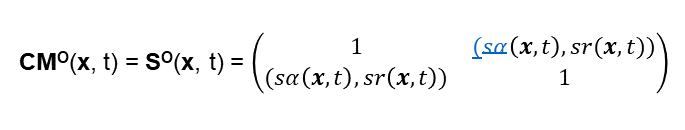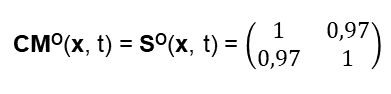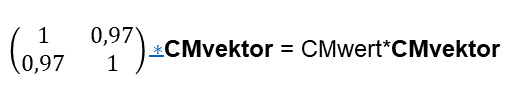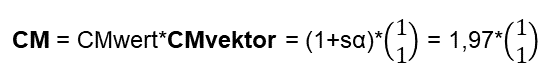Ein Agent Based Model (ABM) ist ein Computer Modell, mit dem Aktionen und Wechselwirkungen sogenannter autonomer Agenten in einem gegebenen Umfeld (u.a. Raum, Zeit) simuliert werden. Das Verhalten der Agenten und des gesamten Systems wird auf Micro- und auf Marco-Ebene sichtbar und verstehbar. Agenten können Menschen, Teams, Organisationen, Nationen, Roboter, Autos, Atome, Viren, Moleküle, Tiere, kurzum jede Form von Entität sein [1].
ABMs gehören zur Disziplin Artificial Intelligence, zu der auch Machine Learning mit der weiteren Unterdisziplin Deep Learning gehört. Die AI/ML Systeme chatGPT und GPT-3 gehören in die Unterdisziplin Deep Learning [2].
ABMs gibt es seit mehr als 50 Jahren. Sie haben Wissenschafts- und Erkenntnis-Geschichte geschrieben. Sie taten dies, in dem einige wenige, meistens sehr einfache Prinzipien zur Beschreibung von Aktionen und Wechselwirkungen in den Computer Modellen verwendet wurden. Diese brachten oft verblüffende Erkenntnisse.
Zwei einfache ABM-Modelle, die Wissenschafts- und Erkenntnisgeschichte geschrieben haben, sind das Segregationsmodell des Nobelpreisträgers Thomas Schelling aus dem Jahre 1971 und das sogenannte Boltzmann Health Modell.
Schelling konnte zeigen, dass einfache Regeln der Zugehörigkeit von Agenten (Personen, Familien, Länder) zu einer Segregation, also der Bildung von Blöcken von Agenten führt. – Während des Kalten Krieges war dies ein deutlich sichtbares Thema. – Leider ist es auch heute wieder und immer noch ein Thema: Russland überfällt die Ukraine, China-USA Rivalität, Klimaschützer contra ‚Auto ist Freiheit‘-Schützer, Corona-Verschwörungstheoretiker contra Impfbefürworter, usw..
Im Boltzmann Wealth Modell (auch ’statistical mechanics of money‘ Modelle genannt) werden alle Agenten mit einem gleichen Grundstock an Geld ausgestattet. Der Zufall bestimmt, welche Agenten wann Geld austauschen. – Genauso wie Moleküle in einem Gas, deshalb spricht man auch von Boltzmann Wealth. Nach einer gewissen Zeit sind einige Agenten sehr reich, sehr viele ärmer bzw. ganz arm. – Der Wohlstand der Agenten folgt einer Boltzmann Verteilung. Das Model zeigt, dass finanzielle Ungleichheit in einem sozialen System auch sehr viel mit Statistik zu tun hat und nicht nur auf den viel beschworenen besonderen Fähigkeiten der Tüchtigen beruht. Statistik ist hier ein anders Wort für Glück und dieses Modell zeigt uns, dass manchmal etwas mehr Demut gegenüber den eigenen „hervorragenden“ Leistungen angebracht ist.
ABMs sind vermutlich dem ein oder anderen im Zusammenhang mit COVID-19 Modellrechnungen im Gedächtnis geblieben. – Die Vorhersagen zur epidemischen Lage beruhten ganz wesentlich auf ABMs.- Im Internet findet man unter dem Stichwort ‚ABM und Corona‘ eine große Zahl an verschiedenen Untersuchungen und Veröffentlichungen.
Die Zukunft der ABMs dürfte wohl mit zwei Innovations-Richtungen verbunden sein: Zum einen werden die Agenten kognitiv immer intelligenter und selbst die emotionale Intelligenz wird heute schon über Persönlichkeitsmodelle teilweise abgebildet. Zum anderen wird die Realität, die die ABMs simulieren sollen über Data Assimilation [3] in einem PDCA ähnlichen Zyklus eingebunden.
Bezüglich der ‚Aufrüstung‘ an AI für ABMs verweise ich auf die Aktivitäten von Deepmind [4, 5, 6, 7]. – Deepmind entwickelt u.a. gerade die open source Testszenario-Plattform ‚melting pot‘ für ABMs. Ziel ist es, möglichst viele Umfeld-Szenarien (bestehend aus Raum, Zeit und anderen Agenten) aufzubauen. Mit den Testszenarien können KI-Entwickler die Intelligenz neu entwickelter Agenten testen.
Die Form der Korrektur von Simulationen mittels Data Assimilation wurde erstmals für die Navigation während der Apollo Mission angewendet und gehört heute zum Standardrepertoire bei Wettervorhersagen. Das Forecasting während der Pandemie beruhte u.a. auch auf dieser Technik. Mein Sohn Yannick Oswald und seine Kollegen der Universität Leeds konnten mittels ABM und Data Assimilation das ‚Kipp-Verhalten‘ der Länder bezüglich der Einführung des Lockdowns zu Beginn der Corona-Pandemie nachbilden (die Länder sind hier die Agenten): Für die globale Makroebene führt das ‚Kipp-Verhalten‘ der Länder zu einem globalen sozialen Phasenübergang [8].
Seit ein paar Wochen habe ich begonnen, mich mit ABMs programmierend zu beschäftigen. Da ich Anfänger bin, habe ich mich auf zwei ABM-Plattformen konzentriert. Die eine ist Netlogo [9] und die andere ist MESA-Python [10, 11, 13, 14, 15].
Netlogo gehört zur Standardausbildung in der Komplexitätsforschung und zum Lehrprogramm des Complexity Explorers des Santa Fe Instituts [16]. MESA-Python ist eine objekt-orientierte Python Entwicklungsplattform für ABM und kann u.a. in der google Colab Umgebung benutzt werden.
Netlogo enthält als Lern-Beispiele nahezu alle ABMs, die Wissenschafts- und Erkenntnisgeschichte geschrieben haben. – Etwas gewöhnungsbedürftig ist die Netlogo eigene Programmiersprache.
Da ich Anfänger bin kam die Idee auf, chatGPT und GPT-3 im Sinne einer Erweiterung meiner Intelligenz zu benutzen. In dem Blog-Artikel vom Februar 2022 habe ich dies als Collective Intelligence Perspective bezeichnet: D.h. Künstliche und menschliche Intelligenz arbeiten kollektiv zusammen.
Das Modell ‚Collective Mind‘ des Management 4.0 ist selbst eine spezielle Form der Collective Intelligence (CI) für Teams und Organisation. Also was liegt näher, als unter Assistenz von chatGPT und GPT-3 ein Netlogo- oder MESA-Python-Programm zu erstellen. Hierbei ist es zunächst nicht wichtig, dass ein beeindruckendes Collective Mind Modell entsteht, sondern, dass diese CI-Vorgehensweise überhaupt funktioniert.
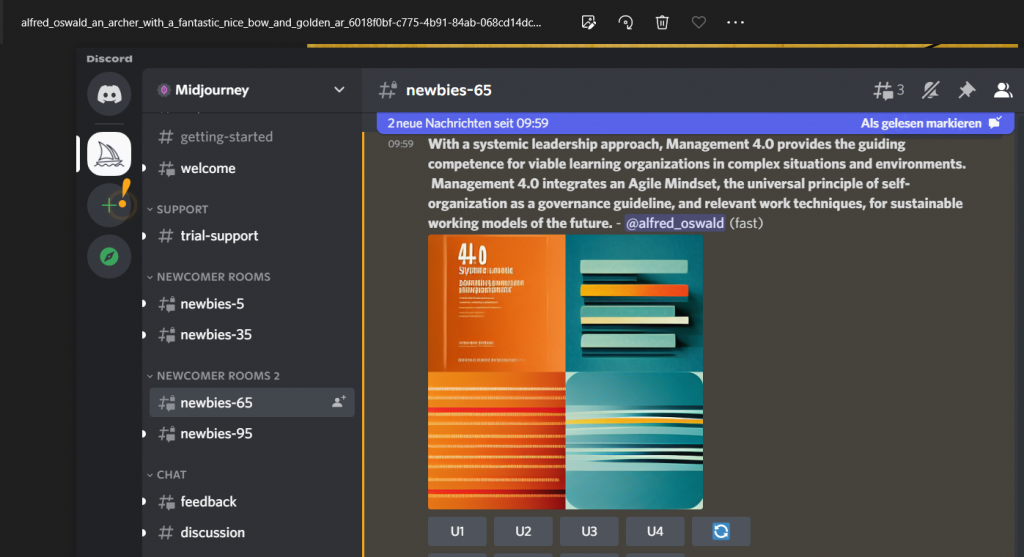
Zuerst habe ich mit chatGPT kommuniziert: chatGPT machte mich auf ABM-Veröffentlichungen aufmerksam, die Persönlichkeitsmodelle wie MBTI und Big Five [17] enthalten. Anschließend fragte ich nach einer Erläuterung zum Collective Mind. Es war ganz offensichtlich, dass chatGPT den Inhalt meiner Bücher und Veröffentlichungen kennt, insbesondere auch die letzte Veröffentlichung zum Thema Projektmanagement und Selbstorganisation [18]. Abbildung 1 zeigt das Ergebnis der chatGPT Ausgabe zu Collective Mind:
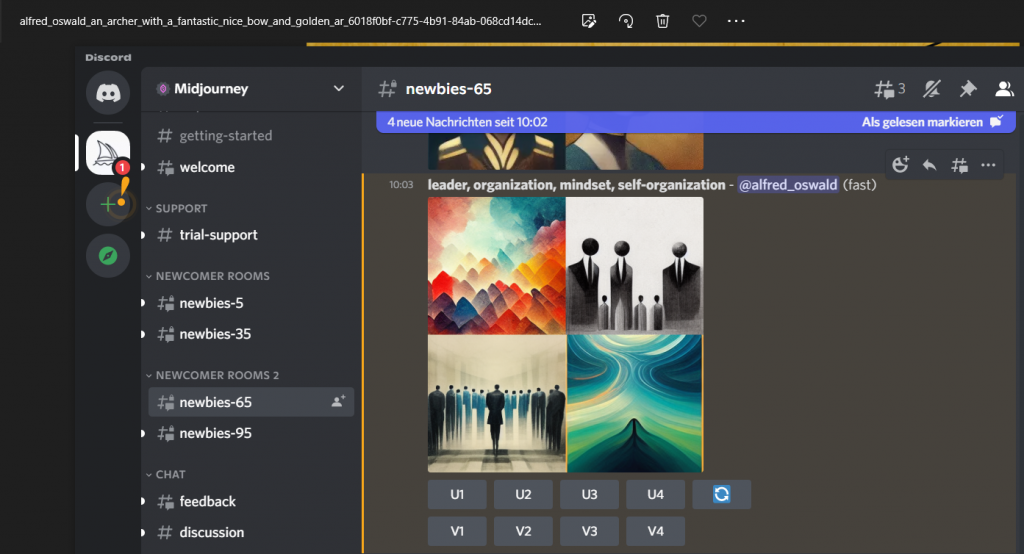
Anschließend habe ich nach Ideen zur mathematischen Modellierung des Collective Mind gefragt – Man siehe Abbildung 2. Das Ergebnis ist auch verblüffend, denn ein Teil der Lösungsvorschläge habe ich schon in den vergangenen Blog-Beiträgen vorgestellt. Hier weiß man nicht, ob chatGPT diese kennt, oder davon unabhängige Vorschläge gemacht hat. – Ich merke schon hier an, dass diese Ergebnisse viel besser sind als diejenigen von GPT-3: GPT-3 war in seiner Antwort eher nichtssagend!

Ich habe chatGPT auch gebeten, ein Netlogo-Programm mit folgendem Prompt zu erstellen: Please create a netlogo ABM model using the Big Five Model. The goal is to show that teams with a good collection of team members build a Collective Mind which shows synergy in the team performance.
Entsprechend habe ich um ein MESA-Python Programm gebeten. Abbildung 3 zeigt einen Ausschnitt dieser Antwort:
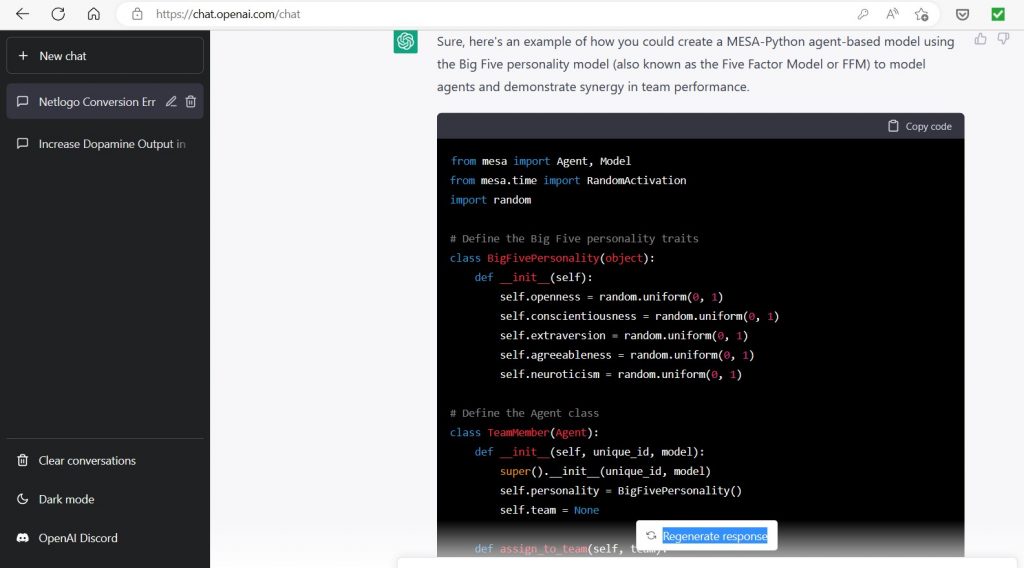
Beide Programme, Netlogo und MESA-Python, sind syntaktisch fehlerfrei, erzeugen aber Laufzeitfehler. Da ich die Python Programmierung der Netlogo Programmierung vorziehe, habe ich im Folgenden versucht das MESA-Python Programm zum Laufen zu bringen. Es ist mir, aufgrund meiner bescheidenen MESA-Python Kenntnisse, nicht gelungen. chatGPT war bei der Fehlersuche und -behebung nicht hilfreich.
Aber das Ergebnis ist trotzdem sehr erstaunlich: Die Teammitglieder eines Teams und das Team selbst wurden als Agenten modelliert. Für das Team wurde ein Collective Mind berechnet. chatGPT hat die Synergie des Collective Mind so interpretiert, dass der Collective Mind ein 5-dimensionaler Vektor aus der Summe der Big Five Persönlichkeitsdimensionen aller Teammitglieder ist. Die Teamperformance ergibt sich aus der Summe der fünf Dimensionen, wobei die Dimension Neurotizismus (entspricht grob einem Maß für emotionale Labilität) mit einem negativen Vorzeichen versehen wurde, also abgezogen wurde. – Meines Erachtens eine beachtliche Leistung!
Die Logik des Netlogo Codes und des MESA-Python Codes ist gleich!
Die intensiviere Beschäftigung mit MESA-Python zeigte auch, dass das Skelett des erzeugten Codes aus dem MESA-Python Tutorial stammt. Hierbei ist ein entscheidender Design-Fehler geschehen: Die Teammitglieder und die Teams wurden als Agenten programmiert, was im Prinzip nicht verkehrt ist, jedoch zur Laufzeit in dieser einfachen Implementierung zu Eindeutigkeits-Problemen führt.
Ich wollte kurze Zeit später den Prompt etwas erweitern und konkretisieren. ChatGPT hat sich zu diesem Zeitpunkt jedoch geweigert Code zu erzeugen. Stattdessen bot chatGPT eine gute Programmier-Vorgehensweise an. ChatGPT begründet dies damit, dass die Codeerzeugung zu viele spezielle Kenntnisse erfordern würde. Erstaunlich dieser Sinneswandel!
Ich überprüfte daraufhin eine andere erstaunliche Antwort, die ich kurz nach der Freischaltung von chatGPT erhalten habe: Ich fragte nämlich nach den Unterschieden von chatGPT und GPT-3: U.a. wurde mir damals mitgeteilt, dass GPT-3 über 175 Milliarden Parameter verfügt und chatGPT über 1.5 Milliarden Parameter. Dies ist eine sehr erstaunliche Aussage, da chatGPT hiernach über 100-mal weniger Parameter verfügt. Falls dies korrekt ist, wäre dies meines Erachtens eine sensationelle Aussage zur Leistungsfähigkeit von chatGPT. Also habe ich zu dem späteren Zeitpunkt nochmals nach dem Unterschied von chatGPT und GPT-3 und insbesondere nach der Anzahl der Parameter gefragt: ChatGPT verweigerte die Aussage, da es keine offiziellen Aussagen von openai hierzu gibt.
Es wird also im Hintergrund heftig an den Aussagen von chatGPT filternd gearbeitet.
Ich wechselte zu GPT-3 [20]: GPT-3 interpretierte die Synergie des Collective Mind und die daraus resultierende Teamperformance fast exakt wie chatGPT. -Jedoch wurde der Neurotizismus nicht abgezogen, sondern addiert. Das erstellte Programm ist syntaktisch korrekt und sogar nach der Behebung von zwei kleinen Fehlern im Aufruf der MESA-Python Objektstruktur sogar lauffähig. Der entscheidende Unterschied warum der GPT-3 Code lauffähig ist, ist dass GPT-3 sich an die Struktur von MESA-Python gehalten hat. Das räumliche Umfeld der Agenten, in der MESA-Python Sprache, the model, wird wie bei Netlogo auch, standardmäßig als Schachbrett modelliert und die Agenten bewegen sich wie Schachfiguren in dieser 2D-Welt. Jeder Agent hat dann bis zu 8 Teammitglieder, da auf einem Schachbrett jedes Quadrat acht Nachbar-Quadrate hat. – Es wird also kein Team eingeführt, das als Agent behandelt wird, sondern die jeweiligen Nachbarn definieren das Team. In dieser einfachen Welt sind die Teams dynamisch, da sich die Agenten auf dem Schachbrett in Zeitschritten bewegen. Alles in Allem eine erstaunliche GPT-3 Leistung!
Jedoch lässt sich diese Leistung leider nicht reproduzieren: Zum Zeitpunkt des Schreibens dieses Artikels (10.02.2023) verweigert GPT-3 zwar nicht die Code-Generierung, jedoch bricht die Erzeugung kurz nach Beginn ab und der Code ist schon zu Beginn leider mehr oder weniger unsinnig. – Die Qualität der ersten Generierung ist verschwunden!
Soweit, so gut – Fortsetzung folgt, wahrscheinlich 😉.
[1] Wikipedia (2023), Agent-based_model, https://en.wikipedia.org/wiki/Agent-based_model, zugegriffen am 05.02.2023
[2] Russell S, Norvig P (2016) Artificial Intelligence, A Modern Approach, Third Edition, Pearson Education Limited, Essex
[3] Wikipedia (2023) Data assimilation, https://en.wikipedia.org/wiki/Data_assimilation, zugegriffen am 06.02.2023
[4] Graepel T (2023) The role of Multi-Agent Learning in Artificial Intelligence Research at DeepMind, https://www.youtube.com/watch?v=CvL-KV3IBcM&t=619s, zugegriffen am 06.02.2023
[5] Deepmind (2023) Melting Pot: an evaluation suite for multi-agent reinforcement learning, https://www.deepmind.com/blog/melting-pot-an-evaluation-suite-for-multi-agent-reinforcement-learning, zugegriffen am 06.02.2023
[6] Melting Pot (2022) https://www.youtube.com/watch?v=tfFSpyzYiYY, zugegriffen 04.12.2022
[7] Medium ODSC (2023) Melting Pot and the Reverse-Engineering Approach to Multi-Agent Artificial General Intelligence, https://odsc.medium.com/melting-pot-and-the-reverse-engineering-approach-to-multi-agent-artificial-general-intelligence-cf8c6da88304, zugegriffen am 06.02.2023
[8] Oswald Y, Malleson N, Suchak K (2023) An agent-based model of the 2020 international policy diffusion in response to the COVID-19 pandemic with particle filter, Universität Leeds, https://arxiv.org/abs/2302.11277
[9] Netlogo (2023) https://ccl.northwestern.edu/netlogo/index.shtml, zugegriffen am 06.02.2023
[10] Masad D, Kazil J (2015) Mesa: An Agent-Based Modeling Framework, PROC. OF THE 14th PYTHON IN SCIENCE CONF. (SCIPY 2015)
[11] MESA (2022) Python based ABM, https://mesa.readthedocs.io/en/stable/index.html
[12] Github (2023) Mesa Code, https://github.com/projectmesa/mesa, zugegriffen am 06.02.2023
[13] Ng Wai Foong (2022) Introduction to Mesa: Agent-based Modeling in Python, https://towardsdatascience.com/introduction-to-mesa-agent-based-modeling-in-python-bcb0596e1c9a
[14] Long Ngo (2022) Agent-based modeling in Python with Mesa, https://www.youtube.com/watch?v=Hg7bwOtGVDE
[15] Karami B (2023) Intro to Agent Based Modeling, https://towardsdatascience.com/intro-to-agent-based-modeling-3eea6a070b72, zugegriffen am 06.02.2023
[16] Santa Fe Institute (2023) Complexity Explorer, https://www.complexityexplorer.org/courses, zugegriffen am 06.02.2023
[17] Howard P J, Mitchell Howard J (2008) Führen mit dem Big-Five-Persönlichkeitsmodell, Das Instrument für optimale Zusammenarbeit, Campus Verlag und Handelsblatt
[18] A. Oswald (2020) The whole – more than the sum of its parts! – Self-organization – the universal principle!, IPMA Research Conference, Springer, in Ding R, Wagner R, Bodea CN (editors) Research on Project, Programme and Portfolio Management – Projects as an Arena for Self-Organizing, Lecture Notes in Management and Industrial Engineering, Springer
[19] chatGPT (2023) openai.com, zugegriffen am 19.01.2023
[20] GPT-3 (2023) openai.com, zugegriffen am 19.01.2023