Das Thema Kollektive Intelligenz hat gerade Hochkonjunktur. Sei es in Form der mehrteiligen ZDF-Fernsehserie der Schwarm [1] und der damit verbundenen zweiteiligen Terra X Dokumentationen zur Intelligenz von Schwärmen [2], [3]. – Oder, auch in Form der AI Systeme chatGPT und des gerade veröffentlichten GPT-4 [4]. – Diese Systeme sind in zweierlei Hinsicht Systeme kollektiver Intelligenz: Die GPT-X Systeme und andere vergleichbare Systeme verwenden als Daten die Ergebnisse unserer aller Intelligenz und die Systeme selbst sind über die Neuronalen Netzwerke, auf denen sie beruhen, kollektive Systeme, die Intelligenz hervorbringen können, wenn sie mit unserer Intelligenz in Form von Daten gefüttert werden. – Dies ist gar nicht so unähnlich unserer kulturellen Entwicklung, die Produkte menschlicher Intelligenz hervorgebracht hat – nur eben viel, viel schneller!
Es ist absehbar, dass sich in Zukunft aus der Intelligenz von GPT-X eine Künstliche Allgemeine Intelligenz (Artificial General Intelligence, kurz AGI) entwickeln wird. Der CEO von openai betont in einem Blogbeitrag erst kürzlich hierzu die gesellschaftliche Verantwortung von openai [5] und im EU AI Act Newsletter wird, meines Erachtens zum ersten Mal, von der nahen Bedeutung von AGI im Kontext von GPT-X Systemen gesprochen [6].
In [2] und [3] wird eindrucksvoll geschildert, wie natürliche kollektive mobile Systeme, die aus ‚dummen‘ Agenten (u.a. Ameisen, Bienen, Fischen) bestehen, im Schwarm intelligentes Verhalten zeigen. Die vermeintlich ‚dummen‘ Agenten haben ihrerseits ein wenig Intelligenz auf der Basis von kleinen natürlichen neuronalen Netzwerken. – Die Natur ist also offensichtlich in der Lage mittels kollektiver Systeme (z.B. Ameisen Kollektiv) und von Subsystemen (z.B. Ameise als Agent) Intelligenz-Hierarchien aufzubauen.
Dies relativiert auch unseren Anspruch an intelligenter Einzigartigkeit: Kollektive Systeme, gleichgültig ob natürlich oder künstlich, haben das Potential, über eine geeignete Vernetzung, Intelligenz auszubilden.
Hieraus leite ich die These ab, dass Intelligenz immer kollektiv ist. Dies wird auch durch Ashby’s Law [7] gestützt, wonach ein komplexes System nur durch ein anderes komplexes System mit hinreichender Komplexität reguliert werden kann. Komplexität ist also eine Vorbedingung für Intelligenz. Deshalb sagen wir auch im Management 4.0, dass Komplexität ein Geschenk ist, das nicht reduziert werden sollte, sondern nur reguliert werden darf: Die Komplexität unseres Gehirns (und unseres gesamten Körpers) mit ca. 86 Milliarden vernetzter Neuronen ermöglicht es, dass wir uns adaptiv auf unsere Umgebung einstellen und diese ggf. regulieren. – Ich nehme an, dass niemand seiner Intelligenz, also seiner neuronalen Komplexität, beraubt werden möchte, indem diese reduziert wird.
In Konsequenz heißt dies auch, dass gut geführte soziale Organisationen, u.a. Teams, mit einer wertschaffenden Komplexität, kollektive Intelligenz zeigen, die über die Intelligenz der einzelnen Teammitglieder hinausgeht. Die einzige ! Aufgabe von Führung ist es, zu ermöglichen, dass sich diese kollektive Intelligenz ausbildet.
Es ist vielleicht auch nicht abwegig, anzunehmen, dass Intelligenz eine Vorbedingung für Bewusstsein ist. – Und, dass Bewusstsein sich aus intelligenten kollektiven Systemen emergent entwickelt. Die Integrated Information Theory zum Bewusstsein zeigt erste Überlegungen in diese Richtung [8].
Im letzten Blog-Beitrag habe ich den Video-Vortrag des DeepMind Mitarbeiters Thore Graepel zum Thema ‚Multi-Agent Learning in Artificial Intelligence‘ erwähnt [9]. Thore Graepel referenziert dort am Anfang auf den Artikel von Legg und Hutter zum Thema ‚Universal Intelligence‘ [10]. Legg und Hutter geben einen Literatur-Überblick zum Verständnis von Intelligenz und definieren ihr Verständnis von Agent Intelligence:

In [10] wird angenommen, dass die Wahrscheinlichkeit für Kontexte exponentiell (zur Basis 2) mit der Komplexität abnimmt. – Hier folgen Legg und Hutter auch dem Prinzip des Occam’schen Rasiermessers [11]: Die Natur bevorzugt Einfachheit und unsere Modelle zu Ihrer Beschreibung sollten dementsprechend auch einfach sein. – Einfache Kontexte werden also bei der Intelligenzberechnung höher gewichtet. Man kann auch jetzt verstehen, warum die melting pot Initiative von DeepMind von Bedeutung ist: Es werden möglichst viele Kontexte erstellt, um die allgemeine Intelligenz von Agenten über die obige Formel zu ermitteln.
Legg und Hutter haben gezeigt, dass die obige Formel für Intelligenz alle bekannten Definitionen von Intelligenz subsummiert und auch auf den Intelligenzbegriff bei Menschen angewendet werden kann.- Auch wenn die konkrete Ausgestaltung von V und P in der obigen Formel für nachvollziehbare Kritik sorgt [12] und sich noch ändern dürfte. – Abbildung 2 visualisiert die Formel, in dem ich für das Mindset eines Agenten die Dilts Pyramide angenommen habe: Der Agent passt sich über die Zeit in einem PDCA-Zyklus mittels seiner Fähigkeiten und seines Verhaltens (auch policy genannt) an seine Umgebung an. Über die Funktion V wird die Performance des Agenten im Hinblick auf ein Ziel gemessen.- Der Agent erhält eine Belohnung. Die Performance des Agenten kann in zweierlei Hinsicht gemessen werden: Intern und extern. Das interne Performancemaß wird utility U genannt [13]. Agenten werden rational genannt, wenn sie anstreben das interne Performancemaß mit dem externen in Einklang zu bringen. Einer der Kritikpunkte an [10] ist, dass (lediglich) das externe Performancemaß zur Intelligenzmessung herangezogen wird.
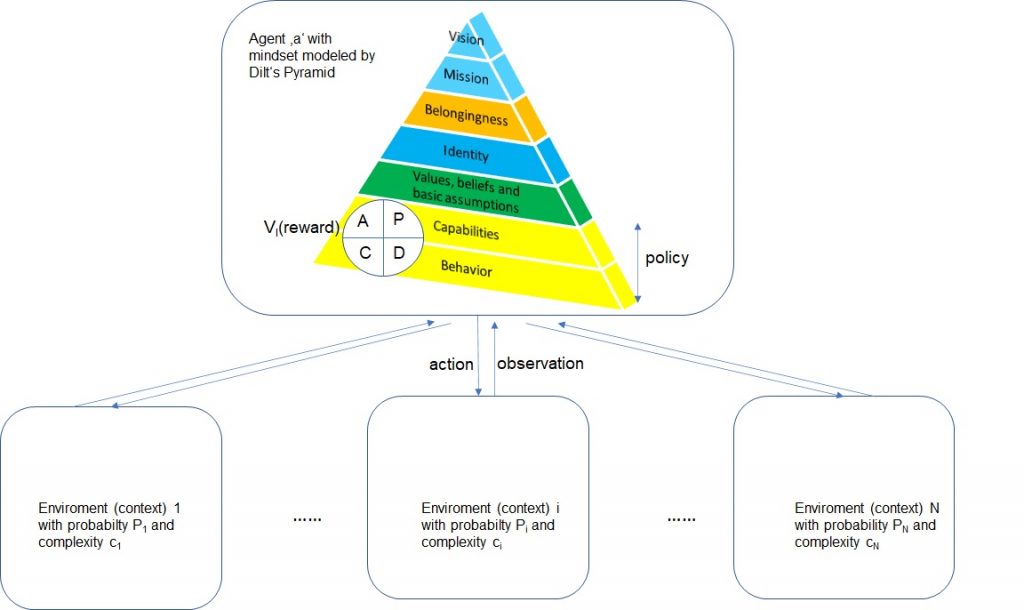
Die Definition der Universellen Intelligenz ist sicherlich als Referenz für die Vermessung von Agenten Intelligenz sehr hilfreich. Ihre operative Ausgestaltung hat aber erst begonnen. – Und, sie ist rein phänomenlogisch, sie sagt also nichts über die Ingredienzien von Intelligenz aus, also welche Elemente wie zusammengebracht werden müssen, um intelligente Agenten bzw. Systeme zu bauen. Aus diesem Grunde versuche ich im Folgenden, einige mir wichtig erscheinende Elemente, in Form von Prinzipien, zu nennen. Ich lasse mich hierbei von der Transformer Technologie leiten, auf der die GPT-X Technologie beruht. Die aus meiner Sicht mit Abstand beste Darstellung zur Transformer-Technologie hat Ralph Krüger geschrieben – er macht keine verständnislosen Vereinfachungen, sondern beschreibt die Technologie didaktisch brillant [14]. Nicht desto weniger kann es manchmal beim Lesen helfen, die in Bing eingebundene chatGPT Bot Version als Assistenz zu benutzen ;-).
Neben [14] empfehle ich [15], eine dreiteilige sehr gute visuelle Aufbereitung des Matrizen-Flows (Tensorflows) in Transformern und für einen tieferen Blick in die Programmierung den Dreiteiler [16] sowie [17]. Als Einstieg kann der Spektrum der Wissenschaft Artikel von Manon Bischoff dienen [18]. Dieser Artikel enthält eine ganze Reihe interessanter Hinweise, u.a. auch die von mir im letzten Blog-Beitrag geäußerte Vermutung, dass chatGPT lediglich 1,5 Milliarden Parameter enthält, also mehr als 100 mal weniger als GPT-3. Manon spricht sogar von nur 1,3 Milliarden Parametern. Als Einstieg empfehle ich zusätzlich den Artikel über chatGPT [19].
Auf der Basis dieser Literatur liste ich im Folgenden die Prinzipien, die meines Erachtens das Was und das Wie der Intelligenz ausmachen:
Intelligenz ist immer kollektiv: Als Kollektiv bezeichne ich ein System von vernetzten Elementen (künstliche oder natürliche Neuronen, Ameisen, Menschen, usw.), das die Außenwelt per Transformation in eine Innenwelt abbildet. Die Transformation erfolgt im Falle der AI durch künstliche neuronale Netzwerken, die Tensor Operationen durchführen (bzw. Matrizenoperatione durchführen: Die Matrizenelemente sind die Gewichte zwischen den Neuronen). – Die Tensor Operationen sorgen also für die Abbildung. Damit diese Abbildung hinreichend viele Informationen der Außenwelt abbilden kann, benötigt sie viele Zustände, also viele Parameter, im Falle von GPT-3 175 Milliarden. Die Abbildung der Außenwelt über eine Parametrisierung in der Innenwelt, erfolgt über Selbstorganisations-Mechanismen, in denen eine Zielfunktion im AI-Training dafür sorgt, dass die niedrigsten energetischen Zustände in dem hochdimensionalen Parameterraum gefunden werden. – Diese repräsentieren nach dem Training die Daten der Außenwelt.
Ich habe die Bing AI gefragt, ‚Gibt es eine Zielfunktion für das Lernen im Gehirn‘. Bing AI wandelt dies in eine Frage nach ‚Zielfunktion Lernen Gehirn‘ um und generiert folgende Antwort:
Ja, das Gehirn hat eine Zielfunktion für das Lernen. Das Lernen ist im Grunde genommen eine Reaktion unseres Gehirns auf neue Erfahrungen. Wenn eine solche Erfahrung eine nachhaltige Änderung im Gehirn hervorruft, dann kann man von Lernen sprechen. Das Gehirn bereitet sich dadurch auf die Zukunft vor. Natürlich kann man sein Gehirn anregen und unterstützen, neue Dinge schneller zu lernen oder die synaptischen Verbindung zu bilden, die man möchte. Dazu brauchen wir nur unsere Aufmerksamkeit genau auf die zu lernenden Themen zu richten und sie entsprechend oft wiederholen.
Diese Definition der Zielfunktion entspricht nicht ganz meinem obigen Verständnis einer Zielfunktion: Außer, man versteht die neuronalen Mechanismen, die sich hinter der Aufmerksamkeit verbergen, als solche.
Die Außenwelt wird über Aufmerksamkeit kontextualisiert: Im Falle der Transformer-Technologie ist der Aufmerksamkeits-Mechanismus (Attention-Mechanismus) der Mechanismus, der die Leistungssteigerung gegenüber vorherigen AI Systemen wesentlich ausmacht. Hierzu werden die sprachlichen Inhalte der Außenwelt auf ihre semantischen Zusammenhänge hin analysiert: Alle Worte eines Satzes (eines Textes) werden herausgegriffen, also mit Aufmerksamkeit belegt, und es wird die Korrelation dieses herausgegriffenen Wortes zu allen anderen Worten in diesem Satz (diesem Text) ermittelt. – Die Korrelationswahrscheinlichkeiten werden in speziellen neuronalen Netzwerken (Tensoren) trainiert. Für die Generierung von neuen Texten wird auf diese trainierten Korrelationswahrscheinlichkeiten zurückgegriffen.
Wahrscheinlichkeiten werden durch zusätzliche kollektive Maßnahmen auf verschiedenen Ebenen ausbalanciert: Die Ergebnisse, die ein Transformer nach außen liefert, sind die Ergebnisse mit der höchsten Wahrscheinlichkeit. Um die Verlässlichkeit der Wahrscheinlichkeiten zu erhöhen, werden die Wahrscheinlichkeiten pro Transformer Modul nicht nur einmal berechnet, sondern mehrmals parallel d.h. zum Beispiel mit 8 attention Mechanismen, dem sogenannten multi-head-attention. Zusätzlich werden im Falle von GPT-3 96 Transformer Module (Decoder) hintereinander geschaltet, um die Ergebnisse zu verfeinern und zu stabilisieren [18]. Der multi-head-attention Mechanismus zeigt damit die Wirkung eines Teams mit acht Teammitgliedern, in dem die potentiellen mentalen Verzerrungen der Teammitglieder ausbalanciert werden. Und, das Hintereinanderschalten der Transformer-Module lässt sich gut mit der iterativen Wirkung von 96-PDCA-Zyklen vergleichen.
… ggf. weitere Prinzipien
Ich glaube, dass Intelligenz nicht auf natürliche Systeme beschränkt ist, ja dass diese Einteilung in natürliche und künstliche Systeme künstlich ist: Intelligenz ist ein universelles Phänomen, das sich potentiell in allen Systemen ausdrücken kann, sobald hierfür die Voraussetzungen vorliegen…. Vielleicht sind die oben genannten Prinzipien tatsächlich (einige) der Voraussetzungen …Vielleicht wird die Filmreihe ‚Autobots – The Transformers‘ sogar einmal als (diesbezüglich) hellsehend bezeichnet werden [20].
[1] ZDF (2023a) Der Schwarm, https://www.zdf.de/serien/der-schwarm
[2] ZDF (2023b) Terra X – Schlaue Schwärme, Geheimnisvolle Sprachen, https://www.zdf.de/dokumentation/terra-x/schlaue-schwaerme-geheimnisvolle-sprachen-doku-102.html
[3] ZDF (2023c) Terra X – Schlaue Schwärme, Rätselhafte Kräfte, https://www.zdf.de/dokumentation/terra-x/schlaue-schwaerme-raetselhafte-kraefte-doku-100.html
[4] openai (2022) GPT-4, https://openai.com/product/gpt-4, zugegriffen am 20.03.2023
[5] Altman S (2023) Planning for AGI and beyond, https://openai.com/blog/planning-for-agi-and-beyond, zugegriffen am 15.03.2023
[6] The future of Life Institute (2023) The EU AI Act Newslettr #25 vom 01/03/23-14/03/23
[7] Wikipedia (2023) Ashby’s Law, https://de.wikipedia.org/wiki/Ashbysches_Gesetz, zugegriffen am 15.03.2023
[8] Wikipedia (2023a) IIT- Integrated Information Theory, https://en.wikipedia.org/wiki/Integrated_information_theory, zugegriffen am 15.03.2023
[9] Graepel T (2023) The role of Multi-Agent Learning in Artificial Intelligence Research at DeepMind, https://www.youtube.com/watch?v=CvL-KV3IBcM&t=619s, zugegriffen am 06.02.2023
[10] Legg S und Hutter M (2007) Universal Intelligence: A Definition of Machine Intelligence, arXiv:0712.3329v1
[11] Wikipedia (2023b) Occam’s razor, https://en.wikipedia.org/wiki/Occam%27s_razor, zugegriffen am 21.03.2023
[12] Park D (2023) Paper Summary: Universal Intelligence: A Definition of Machine Intelligence, https://crystal.uta.edu/~park/post/universal-intelligence/, zugegriffen am 06.03.2023
[13] Russel S und Norvig P (2016) Artificial Intelligence – A modern approach, Third Edition, Prentice Hall Series in Artificial Intelligence Series, Pearson Education Limited
[14] Krüger R (2021) Die Transformer-Architektur für Systeme zur neuronalen maschinellen Übersetzung – eine popularisierende Darstellung, in trans-kom 14 [2], Seite 278-324
[15] Doshi K (2022) Transformers Explained Visually: How it works, step-by-step published January 2, 2021, towardsdatascience.com, zugegriffen am 10.05.2022, (Part 1, 2, 3, 4), https://towardsdatascience.com/transformers-explained-visually-part-1-overview-of-functionality-95a6dd460452, https://towardsdatascience.com/transformers-explained-visually-part-2-how-it-works-step-by-step-b49fa4a64f34, https://towardsdatascience.com/transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853, https://towardsdatascience.com/transformers-explained-visually-not-just-how-but-why-they-work-so-well-d840bd61a9d3
[16] Gosthipaty A R und Raha R (2022) A Deep Dive into Transformers with Tensorflow and Keras, Part 1-3, PyImagesearch.com, published November 2022, zugegriffen am 06.12.2022, https://pyimagesearch.com/2022/09/05/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-1/, https://pyimagesearch.com/2022/09/26/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-2/, https://pyimagesearch.com/2022/11/07/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-3/
[17] Cristina S (2023) Training the Transformer Model, https://machinelearningmastery.com/training-the-transformer-model/, updated am 06.01.2023, zugegriffen am 20.03.2023
[18] Bischoff M (2023) Wie man einem Computer das Sprechen beibringt, https://www.spektrum.de/news/wie-funktionieren-sprachmodelle-wie-chatgpt/2115924, veröffentlicht am 09.03.2023, zugegriffen am 20.03.2023
[19] Ruby M (2023) How ChatGPT Works: The Model Behind the Bot, https://towardsdatascience.com/how-chatgpt-works-the-models-behind-the-bot-1ce5fca96286, veröffentlicht am 30.01.2023, zugegriffen am 20.03.2023
[20] Wikipedia(2023) Autobot, https://en.wikipedia.org/wiki/Autobot, zugegriffen am 20.03.2023