Kurzfassung: In diesem Blog-Beitrag wird der Attention Collective Mind Mechanismus auf eine reale Gruppenkommunikation angewendet. Es wird gezeigt, dass ein durch Reinforcement Learning trainierter RL-Agent einen TV-Moderator aktiv in einem hybriden Collective Intelligence Setting bei der Moderation einer TV-Sendung unterstützen kann. Ein dem Attention Modell ähnlicher Mechanismus wird für die Vermessung des Disruptiongrads von Redebeiträgen angewendet. Damit ist es möglich, die kreative Spannung in einer Kommunikation zu vermessen und deren Potential für die Ausbildung eines Collective Mind zu bewerten.
Dieser Bog-Beitrag ist mit Gemini Pro erstellt.
In den vorherigen beiden Blog-Beiträgen dieser Reihe habe ich einen Attention Mechanismus für die KI-Assistenz von soziale Systemen entwickelt. Ich konnte zeigen, dass ein Reinforcement Learning KI-Agent (RL-Agent) in der Lage ist, eine Projekt-Führungskraft bei der Führung seines Teams zu unterstützen: Der RL-Agent unterstützt die Führungskraft durch die Anzeige des individuellen Stresslevels und des Gruppen-Stresslevels und macht Vorschläge zur Teilnehmereinbindung um die Stresslevel zu senken.
In diesem Blog-Beitrag verwende ich den RL-Agenten, um eine reale Gruppe zu führen: Da es sehr schwierig ist, auf Daten eines realen Teams zuzugreifen, verwende ich die Kommunikation der Gruppe der Markus Lanz TV-Sendung vom 30.04.2024 [1]. Für diese TV-Sendung habe ich schon am 27.Juni 2024 eine Collective Mind Analyse im Blog-Beitrag ‚AI & M 4.0: Markus Lanz vom 30.04.2024…‘ veröffentlicht.
Die transkribierten Kommunikationsdaten zu dieser Sendung liegen vor, so dass es recht einfach ist, auf dieser Basis eine Attention Collective Mind Analyse durchzuführen. Der Ablauf ist wie folgt:
Schritt 1: Die transkribierten Daten werden einer LLM KI übergeben, in dem vorliegenden Fall, Gemini Pro. Gemini Pro erhält die Aufgabe, die Big-Five Persönlichkeiten und die Werte-Ausprägung zu drei Werten V1, V2 und V3 der Teilnehmer der TV-Sendung einzuschätzen:
[V1] Wahrheit & Logik (Sachlicher Erkenntnisgewinn)
[V2] Identität & Loyalität (Verteidigung der eigenen Ingroup)
[V3] Freiheit & Aufklärung (Tabubruch, liberale Werte)
Diese Werte wurden gewählt, weil es in der TV-Sendung um das Rollenverständnis der Muslime in Deutschland geht.
Die Big-Five Ergebnisse und die Werten V1 bis V3 werden pro Diskussionsteilnehmer aus der Gesamtheit der jeweiligen Redebeiträge ermittelt. Die mittels Gemini Pro erhaltenen Big-Five Werte weichen teilweise recht stark von den ChatGPT Big-Five Analyse aus dem Jahre 2024 ab. Die ChatGPT Big-Five Werte entsprechen sehr genau meinen persönlichen Einschätzungen. Ich habe überprüft inwieweit dieser Unterschied das Ergebnis (siehe weiter unten) beeinflusst: Die Big-Five Werte beeinflussen deutlich die Höhe der Stresspegel (Skala unten 0.1 bis 0.2), jedoch kaum deren Verlauf.
Schritt 2: Big-Five und die Werte werden als statische Größen im Persönlichkeitsvektor der Gruppenteilnehmer eingetragen. Zusätzlich ist es nötig, im Persönlichkeitsvektor den emotionalen Zustand der Gesprächsteilnehmer zu erfassen. Mit Gemini Pro wird die sogenannte Valenz (positiv, neutral, negativ) und die damit verbundene Stimmung (Arousal) pro Redebeitrag erfasst. Diese Werte mit der Information auf welchen anderen Teilnehmer bzw. Redebeitrag ein Teilnehmer reagiert wird, werden in eine Tabelle eingetragen.
Schritt 3: Mit Hilfe eines Transformer-Modells aus der Huggingface Bibliothek wird eine Textanalyse vorgenommen. Diese Analyse bettet die ungefähr 100 Redebeiträge in einen hochdimensionalen Vektorraum. Damit ist möglich, Textähnlichkeiten der Redebeiträge über Vektor-Ähnlichkeit zu vermessen. In Anlehnung an einen Artikel zur Vermessung des Disruptioncharakters von wissenschaftlichen Veröffentlichungen [2] habe ich einen Disruption-Score (D-Score) für Redebeiträge eingeführt: Dieser D-Score misst inwieweit sich nachfolgende Redebeiträge (nur noch) auf einen vorhergehenden Redebeitrag beziehen (für die verwendete Mathematik verweise ich auf den Anhang).
Schritt 4: Der bisherige RL-Agent wird getestet, ob er in der Lage ist, den Moderator aktiv und sinnvoll zu unterstützen. Die Tests ergeben, dass es notwendig ist, das RL-Agenten Modell für die Moderator-Situation zu erweitern: Der Redeanteil der Gesprächsteilnehmer wird durch eine Größe ‚Fatique‘ (Ermüdung) begrenzt. – Jeder Redebeitrag führt zu einer ‚Ermüdung‘. Indirekt wird damit auch die Ermüdung der Zuhörer bewertet.
Außerdem wird das Modell für den individuellen Stresspegel und den Stresspegel der gesamten Gruppe angepasst. – Für die entsprechende Mathematik verweise ich auf den Anhang. Der Anhang enthält nur die gegenüber dem vorherigen Blog-Beitrag geänderte Mathematik. – Die erfolgreiche Modellierung bedeutet in diesem Fall, dass die KI dem Moderator richtige Hinweise zur aktiven Steuerung des individuellen und gruppendynamischen Stresspegels gibt, in dem der RL-Agenten korrekte Empfehlungen zur Einbindungen bestimmter Gesprächsteilnehmer gibt: Der RL-Agenten entlastet den Moderator mental und gestaltet den Moderationsablauf mit.
Die erfolgreiche Modell-Ausgestaltung des RL-Agent hat den Nebeneffekt, dass die entscheidenden Modellgrößen selektiert werden und die wichtigen Mechanismen der Führung, hier der Moderation, abgebildet werden: Die ‚Beliebigkeit‘, was gute Führung ist, wird durch überprüfbare Modellgrößen ersetzt!
Schritt 5: Ergebnisse
Abbildung 1 zeigt den Stresslevel der TV-Diskussionsteilnehmer und den Disruptiongrad des jeweiligen Redebeitrages (Turn).
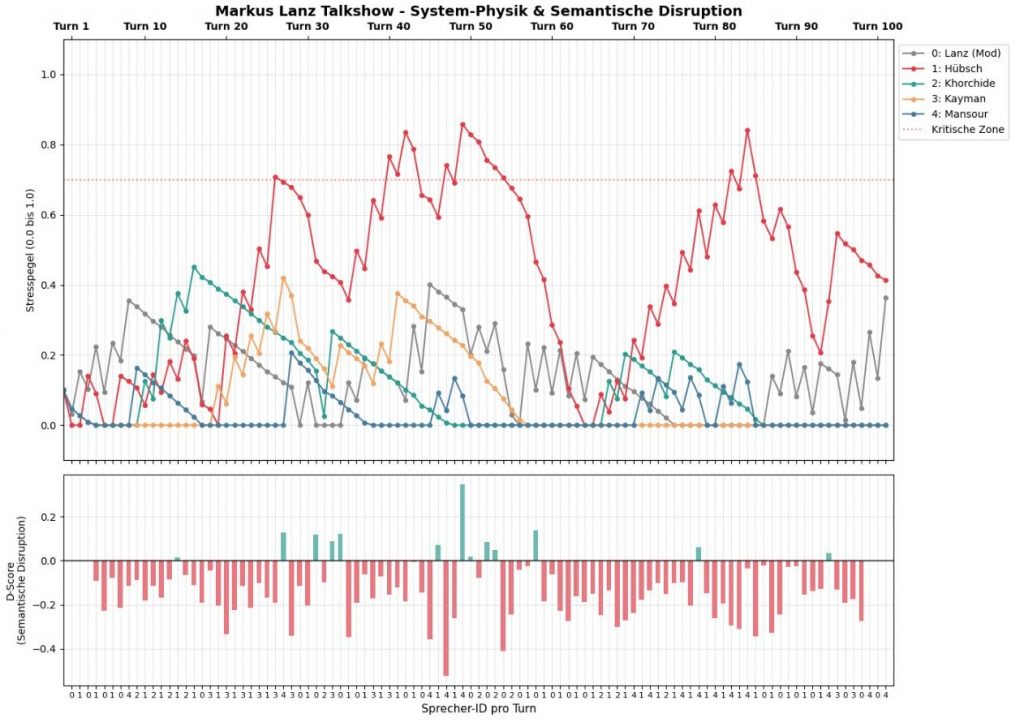
Abbildung 1: Diese Abbildung zeigt im oberen Teil den Stresspegel der fünf Teilnehmer aufgetragen über den Redebeiträgen (Turns). Im unteren Teil der Abbildung ist der D-Score (Disruptiongrad) des Turns enthalten. Am oberen Rand der Abbildung ist die Turn-Nr. als X-Achse verwendet, am unteren Rand wird die Sprecher-ID pro Turn als X-Achse angezeigt. Der Verlauf der Sprecher-ID stellt eine Signatur der Kommunikation dar: Sieht man vom Moderator (Lanz) ab, so zeigt der Sprecher 4 ( Mansour) den höchsten Anteil an Disruption. Der Sprecher 2 (Khorchide) wirkt als starker Konsolidierer. Sprecher 2 (Hübsch) wirkt fast immer als Antagonist, bringt aber kaum Disruption in die Debatte. Sprecher 3 (Kaymann) wirkt in der ersten Hälfte des TV-Gespräches konsolidieren, und hat bis auf eine kleine Disruption im zweiten Teil keine großen Einfluss auf die Diskussion. Berücksichtigt man, dass Disruption und Konsolidierung Wegbereiter eines Collective Mind sind, so tragen Mansour und Korchide die Diskussion, auch wenn der Redeanteil von Mansour relativ klein ist. Dies entspricht den Sprechern 4 und 5 der Analyse vom Juni 2024. Die aktuelle Analyse hilft die vergangene Analyse der nahe beieinanderliegenden Collective Mind Beiträge besser zu unterscheiden.

Abbildung 2: Diese Abbildung zeigt einen Ergebnis-Auszug der zusätzlichen Informationen pro Turn. Hier für die Turns 49 bis 51. Ich habe diesen Auszug beispielhaft gewählt, da hier der größte D-Score vorliegt.
Im folgenden gebe ich eine detaillierte Aufschlüsselung dieses Ergebnis-Auszugs. Diese Zeilen zeigen sehr gut, wie ein kommunikativer ‚Game Changer‘ mathematisch aussieht.
Jeder Block repräsentiert einen Redebeitrag und ist in drei Ebenen unterteilt:
1. 🗣️ REALITÄT (Die Datenbasis)
Das ist die Eingabeebene. Das System registriert die Turn-Nummer ([49]), wer spricht (Mansour), an wen die Aussage gerichtet ist (zu Hübsch) und den Start des tatsächlichen Transkript-Textes.
2. 🧠 Die analytische Ebene (Emotion & Semantik)
Diese Ebene zeigt Parameter des gesprochenen Wortes:
-
Valenz: Misst die emotionale Schärfe von -1.0 (feindselig/Kritik) bis +1.0 (zustimmend/Lob).
-
D-Score: Der Disruptions-Wert. Er misst durch Vektorgeometrie, ob der Satz das inhaltliche Thema der Diskussion radikal verändert (positiver Wert) oder ob alte Argumente lediglich wiederholt werden (negativer Wert).
3. 🤖 KI-CO-PILOT (Die Systemsteuerung)
Dies ist das Steuerzentrum der Simulation:
-
Spg (Systemspannung): Die aufsummierte kognitive und emotionale Belastung (Stress) aller Personen im Raum. Über 2.0 wird es kritisch.
-
Empfehlung: Das neuronale Netz, der RL-Agent, berechnet im Hintergrund, wer als Nächstes sprechen sollte, um den inhaltlichen Ertrag zu maximieren und das System stabil zu halten.
-
System-Notizen: Wenn bestimmte Schwellenwerte gerissen werden, gibt das System Warnungen oder Erfolgsmeldungen aus (z. B.
💡 DISRUPTION ERFOLGREICH!).
Die Analyse: Was passiert in diesen drei Turns?
Dieser Auszug (Turns 49 bis 51) ist ein sehr gutes Beispiel für eine gelungene inhaltliche Intervention:
Turn 49: Der radikale Pivot von Mansour
Ahmad Mansour wehrt sich gegen eine Unterbrechung von Frau Hübsch. Die Valenz ist mit -0.50 stark negativ – es ist ein klarer verbaler Konflikt. Doch Mansour schlägt nicht einfach inhaltlich zurück, sondern lenkt das Thema auf eine völlig neue Ebene. Der NLP-Algorithmus schlägt massiv aus: Ein D-Score von +0.347 ist extrem hoch. Die KI erkennt sofort, dass der semantische Vektor der Diskussion gerade stark geändert wurde und meldet: „DISRUPTION ERFOLGREICH! Thema wurde neu gesetzt.“ Die Systemspannung (Spg) liegt hier bei leicht erhöhten 1.11. Die KI empfiehlt, das Wort an Prof. Khorchide (den harmonischsten Charakter) zu übergeben.
Turn 50: Die kühlende Moderation
Markus Lanz ergreift das Wort. Er erkennt den Themenwechsel („guten Übergang geliefert“) und fungiert als Moderator. Seine Valenz ist exakt 0.00 – völlig neutral und sachlich. Diese emotionale Kühle wirkt sofort: Die Systemspannung fällt schlagartig von 1.11 auf 0.85. Der D-Score ist mit +0.018 fast bei Null, was bedeutet: Lanz bricht Mansours neues Thema nicht ab, sondern lässt es zu. Die KI fordert weiterhin: Gebt das Wort an Khorchide!
Turn 51: Die inhaltliche Konsolidierung
Genau das passiert in der Realität: Prof. Khorchide übernimmt. Er greift Mansours neues Thema auf („Identitätssuche, Identitätsfindung in der Religion“). Die Valenz ist leicht negativ (-0.20), da er auf ein gesellschaftliches Problem hinweist.
Das Spannendste ist hier der D-Score von -0.080 (Konsolidierend). Ein negativer Wert ist hier absolut positiv zu werten! Es bedeutet, dass Khorchide keine neue Baustelle aufmacht, sondern den in Turn 49 neu gesetzten Themenanker akzeptiert und inhaltlich vertieft. Die neue Richtung der Diskussion ist damit erfolgreich etabliert und gefestigt.
Fazit dieser Sequenz: Die KI beweist hier datenbasiert, dass ein Streit (Turn 49) extrem produktiv sein kann, wenn er dazu genutzt wird, ein festgefahrenes Thema radikal zu wechseln. Und sie zeigt, wie gutes Zuhören und Aufgreifen durch nachfolgende Sprecher (Turns 50 & 51) das Stresslevel im Raum sofort senkt.
Zusammenfassung:
Ich beende hiermit (vorläufig) die Attention Collective Mind Blog-Reihe. Ich konnte zeigen, dass der Attention Mechanismus, der allen großen LLM KI-Systemen zugrunde liegt, auch erfolgreich auf die menschliche Kommunikation angewendet werden kann. Verwendet man ein Vektor-Persönlichkeitsmodell in das u.a. Big-Five, Werte und Emotionen (und ggf. der Projekttyp zur Beschreibung der Aufgabenstellung) eingehen, so lässt sich auf dieser Basis ein RL-Agent mittels Reinforcment Learning trainieren. Dieser RL-Agent unterstützt in einem hybriden Collective Intelligence Setting eine Führungskraft bzw. einen Moderator bei der Wahrnehmung der Team- bzw. Gruppendynamik und gibt aktiv in Echtzeit Empfehlungen für die Führung.
Anhang: Glossar und Formeln zum mathematischen Modell
Glossar: Die Vokabeln der KI-Simulation
Um die Dynamik einer Talkshow mathematisch zu berechnen, übersetzt die KI menschliches Verhalten in Datenpunkte. Hier sind die wichtigsten Begriffe aus der Psychologie und Datenwissenschaft einfach erklärt:
1. Die emotionale Ebene (Affective Computing)
Die KI bewertet jeden gesprochenen Satz nach zwei grundlegenden emotionalen Dimensionen:
-
Valenz (Valence): Beschreibt, ob eine Aussage positiv oder negativ ist. Negative Valenz (-1.0) bedeutet Angriff oder Kritik. Positive Valenz (+1.0) bedeutet Zustimmung oder Brückenbau.
-
Arousal (Erregungsniveau): Beschreibt die emotionale „Temperatur“. Hohes Arousal bedeutet, dass jemand passioniert oder hochgradig gestresst spricht. Ein negativer Satz, der geschrien wird (hohes Arousal), erzeugt mehr Systemstress als ein negativer Satz, der ruhig geäußert wird.
2. Die Gesprächsdynamik (Systemphysik)
-
Fatigue (Kognitive Erschöpfung): Wer lange spricht, verbraucht kognitive Energie. Wer zuhört, regeneriert sich leicht. Das System nutzt diesen Wert, um zu erkennen, wann ein Redner „leergesprochen“ ist.
-
Stresspegel (Individueller Stress): Ein Wert zwischen 0 und 1. Er steigt bei Angriffen und sinkt durch sachliche Klärung oder wenn man längere Zeit nicht attackiert wird (Abkühlungsphase).
-
Systemspannung (Kollektive Energie): Die Summe der individuellen Stresspegel aller Anwesenden. Steigt dieser Wert über eine kritische Grenze, steht die Diskussion kurz vor der Eskalation.
3. Die Persönlichkeit (Die „Big Five“)
Die Profile der Diskutanten basieren auf dem etablierten psychologischen OCEAN-Modell:
-
(O) Offenheit: Die Bereitschaft für neue, unkonventionelle Ideen.
-
(C) Gewissenhaftigkeit: Der Drang nach Struktur und Fakten.
-
(E) Extraversion: Das Bedürfnis, im Mittelpunkt zu stehen.
-
(A) Verträglichkeit (Agreeableness): Das Bedürfnis nach Harmonie und Konsens.
-
(N) Neurotizismus: Die Anfälligkeit für Stress bei Gegenwind.
4. Die linguistische Analyse (NLP & Disruption)
-
Text-Embeddings: KI-Modelle wandeln Sätze in mathematische Koordinaten (Vektoren) um. Sätze mit ähnlichem Inhalt liegen nah beieinander.
-
Kosinus-Ähnlichkeit: Eine Formel, die misst, ob zwei Personen inhaltlich über das Gleiche sprechen oder aneinander vorbei reden.
-
Disruption (D-Score): Das Maß für inhaltlichen Fortschritt. Ein negativer D-Score bedeutet, die Sprecher drehen sich im Kreis (Konsolidierung). Ein positiver D-Score bedeutet, ein Sprecher bringt einen radikalen „Game-Changer“ (Disruption / Topic Pivot).
Technischer Anhang: Mathematische Modellierung der Diskursdynamik
In diesem Anhang werden die Formeln erläutert, die zur Berechnung der Zustandsänderungen der Diskutanten und der inhaltlichen Struktur der Sendung verwendet wurden.
Die folgenden Funktionen sind Terme der geänderten Reward-Funktion:
1. Erschöpfungsmodell (Fatigue)
Die Erschöpfung eines Sprechers steigt durch den kognitiven Aufwand der Artikulation, während die Zuhörer eine leichte Regeneration erfahren.

Erläuterung:
-
 : Erschöpfungsgrad des Teilnehmers zum Zeitpunkt .
: Erschöpfungsgrad des Teilnehmers zum Zeitpunkt . -
: Zuwachsrate pro Redebeitrag (Modellwert: ).
-
: Regenerationsrate pro Turn des Zuhörens (Modellwert: ).







2. Stress-Dynamik (Emotionale Physik)
Der Stresspegel reagiert auf die emotionale Ladung und die Konfrontation unter Berücksichtigung der Persönlichkeitsunterschiede.
A. Stress-Impact (Eskalation)
Bei negativer Valenz ( ) berechnet sich der Stresszuwachs der Zielperson (
) berechnet sich der Stresszuwachs der Zielperson ( ) wie folgt:
) wie folgt:

Erläuterung:
-
: Das Arousal (Erregungsniveau) des Beitrags.
-
: Die Euklidische Distanz zwischen den Big-Five-Profilen von Sprecher und Zielperson.
-
: Gewichtungsfaktoren für emotionale Intensität und charakterliche Dissonanz.



Die Gewichtsfaktoren sind im Code auf folgende Werte gesetzt:
-
(Emotionale Intensität / Arousal):
0.2 -
(Charakterliche Dissonanz / Big-Five-Differenz):
0.1
Was bedeuten diese Werte für die Simulation?
Das System gewichtet die direkte, hörbare Erregung (Arousal) doppelt so stark wie den reinen Charakterunterschied.
Das ergibt psychologisch Sinn:
-
Die Dominanz der Lautstärke (
): Wenn jemand sehr laut, schnell oder aggressiv spricht (hohes Arousal), erzeugt das bei der Zielperson fast immer sofortigen Stress (Fight-or-Flight-Reaktion), unabhängig davon, wie ähnlich sich die beiden Personen charakterlich sind. -
Der Charakter-Multiplikator (
): Die charakterliche Dissonanz (die Euklidische Distanz der Big-Five-Werte) ist ein feinerer, subtilerer Faktor. Er besagt: Wenn mich jemand kritisiert (negative Valenz), stresst mich das zusätzlich, wenn diese Person ein völlig anderes Weltbild oder eine völlig andere Persönlichkeit hat als ich (z.B. ein hochgradig extravertierter, strukturierter Mensch kritisiert einen introvertierten, sehr offenen Menschen). Da dieser Distanz-Wert (big5_diff) mathematisch oft größer als 1 sein kann, wird er mit dem kleineren Faktor0.1skaliert, damit er die Basis-Erregung nicht komplett überlagert.


Diese beiden Werte sind sogenannte Hyperparameter. Wenn die Simulation auf ein anderes Szenario anpassen werden soll (z. B. ein hochformelles Business-Meeting statt einer Talkshow), könnte man  senken und
senken und  erhöhen, da in professionellen Umgebungen weniger Emotion sichtbar wird, Charakterunterschiede bei Kritik aber vielleicht umso schwerer wiegen.
erhöhen, da in professionellen Umgebungen weniger Emotion sichtbar wird, Charakterunterschiede bei Kritik aber vielleicht umso schwerer wiegen.
B. Der individuelle Stresspegel (Y-Achse in der Abbildung)
Der finale Stresspegel  ist die Summe aus vorherigem Zustand, aktuellen Einflüssen und zeitlichem Zerfall, normiert auf
ist die Summe aus vorherigem Zustand, aktuellen Einflüssen und zeitlichem Zerfall, normiert auf ![[0, 1]](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.png "Rendered by QuickLaTeX.com") .
.

Erläuterung:
-
: Die Netto-Veränderung durch den aktuellen Beitrag.
-
: Die natürliche Abkühlungsrate pro Zeiteinheit (Modellwert: ).



C. Die kollektive Systemspannung
Um zu berechnen, ob der Raum als Ganzes zu eskalieren droht, wird die Systemspannung  als Summe aller individuellen Stresspegel (
als Summe aller individuellen Stresspegel ( ) gebildet.
) gebildet.

Übersteigt  den empirisch festgelegten Schwellenwert (z.B.
den empirisch festgelegten Schwellenwert (z.B.  ), triggert die KI eine Warnung für den Moderator.
), triggert die KI eine Warnung für den Moderator.
3. Semantische Disruption (D-Score)
Die Disruption misst, wie sehr ein Beitrag den inhaltlichen Fokus der Zukunft ( ) von der Vergangenheit (
) von der Vergangenheit ( ) weg hin zum aktuellen Beitrag (
) weg hin zum aktuellen Beitrag ( ) verschiebt.
) verschiebt.

Wobei die Cosinus-Ähnlichkeit definiert ist als:

Erläuterung:
-
: Vektor-Embedding des aktuellen Beitrags.
-
: Durchschnittsvektor der vorangegangenen Beiträge (Vergangenheit).
-
: Durchschnittsvektor der nachfolgenden Beiträge (Zukunft).




Literatur
[1] ZDF (2024) https://www.zdf.de/gesellschaft/markus-lanz/markus-lanz-vom-30-mai-2024-100.html oder http://youtu.be/rpINCu5VmnY
[2] Kim M (2026) Uncovering simultaneous breakthroughs with a robust
measure of disruptiveness, Science Advances|Research Article










 ) im Kommunikationskanal:
) im Kommunikationskanal:
 ) im Kommunikationskanal:
) im Kommunikationskanal:

 ), Fokus (
), Fokus ( ) durch eingehende Reibung, Synergie und Belastung:
) durch eingehende Reibung, Synergie und Belastung:








 ) und Key (
) und Key ( ):
):
 ) und die Standardabweichung (
) und die Standardabweichung ( ) der Zeile
) der Zeile 
 ) und der Maske für Selbstgespräche:
) und der Maske für Selbstgespräche:
 ) der lokalen Eigenschaften und dem Durchschnitt aller Teammitglieder.
) der lokalen Eigenschaften und dem Durchschnitt aller Teammitglieder.


 fließt nun durch ein Multi-Layer Perceptron (MLP) mit zwei verborgenen Schichten. Als Aktivierungsfunktion nutzen wir GELU (Gaussian Error Linear Unit), da sie komplexere Muster besser verarbeiten kann als traditionelle Funktionen. W und b stehen für die Gewichte und Bias-Werte, die die KI lernt.
fließt nun durch ein Multi-Layer Perceptron (MLP) mit zwei verborgenen Schichten. Als Aktivierungsfunktion nutzen wir GELU (Gaussian Error Linear Unit), da sie komplexere Muster besser verarbeiten kann als traditionelle Funktionen. W und b stehen für die Gewichte und Bias-Werte, die die KI lernt. ):
):




 zu den Stimmungen hinzu, um unvorhersehbare menschliche Tagesform zu simulieren.
zu den Stimmungen hinzu, um unvorhersehbare menschliche Tagesform zu simulieren.

 auf sich zieht.
auf sich zieht.

 ein. Erst wenn Tag 14 abgeschlossen ist, wird die finale Verlustfunktion (Loss, L) für die gesamte Episode berechnet. Bis hierhin haben wir nur Daten gesammelt. Jetzt beginnt der eigentliche Lernprozess.
ein. Erst wenn Tag 14 abgeschlossen ist, wird die finale Verlustfunktion (Loss, L) für die gesamte Episode berechnet. Bis hierhin haben wir nur Daten gesammelt. Jetzt beginnt der eigentliche Lernprozess. .
.
![\begin{equation*} \frac{d \mathcal{L}_{total}}{d W} = \sum_{t=1}^{14} \left[ \frac{\partial \mathcal{L}^{(t)}}{\partial s^{(t)}} \sum_{k=1}^{t} \left( \frac{\partial s^{(t)}}{\partial s^{(k)}} \cdot \frac{\partial_{lokal} s^{(k)}}{\partial W} \right) \right] \end{equation*}](https://agilemanagement40.com/wp-content/ql-cache/quicklatex.com-71a68a0c15d9392f2d0ff0af1b437d71_l3.png "Rendered by QuickLaTeX.com")

 , liegt die strategische Überlegenheit des Modells verborgen!
, liegt die strategische Überlegenheit des Modells verborgen!