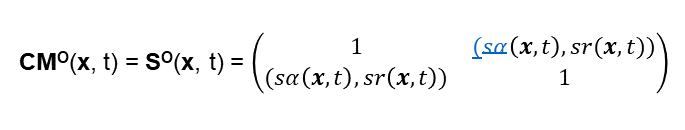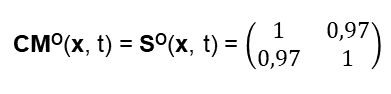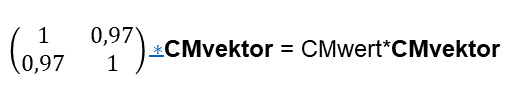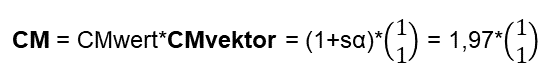Über Jahrhunderte hinweg haben die berühmtesten Philosophen versucht das „Ding an sich“ auszuleuchten und zu finden. Es ist ihnen nicht gelungen, da es meines Erachtens das „Ding an sich“ nicht gibt.
Es gibt Dinge oder Objekte, aber diese werden ganz entscheidend durch ihre Wechselwirkung mit ihrer Umgebung bestimmt. – Andere Umgebungen und schon sind Objekte oft ganz anders. – Die Relationen, also die Beziehungen, zwischen den Objekten bestimmen ganz entscheidend das Sein. – Deswegen habe ich diesem Blog-Beitrag den Titel „Sein als Netzwerk“ gegeben.
Das Studium von Netzwerken in Natur, Sozialem oder Technik mittels mathematischer Methoden ist schon mehrere hundert Jahre alt und ist eng mit dem Namen des französischen Mathematiker’s Pierre-Simon Laplace verbunden [1]. – Im zwanzigsten Jahrhundert wurde die Netzwerkanalyse zu einer vollständigen Disziplin, u.a. in den Sozialwissenschaften, ausgebaut [2], [3].
Die erfolgreiche Netzwerkanalyse ist einer der Grundpfeiler für den Erfolg von google: Der PageRank Algorithmus misst die Bedeutung von Internetknoten (homepages) im Netzwerk Internet [4]. – Weiter unten werde ich diesen Algorithmus für das Vermessen der Bedeutung von Begriffen in einem Text benutzten. – Denn ich nehmen an, dass bedeutende Begriffe und deren Relationen die mentale Ausrichtung eines Teams beschreiben.
Die Netzwerkanalyse, oft auch Graphentheorie genannt, hat in den letzten Jahren im Bereich AI/ML eine enorme Bedeutung erhalten: Graphentheorie und Neuronale Netzwerke sind eine Relation 😉 eingegangen. Es entstand die AI/ML Disziplin Graph Neural Networks (GNN) [5]. – Im letzten Blog-Beitrag war Word-embedding der Schwerpunkt. GNN basieren auf dem Embedding von Netzwerken in höher-dimensionale abstrakte Räume. – Einige der aktuellen spektakulären AI/ML Erfolge, wie zum Beispiel in der Medikamentenerforschung, gehen auf diese Relation von Graphentheorie und AI/ML zurück.
GNN sind high-end AI/ML Systeme, die aktuell sehr viel Know-How erfordern. In vielen Fällen dürfte es jedoch genügen, Netzwerke lediglich sichtbar zu machen und erste Analysen, wie den mathematisch recht einfachen PageRank Algorithmus, anzuwenden. Genau dies will ich in diesem Artikel an einem Beispiel demonstrieren. – Hierbei steht, wie schon im letzten Beitrag, die grundlegende Idee im Vordergrund und nicht die Erzeugung oder Vermarktung eines vollständigen Produktes.
In meinem Blog-Beitrag vom Dezember 2021 habe ich erstmals für die IPMA PM Kompetenzbereiche Beispiele zu Graphen Anwendungen genannt. Hier nochmals einige Beispiele:
Führung und Stakeholder: Soziale Netzwerke können mittels Graphen oder GNN analysiert werden. Dies kann auf Teamebene und auf der Ebene aller Stakeholder erfolgen. Hierzu wird u.a. der eMail-Austausch einer Organisation analysiert und in einem Graphen sichtbar gemacht. Relative einfache Werkzeuge, wie der PageRank Algorithmus zeigen die relative Bedeutung von Knoten (d.h. hier Personen) im Netzwerk an.
Führung, Kommunikation, Teamarbeit: Die verbale Kommunikation wird mittels Graphen analysiert und die Analyse wird als Feedback in das Team gegeben. Oder die AI/ML Analyse unterstützt die Führungskraft bei ihrer Selbstreflexion und abgeleiteten Team-Interventionen. Aus der Analyse der Kommunikation lassen sich auch Collective Mind Target Hierarchien erzeugen. Das Beispiel, das ich weiter unten skizziere, gehört in diese Kategorie.
Planung und Steuerung: Aus Texten werden Graphen abgeleitet, aus denen wiederum Projektpläne erzeugt werden. Auf der Basis der Graphen und mittels GNN werden u.a. Risiken ermittelt und Aufwände abgeleitet. Diese Informationen können im Projektzeitverlauf auch für das Projektmonitoring verwendet werden.
Die letzte Kategorie ist eine deutlich anspruchsvollere Aufgabe als die beiden vorherigen Anwendungskategorien. Die beiden ersten Anwendungskategorien lassen sich in der ersten Ausbaustufe mit den in diesem Blog skizzierten Techniken bewältigen.
Im letzten Blogbeitrag habe ich die Ähnlichkeit von (gesprochenen) Texten, d.h. die Similarity, dazu benutzt, ein Maß für die Stärke des Collective Mind abzuleiten. In diesem Fall wurden Wort-Relationen über deren Einbettung in einen hochdimensionalen abstrakten Raum benutzt, um die Similarity zu berechnen.
In diesem Blogbeitrag will ich die Graphentheorie und AI/ML dazu benutzten, Texte auf enthaltene Relationen zu analysieren und diese Relationen in einem Graphen sichtbar zu machen. – Es steht also die Visualisierung von Kommunikation im Vordergrund: Die Visualisierung mittels Graphen macht in einer Kommunikation sehr schnell Zusammenhänge sichtbar. Die These ist, dass über visualisiertes Feedback in ein Team, der Prozess der Collective Mind Ausbildung deutlich beschleunigt wird.
Ich benutze den Code von Thomas Bratanic [6], der auf towardsdatascience.com zu finden ist. Towardsdatascience.com ist eine hervorragende Fundgruppe für alle möglichen Fragestellungen rund um das Thema AI/ML.
Bratanic demonstriert die Graphenanalyse am Beispiel der Analyse von Wikipedia-Seiten zu drei Wissenschaftlerinnen. Hierzu werden die Wikipedia-Seiten in page.summaries mit einfachen Sätzen zusammengefasst. – Wir werden später sehen, dass diese einfachen Sätze (derzeit noch) notwendig sind, um die NLP-Verarbeitung gut durchzuführen. Abbildung 1 zeigt einen Auszug aus diesem Ergebnis:
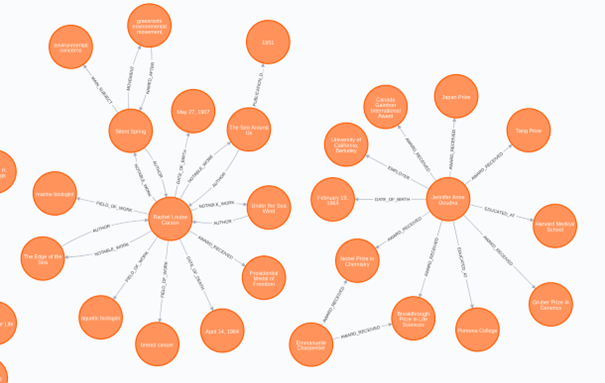
Die Grundidee ist einfach: Es werden Sätze in Texten oder Gesprochenem in „Subjekt-Relation->Objekt“ Strukturen (S-R->O Strukturen) zerlegt. Zum Beispiel ergibt der Satz „Alfred wohnt in Stolberg.“ die Struktur „Alfred – wohnt in -> Stolberg“. Die gefundenen S-R->O Strukturen werden in eine Graphen-Datenbank transferiert. Hier können verschiedene Netzwerkanalysen durchgeführt werden.
Die AI/ML Technik hierzu ist schon nicht mehr so einfach: Wie im letzten Blog-Beitrag kommt die NLP-Bibliothek spaCy [7] zum Einsatz. Hinzukommen diverse raffinierte NLP-Python-Skripte, die high-end Transformator Pipeline aus der tensorflow-Technologie [8] und zum Schluss die Graphendatenbank Neo4j [9]. Das Ganze ist nach diversen Anpassungen und einige Zeit später als Jupyter-Notebook [10] in der Colab-Umgebung [11] lauffähig.
Wie schon im letzten Blogbeitrag, habe ich der Einfachheit wegen den Text der Definition von Agile Management 4.0 benutzt. Der erste Lauf mit diesem Text zeigt jedoch, dass kaum Relationen extrahiert wurden. – Der Text ist zu verschachtelt geschrieben. Dementsprechend habe ich ihn in einfache Sätze umgeschrieben. – Ich hätte auch einen entsprechenden AI/ML pre-processing Schritt vorwegschalten können, der Text in einfachen Text mit S-R->O Strukturen transformiert. Dies hätte den Aufwand jedoch deutlich erhöht. – Mit entsprechenden AI/ML Techniken stellt dies jedoch kein prinzipielles Problem dar. – Ich habe den Text auch teilweise belassen wie er ist, um die Auswirkungen zu sehen.
Hier der verwendete Text:
“Agile Management is a leadership and management practice. Agile Management is able to act in an agile and proactive way. Agile Management is for acting in a complex environment. The complex environment is characterized by uncertainty. Agile Management is described as an Agile Mindset. The Agile Mindset is focused on leadership. The basis of leadership is self-leadership. Leadership is based on respect for basic human needs. Leadership demands an understanding of complex systems. Leadership regulates complexity. Regulation of complexity is done by iterative procedures. Leadership is based on people who use self-organization in teams. Agile Management creates fluid organizations. Fluid organizations promote adaptable and fast delivery of useful results and create innovative customer solutions through proactive dealing with changes.”
Dieser Text wird von dem AI/ML-System in S-R->O Strukturen transferiert, die in der Graphendatenbank Neo4j folgende Visualisierung erhalten:
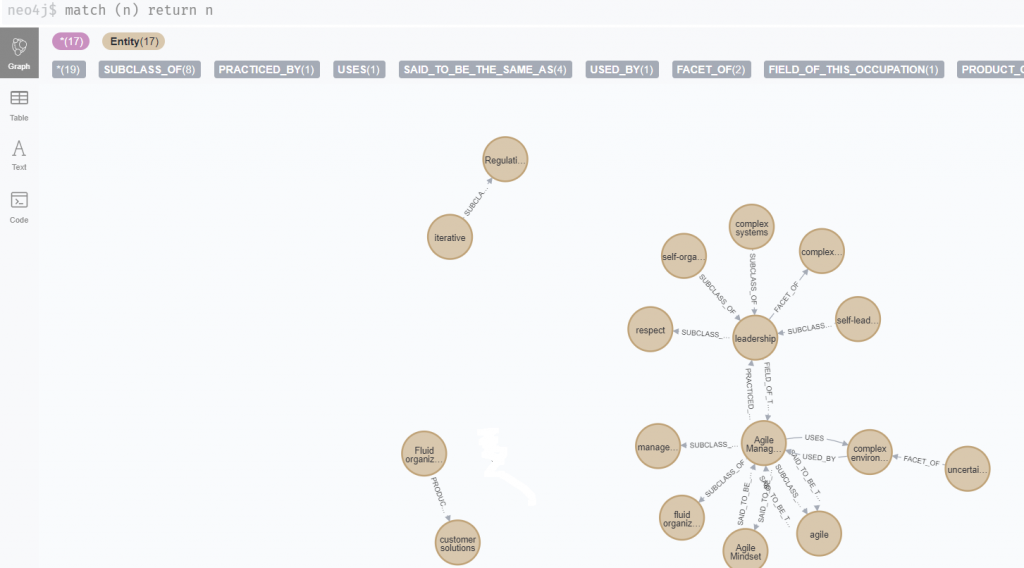
Agile Management und leadership werden als zentrale Knoten erkannt. Die Sätze
„Regulation of complexity is done by iterative procedures.”
und
“Fluid organizations promote adaptable and fast delivery of useful results and create innovative customer solutions through proactive dealing with changes.”
sind in zwei getrennten Netzwerkclustern enthalten. Der zweiten Satz ist auch nicht vollständig abgebildet. Dies ist meinem unzureichenden manuellen Pre-Processing geschuldet. Bei diesem Satz kann man auch schön erkennen, dass „Fluid organization“ und „fluid organization“ nicht als gleiche Nomen erkannt werden.
Für den ganzen Text gilt, dass die Verben des Textes in allgemeinere Relationsbezeichnungen abgebildet werden. Diese haben ihren Ursprung in einem entsprechenden vorgegebenen NLP Training von spaCy.
Auch mit diesen Einschränkungen stellt die Visualisierung des Textes einen erheblichen Mehrwert dar: Denn man möge sich nur vorstellen, dass ein entsprechendes AI/ML System online und ad hoc Teamkommunikation auf solche Weise visualisiert als Feedback an das Team zurückgibt. – Dies würde meines Erachtens den Kommunikationsprozess erheblich beschleunigen und die Visualisierung wäre auch gleichzeitig eine Visualisierung des gerade vorhandenen Collective Mind’s. Im Falle einer komplexen Kommunikation wäre die Visualisierung um so hilfreicher: Dies umso mehr, wenn die Visualisierung mehrere oder viele Netzwerkcluster zu Tage fördern würde. Dies entspräche mehreren Gesprächsthemen oder -lagern, die ggf. für mehrere (konkurrierende) Collective Mind’s stünden.
Neben der Visualisierung können diverse Werkzeuge der Netzwerktheorie verwendet werden, um Netzwerke zu analysieren [12]. – Dies ist umso notwendiger, je komplexer die Netzwerke aus Personen, Worten, homepages, Molekülen usw. sind. Neo4j stellt mehr als hundert solcher Werkzeuge zu Verfügung, u.a. auch den PageRank Algorithmus. Abbildung 3 zeigt die PageRank-Auswertung für den Graphen aus Abbildung 2.
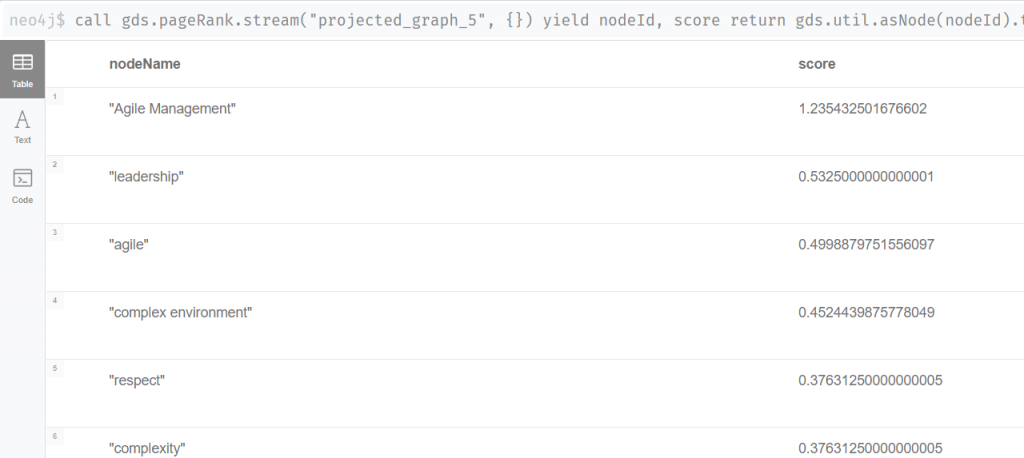
Das PageRanking ist für diesen einfachen Graphen sicherlich keine große Überraschungen: Agile Management und leadership sind die beiden Begriffe, die im Netzwerk gemäß diesem Algorithmus am wichtigsten sind. Für größere Graphen erwarte ich jedoch erhebliche Überraschungseffekte in den Teams oder Organisation, deren Kommunikation auf diese Weise analysiert wird.
Agile Management und leadership sind zwei Begriffs-Attraktoren, die die Ausrichtung der gedachten Teamkommunikation, anzeigen: Das Begriffs-Netzwerk visualisiert den Collective Mind oder den fehlenden Collective Mind einer Kommunikation, je nachdem wie viele konkurrierende Netzwerkcluster (Communities) mit ähnlichem PageRanking es gibt.
Dieses kleine Beispiel illustriert, dass man mit den Mittel von AI/ML erhebliche Informationen über Teams oder Organisationen gewinnen kann. Diese Informationen können im Guten wie im Bösen eingesetzt werden. Berücksichtigt man, dass das Know-how von google und Co. Lichtjahre weiter ist als mein Eigenes, so ist die Einbettung in eine AI Ethik um so wichtiger. Deshalb beabsichtige ich, mich im nächsten Blog mit dem EU AI Act zu beschäftigen [13].
[1] Laplace Matrix (2022) https://en.wikipedia.org/wiki/Laplacian_matrix, Wikipedia, zugegriffen am 19.06.2022
[2] Jansen D (1999) Einführung in die Netzwerkanalyse, VS Verlag für Sozialwissenschaften
[3] Wasserman S, Faust K (1994) Social Network Analysis, Cambridge University Press
[4] PageRank (2022) https://en.wikipedia.org/wiki/PageRank, Wikipedia, zugegriffen am 19.06.2022
[5] Hamilton W L (2020) Graph Representation Learning, Morgan&Claypool Publishers
[6] Bratanic T (2022) Extract knowledge from text: End-to-end information extraction pipeline with spaCy and Neo4j, published May 6, 2022, https://towardsdatascience.com/extract-knowledge-from-text-end-to-end-information-extraction-pipeline-with-spacy-and-neo4j-502b2b1e0754, towardsdatascience.com, zugegriffen am 10.05.2022
[7] spaCy (2022) https://spacy.io/models/de, zugegriffen am 20.04.2022
[8] Transformers (2022) https://huggingface.co/docs/transformers/main_classes/pipelines, huggingface.co, zugegriffen am 20.04.2022
[9] Neo4j (2022) neo4j.com, zugegriffen am 23.06.2022
[10] Jupyter Notebooks (2021) https://jupyter.org/, zugegriffen am 02.12.2022
[11] Colab (2021) https://colab.research.google.com/
[12] Scifo E (2020) Hands-on Graph Analytics with Neo4J, Packt Publishing, Birmingham, kindle edition
[13] EU AI Act (2022) https://artificialintelligenceact.eu/, Europe Administration