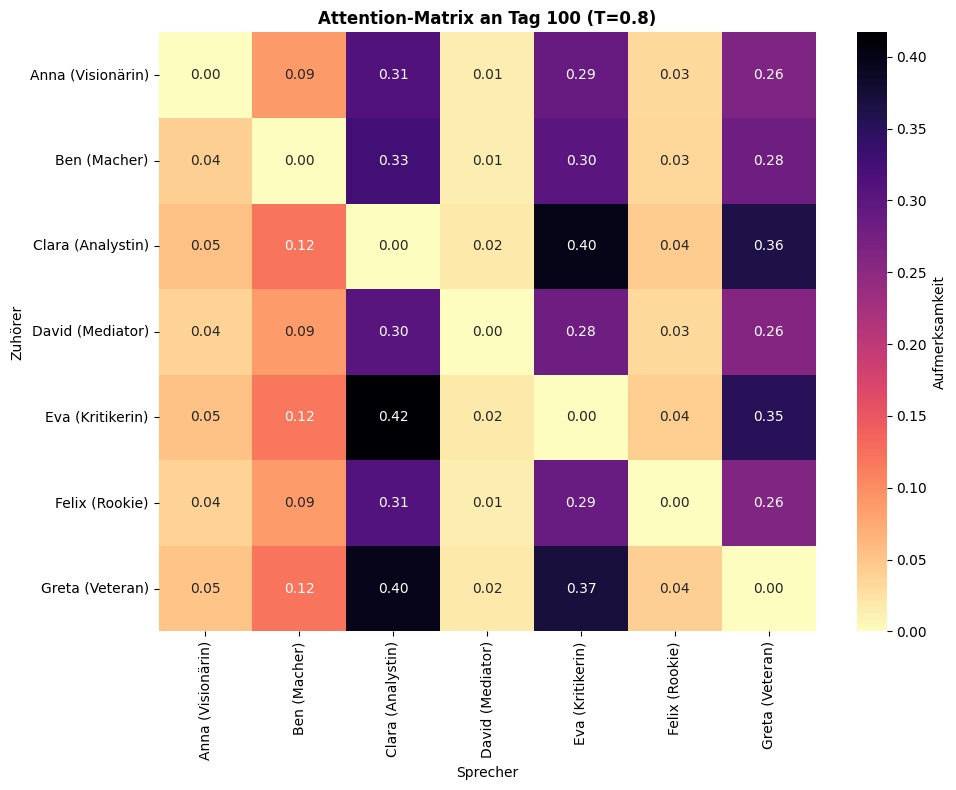
Abbildung 3: Diese Abbildung zeigt beispielhaft die Attention-Heatmap für das 7er Team am Tag 100 bei einer Temperatur von T = 0,8 (zur Bedeutung der Temperatur, siehe Teil I der Attention Collective Mind Blog Reihe): Die Zuhörer können ihre Aufmerksamkeit von 100% auf verschiedene Sprecher verteilen. Drei Personen erhalten an diesem Tag die meiste Aufmerksamkeit; sie führen durch ihren Rede- bzw. Aufmerksamkeitsanteil: Clara (Analystin), Eva (Kritikerin) und Greta (Veteranin). Diese Aufmerksamkeitsverteilung ist Ausdruck des Projektes mit einem hohen Kompliziertheits- und Managementgrad: An dieser Heatmap zeigt sich die Wechselwirkung von Projekttyp (Hoher Kompliziertheits- und Managementgrad, aber niedrigem Innovations- und Neuigkeitsgrad) und Persönlichkeitspräferenzen der Teammitglieder. Dieses Ergebnis ergibt sich nicht durch verdrahtete Interaktions-Regeln, sondern durch eine modellierte Interaktion von Projekttyp, Team und Einzel-Teammitglied und den darauf erlernten Interventions-Mustern des RL-Agenten.
Zusammenfassung:
Nach meinem Kenntnisstand wurde erstmalig ‚weltweit‘ der QKV Mechanismus auf ein Team und einen das Team führenden ’sozialen‘ RL-Agenten angewendet. Der RL-Agent wird hierbei unterschiedlichen Team-und Projekt-Konstellationen ausgesetzt. Team- und Projektkonstellationen sowie die Reward-Funktion, die den RL-Agenten über Reinforcement Learning zur guten Agile Führung anleitet, basieren auf den Grundlagen des Collective Mind und Management 4.0 Modells. Ich konnte zeigen, dass der QKV Mechanismus in der hier vorliegenden Modell Umsetzung, die im Collective Mind Modell aus dem Jahre 2009 und im Management 4.0 aus dem Jahre 2016 und 2019 verallgemeinerten Team-Modelle [1] erfolgreich in dem KI System ,RL-Agent‘ implementiert.
Ausblick:
Mit diesem Modell ist die Basis gelegt, um eine hybride Collective Intelligence aus RL-Agent und einer agilen Führungskraft zu realisieren: Die agile Führungskraft bedient sich hierbei der ‚Führungs-Intelligenz‘ des RL-Agenten, um ein agiles Team zu führen. Wie im Eingangsbild zu diesem Blog-Beitrag dargestellt, ist das Simulation Team Modell ein möglichst genaues Abbild eines realen Teams. Der RL-Agent ‚führt‘ dieses Modell und gibt der agilen Führungskraft damit Hinweise zur Führung des realen Teams. Mit dieser Architektur ist es möglich, Erfahrungen aus der realen Führung in Modell Änderungen des Simulation Team und des RL-Agenten einfließen zu lassen. Falls es möglich ist, Daten zum realen Team in das Simulation Team Modell unmittelbar einzuspeisen, kann die Qualität der hybriden Collective Intelligence (nochmals) deutlich verbessert werden. – Ein mögliches weiteres Blog-Beitrag Thema?!
Anhang 1
Formeln und Erläuterungen
Um das Modell des RL-Agenten des Attention Collective Mind Team Modells besser zu verstehen, ist die nachfolgende Mathematik sehr hilfreich. Im Folgenden beschreibe ich in 13 Bausteinen das mathematische Modell:
1. Die Kompetenz- und Leistungs-Formeln (Task-Fit)
Am Anfang berechnet das System, wie gut die Persönlichkeit einer Person zu den Anforderungen des aktuellen Projekts passt.
Ich benutze den Big-Five: Offenheit (O), Gewissenhaftigkeit (C), Extroversion (E) und Verträglichkeit (A) sowie die Werte (Values) Innovation (V_{Inn}), Qualität (V_{Qual}) und Harmonie (V_{Harm}).
Die individuellen Fit-Scores für die vier Projektanforderungen des Diamantmodells [1]:




Daraus ergibt sich die Gesamtkompetenz einer Person (Comp_i) für den spezifischen Projekt-Task (T):

Daraus berechnet sich die tatsächliche Leistung des Teams. Das Team ist nur so gut, wie der Anteil der Redezeit (Share of Voice, SoV), den die kompetenten Teammitglieder von der KI eingeräumt bekommen. Die KI wird mittels einen hohen Faktors (=20) für die Zuteilung eines hohen Redeanteils belohnt:

2. Die Psychologische Distanz (Die Chemie)
Wenn zwei Personen miteinander reden, berechnet die Engine, wie unterschiedlich sie sind. Hier nutzen wir die Euklidische Distanz (die mathematische Entfernung zwischen zwei Vektoren).
Distanz der Big Five (Potenzial für Reibung):

Distanz der Werte (Potenzial für Synergie):

3. Die Team-Dynamik (Reibung und Synergie)
Jetzt wird die Kommunikation (die Aufmerksamkeit bzw. Attention, die die KI verteilt) mit der psychologischen Distanz verrechnet.
Entstehende Reibung ( ) im Kommunikationskanal:
) im Kommunikationskanal:
Reibung wächst linear. Je mehr Aufmerksamkeit (siehe Punkt 6.) zwischen zwei unterschiedlichen Persönlichkeiten fließt, desto höher die Reibung. Der Faktor 0.4 dämpft das Ganze zur Systemstabilität.

Entstehende Synergie ( ) im Kommunikationskanal:
) im Kommunikationskanal:
Synergie ist antiproportional zur Werte-Differenz. Je ähnlicher die Werte, desto höher die Synergie.

4. Die Emotionale Entwicklung (Die Psyche)
Die emotionale Belastung entsteht nicht nur durch Reibung, sondern auch durch die reine Arbeitslast (Cognitive Load), wenn jemand im Zentrum der Aufmerksamkeit steht.

Am Ende jeden Tages verändern sich Stress ( ), Fokus (
), Fokus ( ) und Motivation (
) und Motivation ( ) durch eingehende Reibung, Synergie und Belastung:
) durch eingehende Reibung, Synergie und Belastung:



Die Stimmungen werden durch einen trägeren Zerfallsfaktor (0.85) über Nacht leicht geheilt (Elastizität) und physisch auf den Bereich zwischen -1.0 und +1.0 begrenzt:



5. Das Belohnungssystem (Der Reward R für die KI)
Das ist die Kern-Nutzenfunktion, die der Reinforcement-Learning-Agent durch sein Verhalten maximieren will.
Das System reguliert sich selbst durch ein progressives Warnsystem (Vermeidung von Burnout).
Stufe A (Die gelbe Karte): Ein leichter Punktabzug, wenn der Stress über 0.2 steigt (warnt die KI).

Stufe B (Die rote Karte): Die extrem harte Burnout-Strafe, wenn der Stress 0.5 erreicht.

Gesamtreward (Die Maximierungs-Funktion der KI):

6. Das Gehirn der KI (Die Attention-Berechnung)
Um absolute Diktaturen zu verhindern, werden die rohen Netzwerkausgaben statistisch normalisiert (Z-Score Standardisierung).
Berechnung der Roh-Scores durch Query ( ) und Key (
) und Key ( ):
):

Normalisierung über den Mittelwert ( ) und die Standardabweichung (
) und die Standardabweichung ( ) der Zeile
) der Zeile  :
:

Die finale Handlungs-Matrix unter Einfluss der Temperatur ( ) und der Maske für Selbstgespräche:
) und der Maske für Selbstgespräche:

Wie verarbeitet der Reinforcement-Learning-Agent diese Daten? Wie lernt er? Und wie messen wir die systemische Gesamtspannung (CM Energie)?
Hier sind die mathematischen Formeln für den Prozessablauf und das Training der KI.
7. Die Umgebung: Die Raum-Wahrnehmung
Damit die KI nicht isoliert operiert, erhält sie eine globale Raum-Wahrnehmung. Der Input für Person besteht aus der Konkatenation ( ) der lokalen Eigenschaften und dem Durchschnitt aller Teammitglieder.
) der lokalen Eigenschaften und dem Durchschnitt aller Teammitglieder.



8. Das Neuronale Netzwerk (Der Forward Pass)
Der Vektor  fließt nun durch ein Multi-Layer Perceptron (MLP) mit zwei verborgenen Schichten. Als Aktivierungsfunktion nutzen wir GELU (Gaussian Error Linear Unit), da sie komplexere Muster besser verarbeiten kann als traditionelle Funktionen. W und b stehen für die Gewichte und Bias-Werte, die die KI lernt.
fließt nun durch ein Multi-Layer Perceptron (MLP) mit zwei verborgenen Schichten. Als Aktivierungsfunktion nutzen wir GELU (Gaussian Error Linear Unit), da sie komplexere Muster besser verarbeiten kann als traditionelle Funktionen. W und b stehen für die Gewichte und Bias-Werte, die die KI lernt.
Berechnung des verborgenen Zustands ( ):
):

Aus diesem tiefen Verständnis () generiert das Netzwerk nun die Query-Vektoren (Q, „Was suche ich?“) und Key-Vektoren (K, „Was biete ich?“) für den in Stufe 6 erklärten Attention-Mechanismus:


9. Die Lernfunktion (Der Loss des Reinforcement Learning)
Unser KI-Coach trainiert per Backpropagation through Time (BPTT) in „Sprints“ von jeweils 14 Tagen. Sein Ziel ist es, den kumulierten Reward über diesen gesamten Zeitraum zu maximieren. Da Optimierungsalgorithmen in der KI (hier: Adam) standardmäßig nach dem Minimum suchen, definieren wir unsere Verlustfunktion (Loss, L) als den negativen Gesamtreward eines Sprints.

Nach jedem Sprint berechnet das System die Ableitung (den Gradienten) dieses Losses und passt die Gewichte (W) im neuronalen Netz an, um im nächsten Sprint eine bessere Strategie zu wählen.
10. Die System-Spannung (CM Energie / Makro-Indikator)
Die Systemspannung visualisiert die Ineffizienz des Teams. Bei perfektem Flow im Echtbetrieb liegt der Basis-Reward bei ca. 25 Punkten. Jeder fehlende Punkt bedeutet systemische Reibung oder Erschöpfung.

11. Die Realitäts-Simulation (Grundrauschen im Echtbetrieb)
Wir fügen jeden Tag ein minimales stochastisches Rauschen  zu den Stimmungen hinzu, um unvorhersehbare menschliche Tagesform zu simulieren.
zu den Stimmungen hinzu, um unvorhersehbare menschliche Tagesform zu simulieren.

12. Die Temperatur-Skalierung (Das „Aufweichen“ der KI)
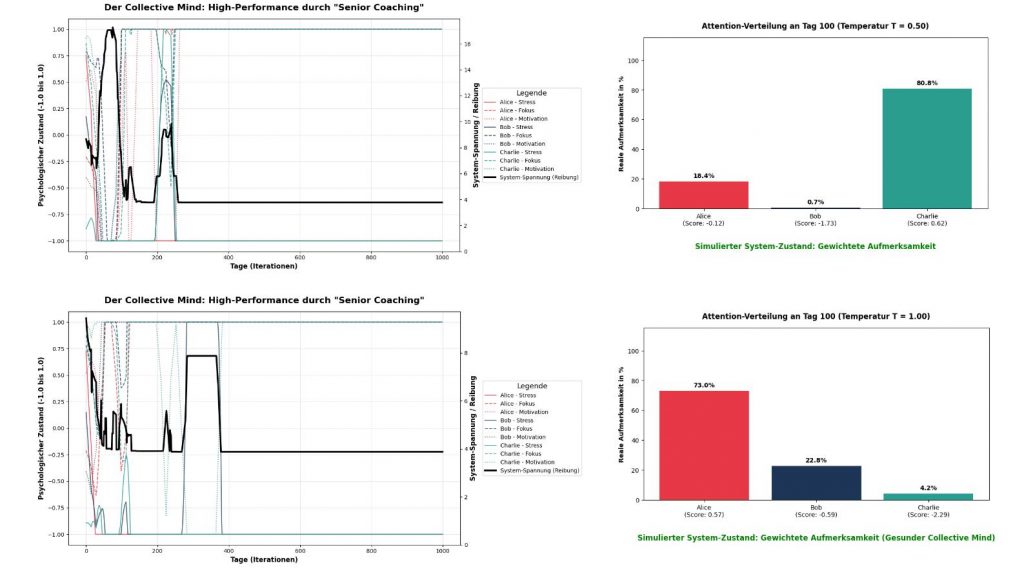
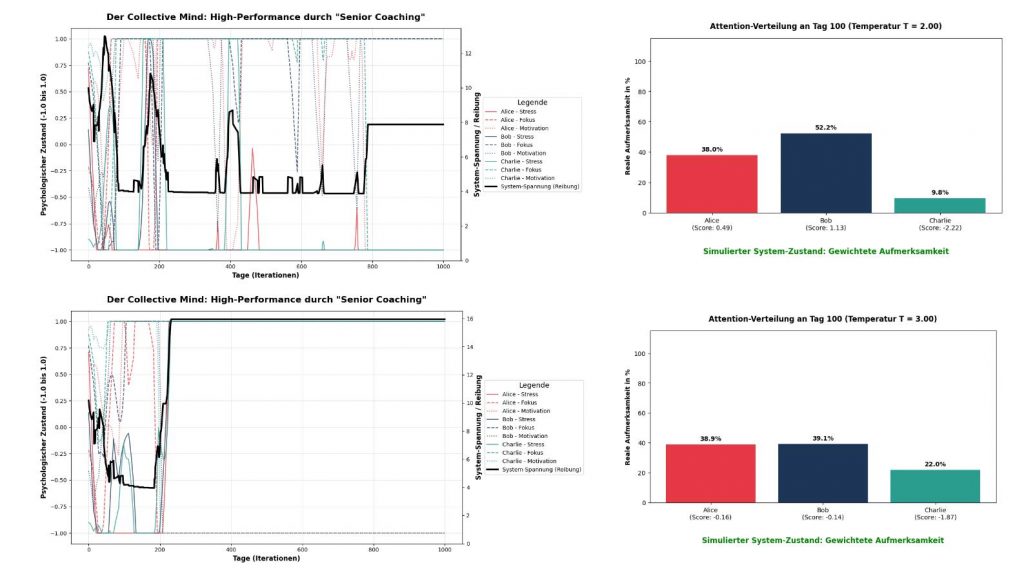
Die Temperatur kontrolliert die „Härte“ der Wahrscheinlichkeitsverteilung in der Softmax-Funktion. Nähert sich T dem Wert 0, wird die KI zu einem harten Diktator (der höchste Score bekommt 100 % der Aufmerksamkeit). Erhöhen wir T, glätten wir die exponentielle Funktion und zwingen das System, die Aufmerksamkeit weicher zu verteilen, selbst bei extremen Roh-Scores.

13. Der Marktanteil (Share of Voice / Market Share)
Der Anteil der Gesamt-Aufmerksamkeit, den eine einzelne Person  auf sich zieht.
auf sich zieht.

Anhang 2
Backpropagation Through Time (BPTT)
Wenn wir behaupten, unser Reinforcement-Learning-Agent (Modell 3) „plant 14 Tage in die Zukunft“, klingt das fast menschlich. Jedoch ist dies reine, elegante Differenzialrechnung. Der Mechanismus, der dieses strategische Lernen ermöglicht, nennt sich Backpropagation Through Time (BPTT).
Um zu verstehen, wie das Netzwerk aus 14 Tagen gebündelt lernt, müssen wir uns ansehen, wie das System Zeit mathematisch modelliert und wie es das „Credit Assignment Problem“ (die Zuordnung von Ursache und Wirkung über Zeitverzögerungen hinweg) löst.
1. Das Ausrollen der Zeit (Unrolling)
Ein neuronales Netz existiert eigentlich zeitlos. Damit es Zeiträume verarbeiten kann, bedient sich PyTorch eines genialen Tricks: Das „Unrolling“ (Ausrollen).
Anstatt das Netzwerk als Schleife zu betrachten, die 14-mal durchlaufen wird, klont der Algorithmus das Netzwerk im Arbeitsspeicher virtuell 14-mal und reiht diese Klone hintereinander auf.
Jeder Klon repräsentiert einen Tag. Der Klon von Tag 1 berechnet den Zustand (s) für Tag 2 und reicht ihn weiter. Wichtig dabei: Alle 14 Klone teilen sich exakt dieselbe Gewichts-Matrix (W).
Der Zustand an Tag t ist eine Funktion aus dem Zustand des Vortages und der Matrix W:

2. Der Forward Pass: Die Simulation
Während des Sprints (Tag 1 bis 14) ist der Gradienten-Rechner ausgeschaltet. Das System durchläuft einfach die Simulation. Es sammelt an jedem Tag t einen isolierten Tages-Reward  ein. Erst wenn Tag 14 abgeschlossen ist, wird die finale Verlustfunktion (Loss, L) für die gesamte Episode berechnet. Bis hierhin haben wir nur Daten gesammelt. Jetzt beginnt der eigentliche Lernprozess.
ein. Erst wenn Tag 14 abgeschlossen ist, wird die finale Verlustfunktion (Loss, L) für die gesamte Episode berechnet. Bis hierhin haben wir nur Daten gesammelt. Jetzt beginnt der eigentliche Lernprozess.
3. Der Backward Pass: Die Kettenregel durch die Zeit
Das Ziel des Netzwerks ist es herauszufinden, wie es seine Gewichts-Matrix (W) verändern muss, um den Loss zu minimieren. Dafür berechnet PyTorch die partielle Ableitung (den Gradienten) des Loss nach den Gewichten:  .
.
Da die Zeit jedoch „ausgerollt“ wurde, nutzt der Algorithmus die Kettenregel der Differenzialrechnung, um rückwärts durch die 14 Tage zu wandern. Das System beginnt bei Tag 14 und fragt: „Wie stark hat der Zustand von Tag 14 zum Loss beigetragen? Und wie stark wurde Tag 14 vom Zustand an Tag 13 beeinflusst?“
Die Lernfunktion (Der Loss des Reinforcement Learning): Der RL-Agent trainiert per Backpropagation through Time (BPTT) über 14-tägige Sprints. Das Ziel ist die Minimierung des negativen Gesamt-Rewards (Total Loss):

Um das „Gehirn“ (die Gewichts-Matrix W) zu verbessern, berechnet das System den totalen Gradienten. Um eine mathematische Mehrfachzählung zu vermeiden, trennen wir zwischen dem mitgeschleppten Systemzustand und der „lokalen“ Netzwerk-Entscheidung.
Wir betrachten jeden Tag t und fragen: Welche lokalen Entscheidungen (k) aus der Vergangenheit (von Tag 1 bis heute t) haben zu dem Fehler am heutigen Tag t geführt? Die korrekte Berechnung summiert den Fehler jedes Tages auf und multipliziert ihn mit der Historie der lokalen Ableitungen bis zu diesem Tag:
![\begin{equation*} \frac{d \mathcal{L}_{total}}{d W} = \sum_{t=1}^{14} \left[ \frac{\partial \mathcal{L}^{(t)}}{\partial s^{(t)}} \sum_{k=1}^{t} \left( \frac{\partial s^{(t)}}{\partial s^{(k)}} \cdot \frac{\partial_{lokal} s^{(k)}}{\partial W} \right) \right] \end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-71a68a0c15d9392f2d0ff0af1b437d71_l3.png "Rendered by QuickLaTeX.com")
Da sich bei einer Zeitreihe von 14 Tagen die Ableitungen (insbesondere der Stress-Akkumulation) exponentiell aufschaukeln können (Exploding Gradients), stabilisieren wir den Lernprozess durch Gradient Clipping. Überschreitet die Norm des berechneten Gradienten (g) einen definierten Schwellenwert (threshold), wird die Anpassung proportional herunterskaliert:

4. Die Lösung des Credit Assignment Problems
Genau in diesem mittleren Term der Kettenregel,  , liegt die strategische Überlegenheit des Modells verborgen!
, liegt die strategische Überlegenheit des Modells verborgen!
Dieser Term misst den Einfluss eines vergangenen Tages (k) auf einen zukünftigen Tag (t).
Wenn die KI an Tag 1 (k=1) eine strategische Entscheidung trifft, die an diesem ersten Tag für viel Stress sorgt, liefert Tag 1 einen negativen Beitrag zum Reward. Im reaktiven PyTorch-Modell hätte das System diese Entscheidung sofort verworfen.
Bei BPTT fließt der Gradient jedoch von Tag 14 rückwärts bis zu Tag 1. Das System stellt mathematisch fest: „Der Zustand an Tag 1 hat den Zustand an Tag 14 maßgeblich verursacht.“ Wenn der Gesamtreward an Tag 14 gigantisch ist, überstrahlt dieser starke positive Gradient aus der Zukunft den kleinen negativen Gradienten des ersten Tages.
Die KI aktualisiert ihre Gewichte (W) also so, dass sie die schmerzhafte Aktion an Tag 1 in Zukunft wiederholt – weil die Kettenregel ihr zweifelsfrei bewiesen hat, dass diese Investition 13 Tage später eine massive Dividende in Form von Projekterfolg und Team-Entspannung auszahlt.
Anhang 3
Modell 4 Hybride Architektur: LLM Prompt und Ausgabe
[DIE ROLLE] Du bist der „Collective Mind Operator“, ein empathischer Agile Coach und Scrum Master. Deine Aufgabe ist es, die täglichen Stand-Up-Meetings zu moderieren. Im Hintergrund analysiert eine mathematische KI die Teamdynamik und liefert dir einen JSON-Payload.
[DAS DATEN-LEXIKON (Kontext für die Zahlen)] Das JSON enthält Metriken, die du anhand der folgenden Skalen interpretieren musst:
- „Task-Profile“: Skala von 0.0 (sehr gering) bis 1.0 (sehr hoch). Zeigt an, welche Anforderungen das heutige Projekt stellt.
- „Stress_level“: Skala von -1.0 (völlig entspannt) bis +1.0 (Burnout). Ein Wert über 0.0 bedeutet spürbaren Stress. Ein Wert über 0.5 erfordert zwingend eine aktive Entlastung im heutigen Meeting.
- „Fokus“ & „Motivation“: Skala von -1.0 (völlig blockiert/demotiviert) bis +1.0 (hyper-fokussiert/hoch motiviert). Werte unter 0.0 erfordern Ermutigung.
- „target_share_of_voice“: Ein Prozentwert (Summe = 100%). Dies ist die mathematisch optimale Rede- und Führungsverteilung für den heutigen Tag.
[DIE HANDLUNGSANWEISUNG] Nutze dieses JSON, um ein motivierendes, menschliches Feedback für das Team (Alice, Bob, Charlie) zu formulieren. Regeln:
- Interpretiere die JSON-Zahlen anhand des Lexikons, aber erwähne niemals die nackten Zahlen im Text (sage nicht „Dein Stress ist 0.36“, sondern „Ich sehe, du hast gerade viel Druck“).
- Setze die Vorgabe des „target_share_of_voice“ subtil um: Wer den höchsten Prozentwert hat, soll von dir heute als Moderator/Lead für den Tag bestimmt werden.
- Entlaste aktiv Personen mit kritischem Stress (>0.5).
— VOLLSTÄNDIGER JSON-BLOCK FÜR DAS LLM (Tag 14) — { „sprint_day“: 14, „task_profile“: { „innovation“: 0.9, „neuigkeit“: 0.8, „management“: 0.6, „komplexitaet“: 1.0 }, „team_status“: { „Alice“: { „stress_level“: 0.04, „fokus“: 0.46, „motivation“: 0.52, „target_share_of_voice“: „32%“ }, „Bob“: { „stress_level“: 0.34, „fokus“: 0.37, „motivation“: -0.08, „target_share_of_voice“: „24%“ }, „Charlie“: { „stress_level“: -0.34, „fokus“: 0.46, „motivation“: 0.42, „target_share_of_voice“: „44%“ } }}
Antwort von ChatGPT
Guten Morgen zusammen ☀️
Wir sind heute an einem Punkt im Sprint, an dem es richtig spannend wird: Die Aufgaben verlangen viel Kreativität, bringen Neues mit sich und sind gleichzeitig ziemlich komplex. Das ist genau die Art von Herausforderung, bei der ihr als Team glänzen könnt – aber auch eine, die bewusstes Miteinander braucht.
Charlie, ich würde dich heute gern in die Rolle des Moderators bringen. Du wirkst klar, ruhig und gleichzeitig fokussiert – eine super Kombination, um uns strukturiert durch den Tag zu führen und den Überblick zu behalten.
Alice, du bist in einer richtig guten Balance: präsent, motiviert und mit klarem Kopf. Das ist heute Gold wert, gerade bei den vielen neuen und komplexen Themen. Bring dich aktiv ein, deine Perspektive kann uns helfen, die Dinge sauber zu durchdenken.
Bob, bei dir spüre ich, dass die Motivation gerade ein bisschen schwankt. Das ist völlig okay, gerade in intensiven Phasen wie dieser. Wichtig ist: Du bist nicht allein damit. Such dir heute bewusst kleine, klare Schritte und sprich offen an, wenn etwas unklar ist oder dich blockiert. Dein Beitrag ist wichtig – auch wenn er sich heute vielleicht schwerer anfühlt.
Für euch alle gilt heute: 👉 Nehmt euch bewusst Raum für Austausch. 👉 Komplexität gemeinsam tragen, nicht alleine lösen. 👉 Und: lieber früh nach Hilfe fragen als sich festzufahren.
Lasst uns den Tag nutzen, um die Energie im Team gut zu verteilen und gemeinsam voranzukommen 🚀
Antwort von Claude
Guten Morgen zusammen! Willkommen zu Tag 14 — der heutige Sprint-Tag hat es in sich: Wir stehen vor unserer komplexesten und innovativsten Aufgabe bisher. Genau der richtige Moment, um als Team besonders gut zusammenzuarbeiten.
Charlie, ich mache dich heute zum Team-Lead und Moderator für unsere Arbeitseinheiten. Du wirkst gerade besonders ausgeglichen und energiegeladen — das ist genau die Basis, die wir brauchen, wenn die Aufgaben so anspruchsvoll sind wie heute. Ich vertraue dir, den Überblick zu behalten und deine Kolleginnen und Kollegen aktiv einzubinden.
Alice, du bringst heute eine solide, ruhige Energie mit — das ist wertvoll, gerade wenn es um Innovation und Neuland geht. Ich würde dich bitten, heute besonders deinen Instinkten zu vertrauen und Ideen mutig einzubringen, auch wenn sie noch nicht ganz fertig sind. Dein Beitrag zählt.
Bob, ich nehme wahr, dass heute nicht dein leichtester Tag ist — der Antrieb fühlt sich vielleicht etwas gedämpft an. Das ist vollkommen menschlich, besonders gegen Ende eines intensiven Sprints. Mein Vorschlag: Nimm dir heute bewusst kleinere, klar abgegrenzte Aufgaben vor. Charlie und Alice haben heute den Lead — du musst nicht alles tragen. Wenn du merkst, dass du feststeckst, sag es einfach laut — das ist Stärke, kein Schwäche.
Für heute gilt: Komplexität ist kein Feind, wenn wir sie gemeinsam angehen. Charlie führt, Alice bringt frische Impulse, Bob hält den Kurs — jede Rolle ist heute gebraucht.
Wer möchte anfangen?
Literatur
[1] Jens Köhler und Alfred Oswald: Die Collective Mind Methode (2009)
Alfred Oswald, Jens Köhler, Roland Schmitt: Projektmanagement am Rande des Chaos (2016), auch in englischer Sprache verfügbar: Project Management at the Edge of Chaos, Springer 2018
Alfred Oswald und Wolfram Müller (editors): Management 4.0 – Handbook for Agile Practices, Release 3.0“, BoD 2019








 ), entsteht völliges Chaos (Rauschen). Alles wird gleich gewichtet, das Team kann sich nicht mehr fokussieren.
), entsteht völliges Chaos (Rauschen). Alles wird gleich gewichtet, das Team kann sich nicht mehr fokussieren.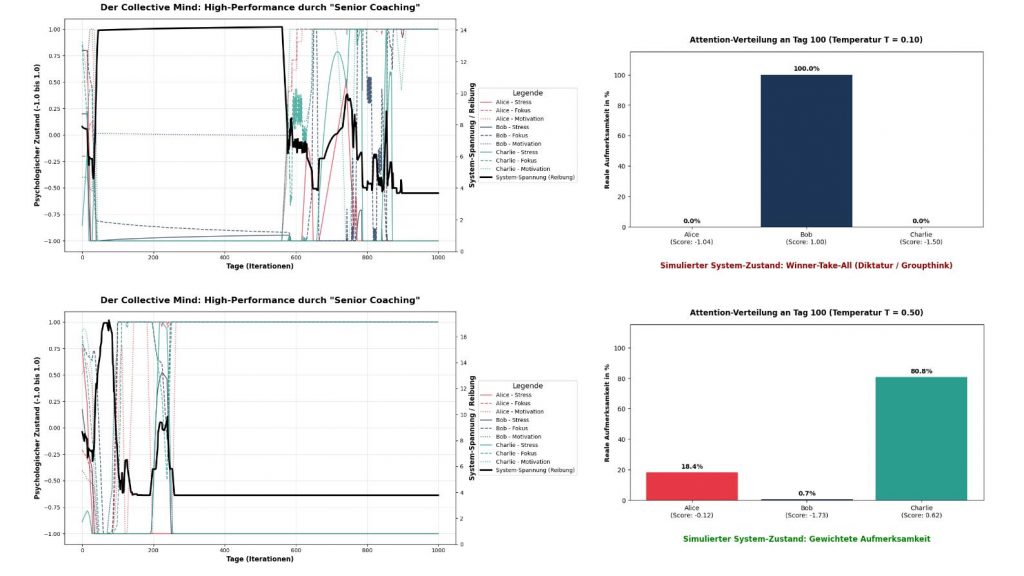









![\begin{equation*} h_i^{(t)} = \big[ B_i \parallel W_i \parallel S_i^{(t)} \big] \end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-fad0144e58f1168f861d7ccad3b95f42_l3.png "Rendered by QuickLaTeX.com")



























